How many of your supposedly internal-only backends are serving critical end-user traffic? Probably more than you think! Most frontend services have many transitive dependencies, and understanding these dependencies becomes increasingly difficult as your system grows in scale and complexity. As a result, it becomes exceptionally tricky to ensure that internal-only backends are fully isolated from end users.
Google uses a common infrastructure platform for almost all of its services, internal and external; this provides for a message-passing mechanism common to all of these services. This also means that logging and tracing information can follow requests as they pass through various layers of the system; read more in this paper on Dapper, Google’s large-scale distributed-tracing system. The tools that accompany the common infrastructure offer opportunities to dig into complex problems with dependency analysis that might otherwise be intractable. One outcome is that systems engineers can build accurate dependency maps of services; and that we can ensure new services only depend on other services at the same level or higher in the dependency stack. Another approach to dependency analysis provides a structure that identifies business risks due to critical dependencies between systems. In this article we will describe our hunt for risky dependencies, and suggest how similar techniques might benefit your systems.
Risky dependencies (in this case, dependencies which place internal-only backends on the critical path for end users) can be a source of major serving outages, because the internal-only backends do not generally have necessary reliability or safety guarantees. For example, you might have an externally-visible service that requires high levels of availability and performance, and this system has an indirect dependency on a backend with no availability or performance SLOs.
At Google, we found success preventing major and huge outages by clustering services into categories with distinct properties, clear perimeters, and limited blast surfaces. The properties will depend on the guarantees we want to enforce. In this article, we use Google Maps to demonstrate how risky dependencies proliferate in complex systems, and then showcase how clustering Google Maps services into just two categories ("Internal" and "External") can prevent major and huge serving outages. We also outline how OpenTelemetry is used to identify violations of this clustering, which can be fixed before the violations cause a major serving outage.
Case Study: Google Maps
Under the hood, thousands of different components are required to serve the Google Maps product. In fact, the majority of its infrastructure powers all the preliminary steps of serving a map, like ingestion, curation, and storage of all of the data that is served to end users.
To briefly illustrate how data flows across the pieces of Google Maps infrastructure, we introduce two characters: Alice the business owner, and Bob, the Google Maps user. One morning, Alice updates the URL to her small business. She does this by going to Google Business Profile (GBP).
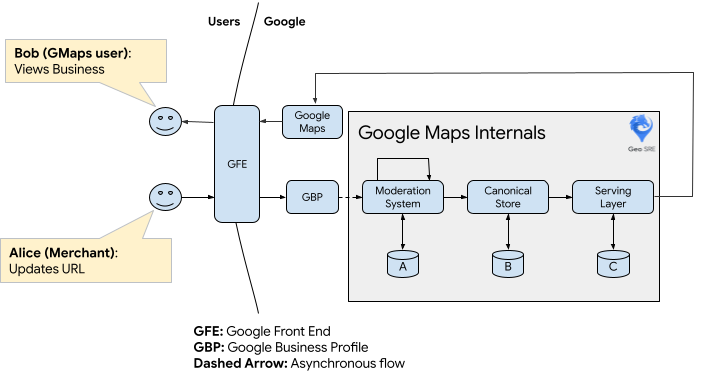
Alice's data is ingested by the GBP API, and then gets queued up for moderation. Later on, this data will pass through moderation, and then be curated / stored within the Canonical Store. This layer is optimized to be Google Maps' source-of-truth: it can maintain a high write throughput, and its replicas are geographically close so as to reduce the time to propagate data from leader to replicas.
The Canonical Store then broadcasts this update to the various serving systems, which were designed for high read throughput. Our serving layers have replicas spread across the globe. Only at this point is the updated URL available to users like Bob.
Note that the above diagram represents a simplification of a subset of the entire system that powers Google Maps, and much of the system complexity is omitted for clarity. A, B, and C represent the various datastores for each of the components.
Internal vs. External Services
Within Google Maps, a component should only be externally visible if it satisfies two criteria: if it serves data, the data must be curated for end users, and it must meet sufficient standards of reliability. By design, neither the moderation system nor the canonical store satisfy these criteria. These systems were optimized for functions other than high throughput serving, and handle data that is not yet ready to be served.
In general, we found that the following questions were good heuristics for determining whether a service should be allowed to be externally visible:
Is the returned data suitable for end users?
Is the service owner aware of the externally visible flows that depend on this service?
Are the externally visible flows considered when the service owner develops this service?
Does the service owner monitor the reliability of the externally visible flows during rollouts?
Are the service’s as-defined SLOs adequate to support externally visible flows?
If the answer to one or more of these questions is "No", then it is a good candidate to isolate the service from end users.
When we ensure that these components are fully isolated from end users, we can achieve reliability and increase the operational efficiency of the user-facing elements of our architecture. Firstly, it is less operationally expensive to maintain our serving layer because there are fewer services on the critical path. Secondly, the isolated services can be iterated upon with higher velocity because outages won't directly impact end users.
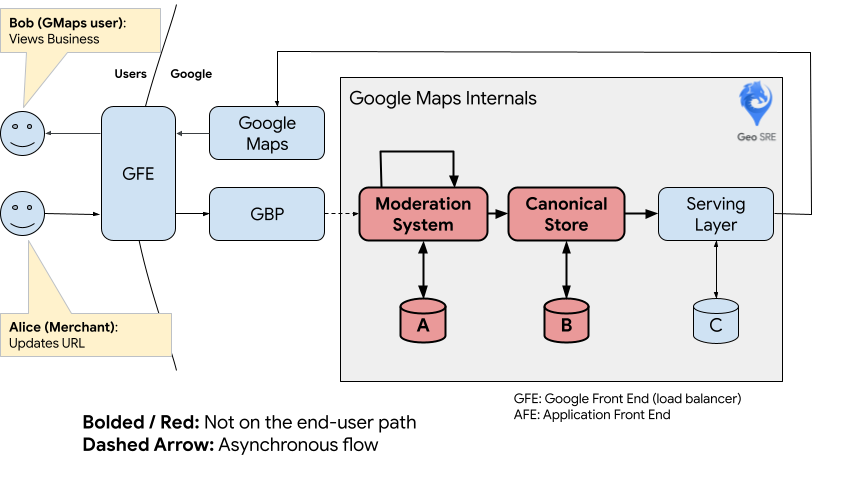
Within Google Maps, both the moderation system and the canonical store were designed to be isolated from end users. Due to this, the owners of these two components feel confident to iterate and experiment without fear of causing a major serving outage.
Risky Dependencies
What Are Risky Dependencies?
Broadly, a risky dependency is ultimately just a dependency that crosses the boundary of two failure domains. In this article, we group all of our services under two domains, the "external" vs. the "internal" ones. Using this framework, we consider a dependency to be risky whenever a service is critical for end-user traffic, but it depends on a backend service that is not meant to be on that critical path. This is best exemplified by looking at specific risky dependencies within Google Maps.
At the beginning of 2022, we discovered a risky dependency between Google Pay (GPay) and Google Maps. GPay has a Transaction History Page that shows users their recent purchases. Whenever a user looks at a specific transaction, GPay fetches merchant information (e.g., the name, physical location, and the website) from some internal API provided by Google Maps. GPay is an important product to Google, has high reliability standards, and is used by many people around the world. With that in mind, what reliability characteristics do you think the backend API should have? A few ideas would be:
Many 9s of reliability
Sufficiently low latency across the globe
Availability wherever the service operates
Data that is consistent and suitable for end users
However, we discovered that GPay's Transaction History Page actually depended on the Canonical Store, which was not meant to serve end users!
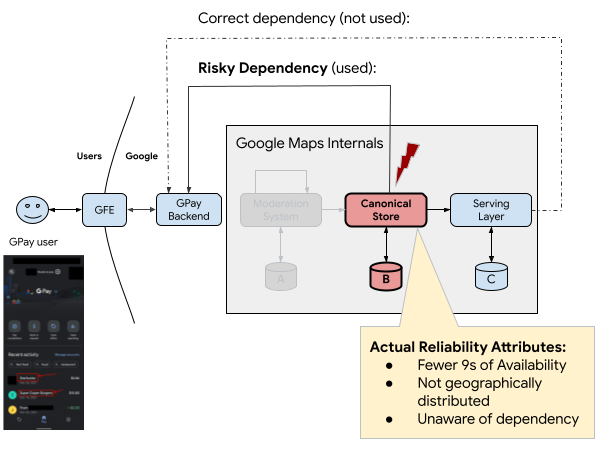
As we described in the background section, the Canonical Store has none of the requisite attributes for a reliable serving backend. What is even more surprising is that the owners of the Canonical Store were not even aware that GPay end users depended on them for end-user traffic. This dependency is clearly risky; GPay is at a much higher risk of having a major serving outage because it depends on a backend which was meant to be isolated from end users.
Risky Dependencies Cause Major Outages
A Google-wide effort identifies business risks that risky dependencies present to certain systems. Business risk includes jeopardizing SLOs, with fewer 9s of availability resulting in a customer-facing outage.
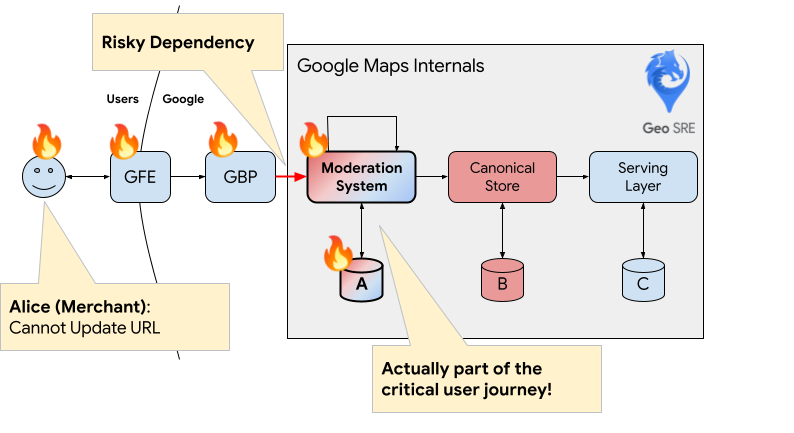
Within Google Maps, risky dependencies have also been responsible for major serving outages impacting end users. Several years ago, one of the datastores of the moderation system started experiencing thread contentions. These thread contentions caused an increase in DEADLINE_EXCEEDED errors within the moderation system itself. (DEADLINE_EXCEEDED errors occur when a service has not responded during a pre-defined timeout.)
This moderation system was designed to be isolated from end users via some queuing mechanism. (A user's proposed changes to the map are stored in some queue before they are moderated at a later time. The moderation system should not be on the critical path for end-users.) Therefore, we expected that the impact of the DEADLINE_EXCEEDED errors would be limited to only Google systems and internal users. However, due to these errors, 1% of merchants were unable to edit their listings, and 12% of merchants were unable to even create a new listing in GBP. We thought that the moderation system was not part of a critical user journey, but somehow it was (the queuing mechanism used the same database as the offline moderation system). GBP had a risky dependency on the moderation system, and it caused a major serving outage!
Why Do Risky Dependencies Proliferate in Complex Systems?
Risky dependencies exist seemingly everywhere we look. It all starts with the fact that large systems are inherently complex, facing two fundamental challenges. One challenge is an architectural one; microservice architectures quickly become unwieldy, with potentially hundreds of nodes. (Note that monoliths often exhibit the same problem, except in those cases, the complexity is within the call graph of functions rather than the call graph of RPC calls.) Call stacks can be ten or more nodes deep, and nodes can be highly interconnected. Typically, service owners have a narrow and deep view of the overall system, so they are only familiar with their clients, and their direct backends.
The other challenge is an organizational one. Communication across the organization is very difficult, especially if user journeys cross product boundaries. Compound all of this with the fact that some percentage of these services may be legacy or in maintenance-only mode. Therefore, service owners have a hard time keeping up with changes across the stack, and system-level views are scarce and outdated. In some cases, developers don't consider service boundaries while developing; in other cases, services evolve over time even as stronger infrastructure is developed. Both circumstances lead to the existence of risky dependencies. Because of technical complexity and organizational challenges, we are left with an imperfect view of production. This is the perfect storm that allows risky dependencies to proliferate.
This imperfect view of production happens organically, especially when there is no intentional action around dependency management. At Google and elsewhere, organizations manage dependencies with robust service registries, but achieving a full coverage of services can be a multi-year process; and in that time, service dependencies may grow around or in spite of these efforts.
Finding Risky Dependencies
Unfortunately, risky dependencies typically exist in production unnoticed until one of them causes a major serving outage. If we could build a tool that analyzes all of the dependencies on the critical path, and identifies which of them are risky, then we would be able to fix them before they cause a major serving outage.
In Theory
Identifying a risky dependency is, in theory, relatively simple: Of all of the services that should be isolated from end users, which of them are actually on the critical path?
We can achieve this by executing the following steps (we assume that the universe of services is knowable):
Identify all of the services that are on the critical path for end users.
Identify all of the services which are not designed to be on the critical path for end users.
Take the intersection of both sets. This intersection is the set of internal backends that are actually on the critical path.
Identify which dependencies would need to be removed to ensure none of the internal services are on the critical path.

In Practice: OpenTelemetry
OpenTelemetry is an observability framework that manages telemetry data across the entire server stack. It collects traces, metrics, and logs from all of our microservices. One particular piece of metadata, called Baggage, is propagated between microservices in a call stack. With some setup, we can use Baggage to help identify all of the services that are on the critical path! (Note that Baggage may not propagate to critical backends for several reasons. At Google, the two most frequent cases are: when RPCs are sent a threadpool rather than the request thread, and when RPCs are sent via a critical, but asynchronous dependency; i.e., spanner queues or Pub/Sub.)
Specifically, we can create and then propagate the "originator" tag, which represents the first service in the call stack. When an RPC call stack originates from an end user, then the value of the "originator" tag would be whatever public frontend your company uses. At Google, this would be our Google Frontends (GFE). In all other cases, the originator tag would be the service that spawned the first RPC in the call stack. If we pair this data with two other pieces of information: "The immediate caller of this RPC", and "The service that received this RPC", then we can actually determine which services are on the critical path for end users.
If we store and aggregate the metadata from every RPC in a data lake, and then filter by only the external originators (e.g., GFE), then we are left with the set of dependencies that are on the critical path for end users.
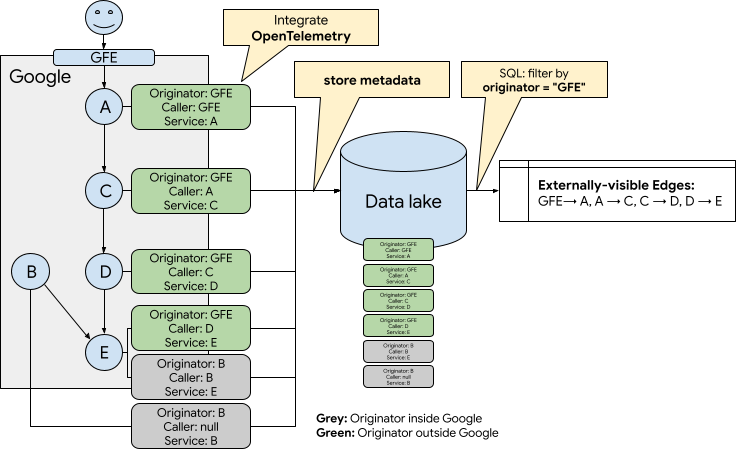
We can then manually annotate the intent of each service that is on the critical path by revisiting the previously defined set of questions:
Is the returned data suitable for end users?
Is the service owner aware of the externally visible flows that depend on this service?
Are the externally visible flows considered when the service owner develops this service?
Does the service owner monitor the reliability of the externally visible flows during rollouts?
Are the service’s as-defined SLOs adequate to support externally visible flows?
If the answer to all of these questions is "yes", then the service is most likely to be intentionally on the critical path. Otherwise, it should not be on the critical path.
We can take the list of services that intend to be isolated from end users, and further filter the list of dependencies to just the set of critical dependencies that are on these services. This represents the list of risky dependencies.
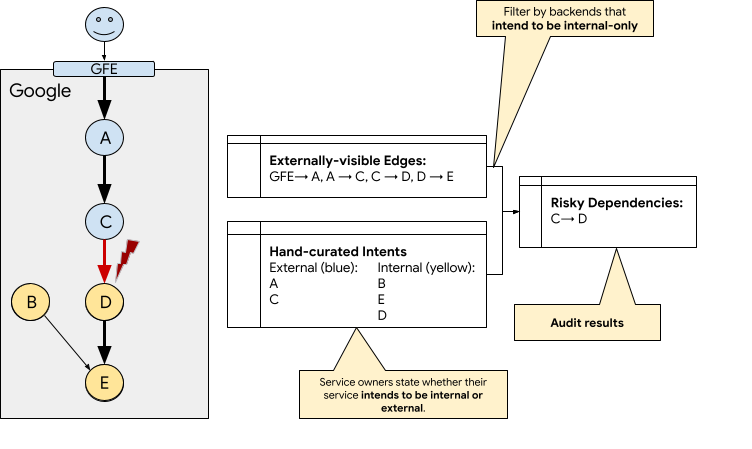
In this diagram, dependency C→D is risky, and should be fixed to prevent a major serving outage. By contrast, the dependency B→E is not risky, because the call stack originated from within Google. Dependency D→E is not risky either, because the dependency is between two internal nodes.
Fixing Risky Dependencies
Automatic identification of risky dependencies is only the first half of this puzzle. To prevent risky dependencies from causing a major serving outage, you need to actually remove the risky dependencies. In our experience, there are three ways to mitigate risky dependencies: migrate the frontend service to a more suitable backend, make the dependency optional for end users, or deprecate the dependency entirely.
Soon after the discovery of GPay's critical dependency on the Canonical Store, we were able to migrate their RPC calls to the Serving Layer (the externally visible service). Because of our investigations, we discovered that about 30 services across Search, Ads, and Commerce all depended on internal-only backends within Google Maps. We were able to migrate the majority of these risky dependencies or make them optional.
Managing Risky Dependencies
A significant factor in the origin of risky dependencies comes from the proliferation of microservices, where large, monolithic binaries evolve into a larger ecosystem of software. A company-wide effort at Google aims to design systems of software for human reasoning, by arranging microservices intentionally. These arrangements provide “failure domains”, groups of microservices with clearly-defined boundaries. Some similar efforts at other SRE organizations refer to this as “limiting the blast radius”. Within these failure domains, one can still create dependency cycles — yet these paths are now made explicit. Furthermore, a separate, low-dependency failure domain prohibiting cycles also exists. This provides a clear bootstrapping path for the overall system. Earlier we alluded to a “stack” of dependencies: this notion provides one way to conceptualize ordered dependencies. Other visual metaphors might include concentric rings — again, a “blast radius”, with the low-dependency failure domain at the center.
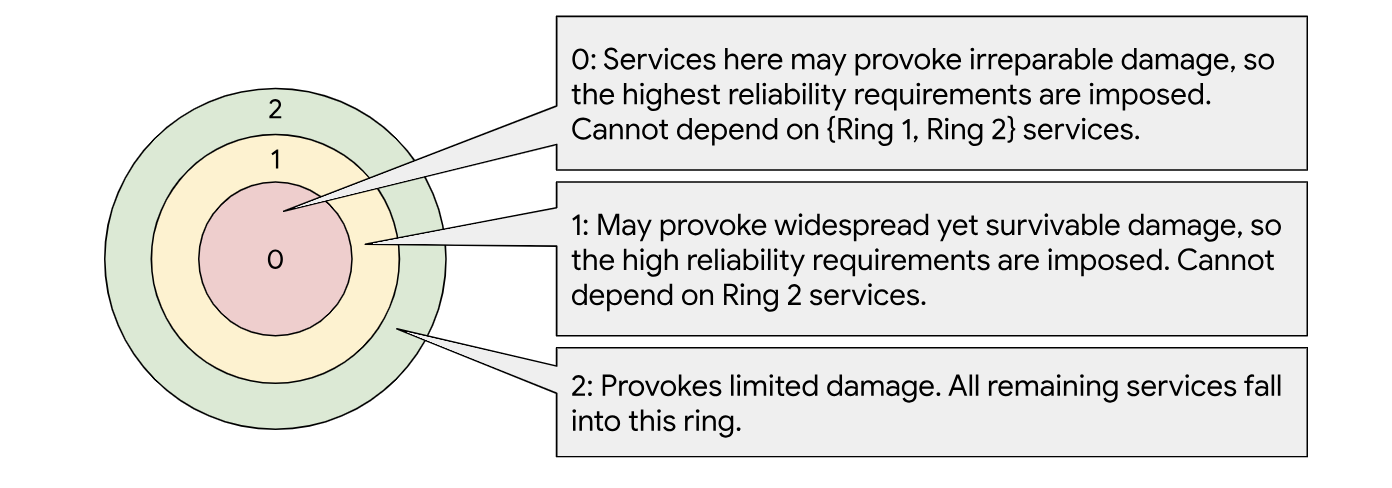
In this article, we chose to partition our system into two failure domains: "services that must not be on the critical path for end users (internal-only)", and "services that are allowed to be on the critical serving path for end users (externally visible)". However, it's possible to define other failure domains to manage additional security, reliability, and performance guarantees. Using this broader definition, a risky dependency is ultimately just a dependency that crosses the boundary of two failure domains.
Conclusion
With software-development processes that focus on building dependency-aware services, and unified software platforms, Google's infrastructure-level efforts help enforce the separation of failure domains. However, enforcing this becomes increasingly difficult as the number of services and connections increases, so risky dependencies tend to proliferate. We can use a horizontal and scalable monitoring tool like OpenTelemetry to find these risky dependencies, and then fix them by applying engineering skills. At the end of all of this, we are able to fix the risky dependencies before they cause major serving outages, thereby improving the reliability of our serving layer.
Some services that you manage should not be on the critical path for end users. Start thinking about which services should be isolated from the end-user path, and think about the benefits you will reap when you ensure that they are fully isolated.

