As with most large-scale migration efforts, the later stages of Alphabet's BeyondCorp migration required disproportionate effort. After successfully transitioning most of Google's workflows to BeyondCorp, we were left with a long tail of specific or challenging situations to resolve. This article examines how we created processes, tools, and solutions to handle use cases that were not easily adapted to our core HTTPS-based workflow.
This article continues Alphabet's BeyondCorp story by addressing the long tail of difficult use cases, where gaps in tooling, available data, management buy-in, or specialized technical knowledge historically prevented users from migrating to a zero-trust model.
We discuss how we managed security exceptions left over from the previous migration processes, the evolution of the solutions applied, and how—through a combination of change management, security, and program management practices—we were able to move Alphabet employees away from a privileged internal network. Throughout the article, we provide lessons learned to help others address the long tail of a migration to a BeyondCorp-style architecture.
A previous article in the BeyondCorp series covered how we migrated Alphabet from using a privileged, legacy network (internally known as Managed Privileged Client, or MPC) to the MNP (Managed Non-Privileged) network as the default. Migrating to BeyondCorp: Maintaining Productivity While Improving Security covered the processes, tooling, and solutions used for the majority of use cases, and especially those that rely solely on HTTPS traffic.
As the migration to an MNP-by-default model progressed at Google, it became clear that certain classes of applications were incompatible with the existing available solutions. In particular, applications were incompatible with the BeyondCorp access proxy described earlier in this series. This problem included third-party applications that had one of the following characteristics:
While HTTPS-based, could not be easily configured to present a machine certificate to a proxy.
Required IP-layer connectivity to a variety of backends using non-HTTPS protocols.
Explicitly required IP-based client allowlists to function.
In some cases, although they had a considerable number of users, these applications were officially unsupported internally and only "accidentally worked" seamlessly due to the overly-broad access granted by MPC.
Even for well-behaved applications and protocols, the BeyondCorp model implemented via access proxies posed challenges to teams with strict bandwidth or latency requirements. Traversing a proxy can degrade performance compared to direct access to a local server, especially if that proxy is not physically close to the user. For relatively small and niche use cases, it may not be practical to deploy proxies as widely as the main HTTPS BeyondCorp proxy.
Many of these problematic workflows were identified through the MNP simulation described previously, and the relevant users were granted exceptions to stay on the MPC network temporarily until we identified a solution. These workflows often underpinned critical parts of Alphabet's business, such as financial operations or physical security, and became known as the 'long tail' of BeyondCorp.
Lessons learned:
When ambient privilege exists, expect systems and users to become dependent on it.
The long tail of BeyondCorp adoption can easily span many distributed organizations, such that no single management chain or executive can drive it to completion alone.
Manual approval of individuals' exceptions is infeasible for Alphabet's very large employee population. Therefore, we created an exception system to allow full-time employees to self-grant an MPC exception from a defined set of known incompatible workflows, and temporary workers or vendors to request that exception via their manager.
We also continued to allow support teams to request the creation of new exception groups for their users as certain new workflows were introduced, again adding to the complexity of the long tail.
Separately from that system, a small but highly important set of workflows were also granted network-level exceptions. That is, certain privileged flows were allowed even on the non-privileged network, regardless of the user initiating the flow. This class of exceptions, known as “MNP holes”, was necessary for:
Printers: Direct access from corporate devices to printers.
SSH: Direct SSH access across corporate networks, motivated by cases that depended on high bandwidth.
Emergency IRC access: Direct access from corporate devices to IRC servers used for emergency communications by SRE.
Although they allowed business continuity, these exceptions also lasted much longer than initially anticipated. Because of their widespread usage, they were also often difficult to associate to a single executive-level sponsoring owner.
After the success of the initial MNP rollout, management support for migrating workflows and users to BeyondCorp waned, and development of long tail solutions went underfunded. The data analysis pipeline we used to discover workflows was turned down.
As a result, the long tail persisted as a growing population of users, segregated into coarse groups with sizes ranging from dozens to thousands of users, whose needs became increasingly opaque to the BeyondCorp team.
Lessons learned:
An exception system ensures business continuity while migrating difficult cases to a new system.
Exceptions should, at a minimum, expire and require renewal. If the necessary network logs are available, exceptions can also automatically expire if unused.
A support team for each exception must exist. To mitigate the risk of users acquiring unnecessary exceptions, the user's eligibility for an exception should be controlled by another process owned by the support team.
Controlling and ultimately removing overly broad security exceptions requires investment in Security Engineering, support, change management, SRE, and program management. The "wait it out" strategy (hoping teams update or change their infrastructure) won't create full-scale change.
As teams migrated away from the privileged network, they generally moved their workflows or infrastructure to depend on one of the main internal BeyondCorp solutions.
The BeyondCorp proxy remains the primary internal solution for HTTPS traffic originating from a browser. Non-browser HTTPS clients are configured to use a forward proxy that injects user and machine credentials into requests for compatibility with the BeyondCorp proxy. This forward proxy is internally developed and runs on the client side, listening on localhost.
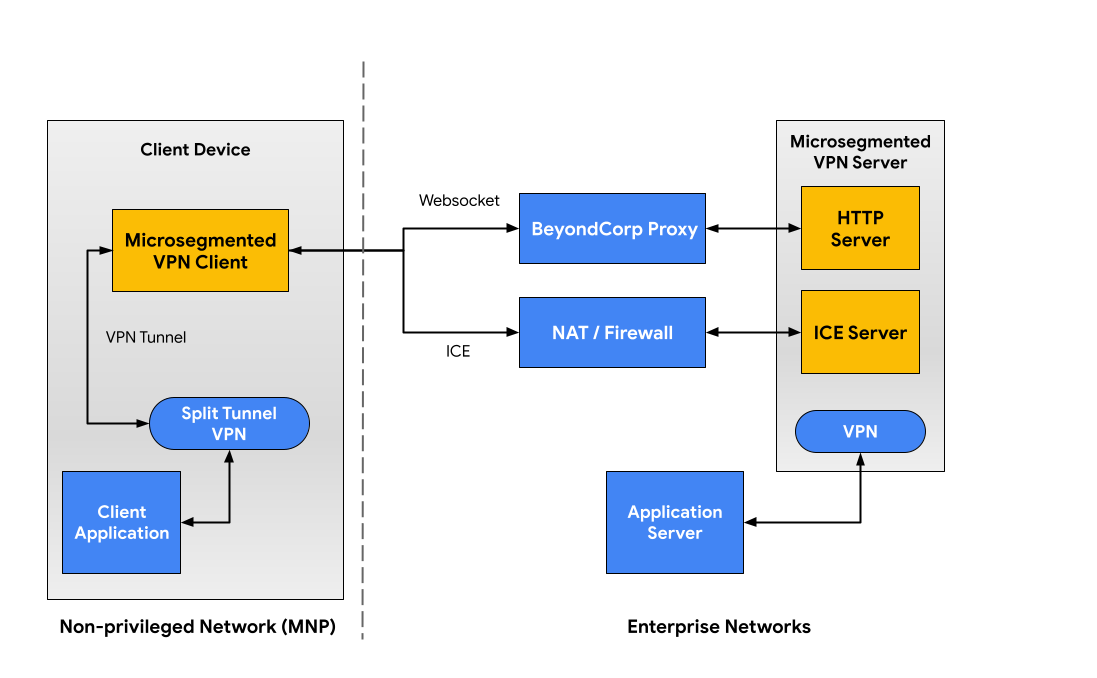
We also developed a microsegmented VPN solution to serve as a catch-all option for tools requiring arbitrary IP connectivity across networks. It works similarly to a traditional VPN, with added support for endpoints that cannot run arbitrary applications (typically embedded systems). It's also integrated with existing BeyondCorp access decision mechanisms for authorization. Importantly, it contrasts with VPN by providing fine-grained network access to only a set of pre-configured backends per user.
As shown in Figure 1, the microsegmented VPN supports two methods for transporting application data:
Interactive Connectivity Establishment (ICE) sessions established through the corporate firewall for high throughput.
Websocket through the BeyondCorp proxy for improved connection stability.
In addition to the "pure" BeyondCorp solutions above, we also employed an important "compromise" solution: the existing internal VPN service.
During the period of office closures due to the COVID-19 pandemic, we didn't quite know how to support the non-BeyondCorp workflows, as the privileged network by definition only exists in the office. In certain cases employees were still able to remotely access a workstation in the office to get their work done, but in other cases, there were simply no suitable short-term hardware options.
In this context, VPN stood out to many teams as a relatively familiar, mature, and globally available service that allowed users to work from home while retaining IP-based privilege, even though we could not rely upon it as a long-term solution. Throughout 2020 and 2021, many support teams worked with Security to ensure company VPN policies were suitable for their workflows. By shifting these MPC use cases to VPN, we were able to revoke users' MPC access provided they continued to use VPN while in the office.
As shown in Figure 2, VPN is not an optimal BeyondCorp-compatible solution as it does not remove network-based trust. Although it is employed for certain specialized use cases, those remaining use cases will be migrated to different options.
However, VPN provides three critical advantages over a privileged network:
Coarse-grained control over the policies for allowed traffic, with known owners for each necessary flow.
A clear migration path to a microsegmented solution.
Removal of ambient network privilege even for workflows with unclear permanent solutions, which prevents new dependencies on that privilege from appearing over time.

Finally, we closed the pre-existing MNP holes described in the previous section using the following solutions:
Printers: Migrating printing workflows to a third-party, Cloud-hosted solution that works over HTTPS.
SSH: Migrating users to an internally developed BeyondCorp SSH proxy.
Emergency IRC access: Migrating IRC servers to Google's production infrastructure, accessible through the BeyondCorp proxy from trusted machines only, but taking care to maintain compatibility with known disaster recovery scenarios and strategies.
Lessons learned:
No single solution is applicable in every case, and simpler, special-purpose solutions for common cases can mitigate the operational load of BeyondCorp and provide a better user experience. Choose the most appropriate solution for major workflows, rather than a single catch-all option.
Be pragmatic and prepared to migrate to intermediate solutions with a clear path forward, or make trade-offs among different policies to ensure business continuity.
We started the migration process for each use case once we identified one of the above solutions as appropriate. Our overarching goal was to revoke the MPC exceptions of a population of users and to direct them to the candidate solution, which potentially required a change to their workflow.
The candidate solution we proposed depended on:
The scale and coherence of the target user population.
The degree of collaboration with support groups and subject matter experts thus far.
The depth of user testing performed to validate the solution.
During any migration, it is important to account for the possibility that the candidate solution will be unsuitable for some fraction of users (for example, due to location-dependent latency). Additionally, you might uncover new incompatible workflows needed by the same users during migration, which can surprise the teams supporting those applications or tools.
To mitigate those risks, we created and automated a standard migration process that incorporates change management best practices, including:
Communications to individual users in advance, with a clear migration date.
User documentation with a clear description of the solution, a FAQ, and links to documentation for previous migrations.
Gradual rollout over multiple days.
A self-service, temporary opt-out mechanism with a clearly communicated expiration date that requires additional information on the workflow and (if possible) a contact for a support team or subject matter expert.
By using opt-outs as an opportunity to gather information, we were able to identify internal support groups we could work with to address the 'long tail of the long tail'.
Lessons learned:
Formalize acceptance testing with help from support teams and subject matter experts.
Follow change management best practices, such as gradual rollout, broad communications with clear timelines and an FAQ, and temporary self-service remediation.
Leverage opt-outs to identify support points of contact and new incompatible workflows.
Overall, the task of removing the long tail of BeyondCorp can be broken down into the following steps:
Identify the support team or subject matter experts that formally support populations of users with exception requests.
Work with the support team to understand the workflows of those users. Propose and validate a solution.
Migrate the users to the solution using the standard process.
Triage opt-outs to uncover new workflows and subject matter experts to engage with.
You can execute the above steps independently for any one combination of support team and user population, in what we called an engagement (see Figure 3). To execute engagements, we assembled a team of Security Engineers, first-level support and change management specialists, SREs for the relevant solutions, and program managers.

Staffing and time constraints meant that not every user population was eligible for engagement with the BeyondCorp team. For small populations, we made best-effort attempts to locate experts on the workflows and communicate deadlines months in advance. Those individuals and teams could book office hours slots for quick consultations.
To further raise awareness for the program, we leveraged an existing network of Director and VP-level Security Champions spread across Alphabet leadership. We also provided monthly status reports, including notifications of upcoming migrations, to an open internal mailing list, which we initially populated with our engagement points of contact.
Importantly, we consistently provided clear deadlines for support teams to migrate their users' workflows off the privileged network months in advance. We also provided a standardized escalation process to allow those teams and their management chains to surface competing priorities.
Support teams successfully used the escalation process to extend their timeline as necessary. Sizable groups of users whose workflows were not formally supported used the escalation process to find a team that would claim ownership of the necessary migration and support work.
Lessons learned:
- Work with existing support teams and experts, and empower them to experiment with and test the zero-trust model before rolling it out to their users.
- Communicate clear deadlines and provide a standardized escalation process that rolls up to the project sponsor.
- When no formal support exists for a population of users, have mechanisms to draw executive attention and resources to either support the work or end the workflow.
- Standardize and operationalize the common parts of the problem (project management and migration), and offer those as a service to support teams who may not have that expertise.
Alphabet's internal BeyondCorp story will continue as we work on transitioning the remaining VPN use cases to more suitable access solutions. The evolution of the BeyondCorp Enterprise platform also opens important convergence opportunities that will allow us to phase out internal solutions and move towards more standardization.
As organizations adopt BeyondCorp principles, they inevitably come across seemingly incompatible workloads that require careful trade-offs between security, reliability, user experience, and other factors. We hope that the pragmatic and multidisciplinary approach described here, along with the outlined solutions, will help readers structure their migration to BeyondCorp and inform their own trade-offs.
Finally, we recognize the value of application-layer (preferably HTTP-based) applications from a security standpoint, as they facilitate proxying and traffic inspection. Overlay networks providing VPN-like connectivity often lack the transparency and granular access controls of HTTP proxies, which diminishes the benefits of adopting BeyondCorp and may ultimately result in placing trust in the overlay network itself.
We thank the following colleagues in the BeyondCorp team for their work on achieving this latest milestone, in alphabetical order:Jeff Baird, Blake Jensen,Brett Ksobiech, Giovanni Mazzeo, Bradley Melody, Patrick Nehls, Barclay Osborn and Paweł Sałek.



