Operating system design has long been characterized by inherent trade-offs, often framed as "trilemmas" where optimizing for one critical attribute necessitates compromises in others. This fundamental challenge also echoes across various domains of computer science, like the CAP theorem forcing a choice between consistency, availability, and partition tolerance in distributed systems. These recurring patterns underscore a deeper principle that complex systems frequently face fundamental compromises when striving for multiple desirable characteristics simultaneously.
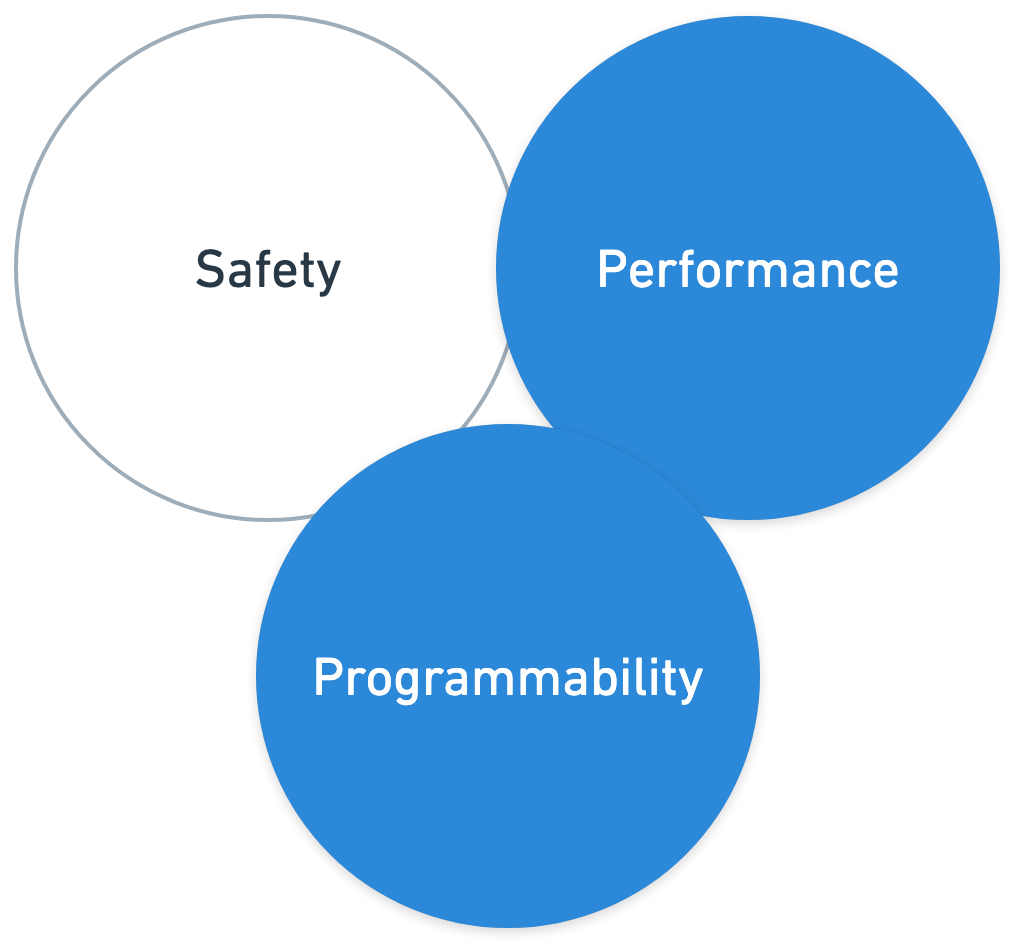
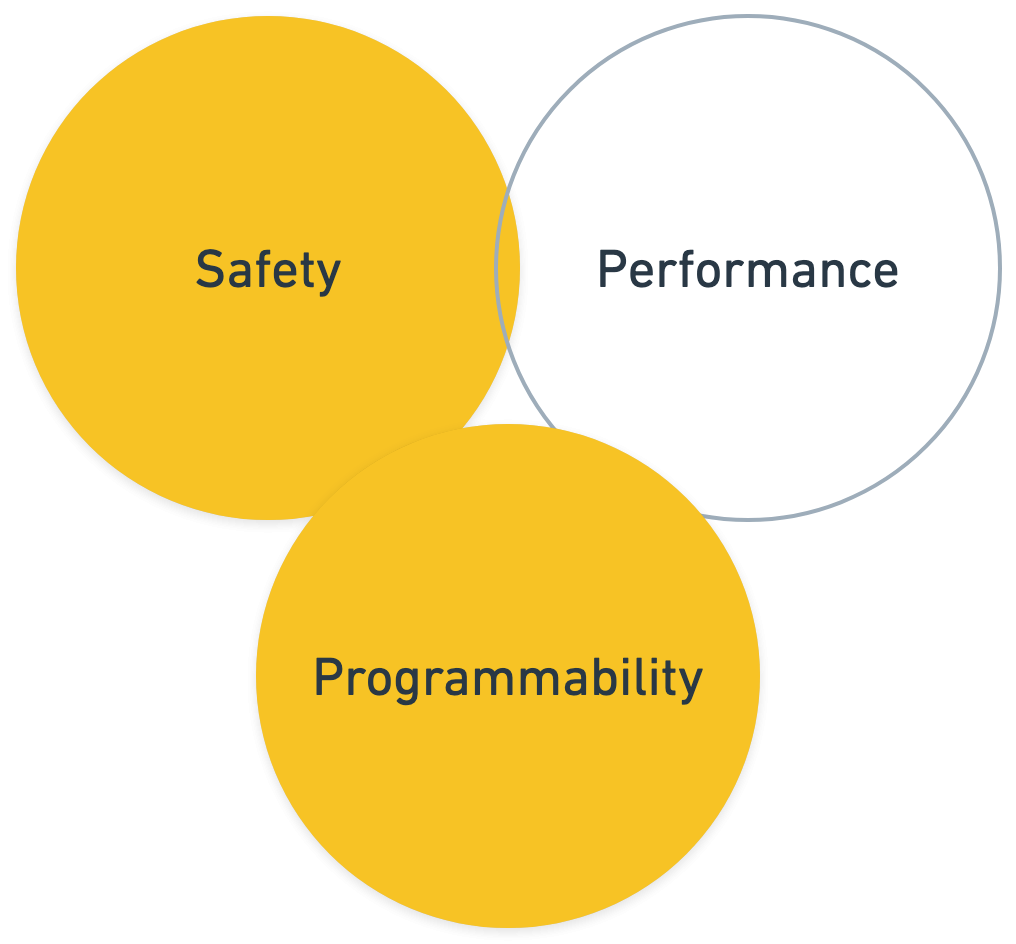
In the realm of operating system programming, a persistent trilemma has historically revolved around Safety, Performance, and Programmability. Achieving an optimal equilibrium across these three crucial attributes has presented a significant hurdle, forcing developers and architects into difficult choices between them.
Safety encompasses the system's stability, security, and resilience against errors, vulnerabilities, or malicious actions, including memory safety, fault tolerance, and effective recovery mechanisms. Performance refers to the speed, efficiency, and resource utilization of operations, aiming to minimize latency, maximize throughput, and optimize CPU and memory consumption. Programmability denotes the ease with which new features or functionalities can be developed, deployed, and adapted, covering development complexity, debugging ease, dynamic extensibility, and compatibility across system versions.
Before eBPF, extending kernel functionality, without upstream changes, typically involved either kernel modules or user-space agents. Each enabled programmability, but also presented its own set of trade-offs with safety and performance.
Kernel modules are object files containing code designed to extend the kernel's functionality at runtime. They can be loaded and unloaded as needed, providing a solution to the inherent lack of extensibility in traditional monolithic kernels. Operating directly within kernel space, these modules possess full and unrestricted access to kernel internals and hardware. This deep integration makes them suitable for tasks demanding low-level control, such as implementing device drivers or dynamically adding new kernel features.
The key advantage of kernel modules is performance because of their direct integration with the kernel. However, this pursuit of performance often comes at the cost of system safety. A single mistake or bug in a kernel module can lead to severe system instability, including blocking the entire system or even a "kernel panic" (a fatal error requiring a system reboot) as showcased by the CrowdStrike incident that took down IT systems worldwide. Kernel module’s unrestricted access means a poorly written or malicious one can compromise the entire system, posing significant safety and security vulnerabilities.
Furthermore, the practical realities of developing and deploying kernel modules reveal significant rigidity. Compiling kernel modules is non-trivial; they require specific kernel headers and must be compiled with the exact same options as the kernel they are intended for. Deployment is also cumbersome, as modules often need to be built against specific kernel versions. While a simple module can be loaded and unloaded with a command like modprobe without a reboot, applying security patches or other critical updates to the kernel often necessitates a full system reboot to ensure the changes are applied safely and the system remains stable. System reboots can also be necessary during troubleshooting, which severely slows down the development cycles.
This rigidity makes modern practices like live patching impossible for customized kernels, unlike standard ones. Maintaining custom kernels manually is a complex task requiring considerable in-house expertise for applying security patches, recompiling customizations after updates, and rigorous testing before deployment. Thus, the "flexibility" offered by kernel modules comes with a significant hidden cost in terms of operational friction, development overhead, and potential system downtime, making it difficult to leverage in dynamic, high-availability environments.
User-space agents are traditional applications that operate in "user mode," a sandboxed environment purposefully isolated from the kernel. To access kernel-provided services or low-level system data, user-space programs must interact with the kernel via Userspace Application Programming Interfaces (UAPIs), primarily through system calls. This bifurcated architecture is fundamental to isolating ordinary programs from the kernel, ensuring that a buggy program does not crash the entire system. This isolation also means that a malicious user program cannot directly compromise the kernel to, for example, hide processes or grant unauthorized access. These agents are commonly employed for various system-level tasks, including monitoring, logging, performance analysis, and security auditing.
The primary benefit of user-space agents is their inherent safety. Because they are sandboxed and operate in user space, a buggy or malicious program is prevented from crashing the entire system or accessing sensitive kernel data directly. This isolation makes the system more resilient to application crashes.
However, the very mechanism that ensures safety in user-space agents, their isolation from the kernel, is also the primary cause of their performance limitations. The most significant bottleneck is the frequent context switching between kernel space and user space required every time they need to access kernel-level data or services via system calls. This constant switching incurs substantial overhead and introduces significant latency. Traditional monitoring agents, by requesting data from the kernel, incur a processing overhead and consume more memory and CPU resources compared to in-kernel execution. Compounding this, recent security mitigations for vulnerabilities like Spectre and Meltdown have unfortunately made syscalls even slower, further degrading performance. This direct causal link between safety mechanisms and performance degradation highlights a dilemma where prioritizing safety through strict isolation compromises efficiency, making such systems impractical for many modern, high-performance applications.
Beyond performance, user-space agents introduce considerable operational challenges. Agent-based monitoring solutions can consume valuable system resources, including CPU, memory, and network bandwidth, potentially impacting the performance of the applications they are monitoring. Data collection by user-space agents is inherently limited to what they can observe from their isolated user-space perspective. In modern cloud native architectures where ephemeral workloads can come and go quickly, the lifecycle of a container can be shorter than the time required for a user-space monitoring agent to fully deploy and initialize, making effective monitoring impossible.
eBPF is highly flexible and programmable and allows safe and efficient execution of user-defined programs directly within the Linux kernel. It operates by attaching small, event-driven programs to various kernel hooks, such as system calls, tracepoints, network events, kprobes (kernel probes), and uprobes (user-space probes). These programs execute upon specific triggers, such as packet reception or a kernel function call.
eBPF’s architecture is built upon several key components that collectively enable its unique capabilities:
-
Hook Points: eBPF programs are event-driven and require a "hook point" to execute. These hooks are locations in the kernel or in user-space applications that trigger the eBPF program to run, allowing for highly granular and dynamic instrumentation. Predefined hook points are available for common events like system calls, kernel tracepoints, and network events. For custom needs, developers can create a kernel probe (kprobe) or a user probe (uprobe) to attach eBPF programs almost anywhere. A uprobe is a mechanism to dynamically instrument a function or routine within a user-space application. When triggered, a traditional uprobe enters the kernel and executes the eBPF program, which requires two context switches, one into the kernel and one back out. This process can introduce significant overhead, similar to the performance bottleneck faced by user-space agents. To address this, the eBPF community is developing new solutions, such as user-space eBPF runtimes like bpftime, which bypass the context switches entirely by running the eBPF program in user space.
-
Restricted Execution Environment: eBPF programs run in a restricted virtual machine within the kernel. This restricted environment is crucial for ensuring safe execution and minimizing the risk of kernel crashes or instability, providing a clear advantage over traditional kernel modules.
-
Verifier: Before any eBPF program can run, it undergoes a rigorous verification process by the in-kernel BPF verifier. The verifier checks for potential issues, such as attempts to access memory outside designated regions, guarantees program termination (for example by forbidding loops), performs strict type checks on helper function arguments, and ensures buffer initialization. The verifier is central to eBPF's safety guarantees.
-
JIT Compiler (Just-In-Time): If the program successfully passes verification, the kernel's Just-In-Time (JIT) compiler converts the eBPF bytecode into native machine code optimized for the underlying CPU architecture. This JIT compilation significantly speeds up execution by reducing the per-instruction cost and often mapping BPF instructions one-to-one with native instructions, improving CPU instruction cache friendliness.
-
Maps: eBPF programs can utilize efficient key/value stores called maps, which reside in kernel space. These maps allow eBPF programs to maintain state across invocations and communicate with user-space applications. Maps can also be shared among different eBPF programs, enabling complex interactions and data exchange.
-
Helper Functions: eBPF programs can invoke a set of bpf_helper kernel functions, which provide access to common kernel functionalities like memory copying, retrieving process IDs (PIDs), timestamps, and interacting with maps.
-
Tail Calls: Allows one eBPF program to call another eBPF program, enabling modularity and the creation of more complex, chained logic without returning to user space.
A more in depth history and architectural overview can be found here.
eBPF achieves kernel-level performance with enhanced safety and programmability without kernel modification through a unique combination of these mechanisms. By executing directly within the kernel space, eBPF programs eliminate the need for costly user-kernel context switches and syscalls that burden user-space agents. This direct access to kernel-level resources and system data enables high performance.
The eBPF verifier is the cornerstone of eBPF's safety model. It guarantees that programs are safe, terminate, and cannot destabilize the system. The trust through verification approach represents a fundamental shift in how privileged system components can be extended safely and dynamically. The JIT compiler further optimizes eBPF bytecode into highly efficient native machine code, ensuring that programs run with minimal overhead and near-native speed.
Finally, a key advantage for programmability is the ability to dynamically load and unload eBPF programs without requiring system reboots. This allows for real-time updates to monitoring, security, or networking logic without service interruption which represents a fundamental shift from the rigid, static, compile-time approach of kernel modules to a truly dynamic, runtime approach.
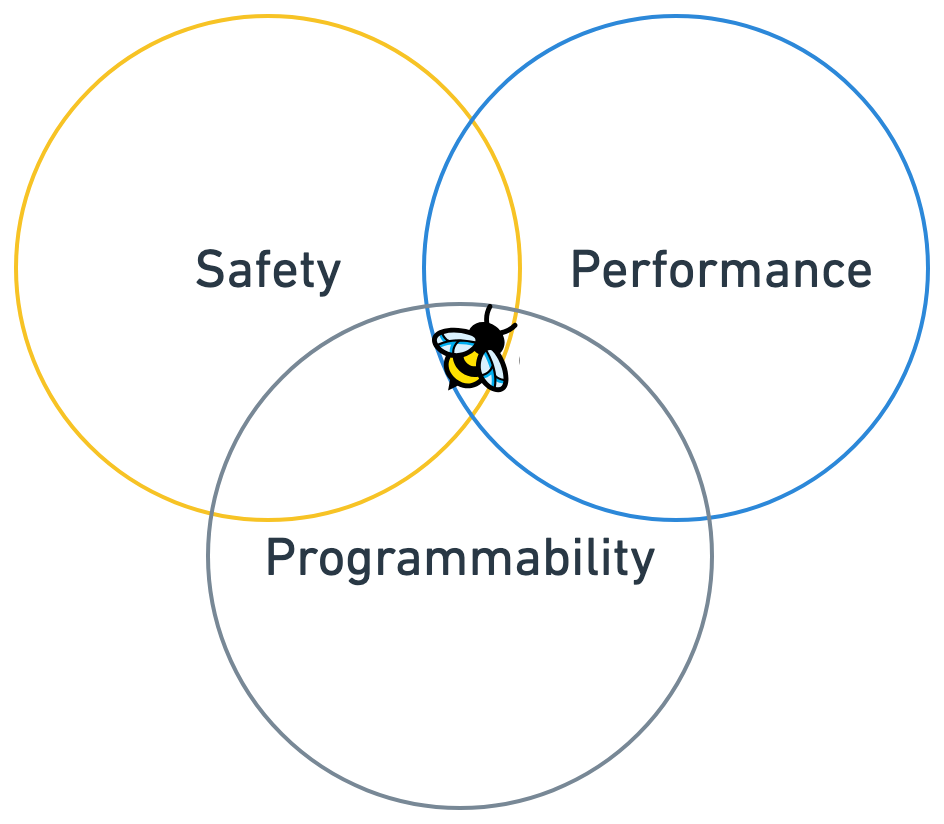
eBPF represents a profound shift in operating system design, fundamentally overcoming the traditional Systems Trilemma by providing an unparalleled balance of Safety, Performance, and Programmability. It successfully "threads the needle" where previous technologies, such as kernel modules and user-space agents, were forced into difficult compromises. Kernel modules offered raw performance but at significant risk to system stability and with high development complexity. User-space agents provided safety and ease of development but suffered from substantial performance overhead due to constant user-kernel context switching.
eBPF's innovative architecture, featuring an in-kernel verifier, Just-In-Time compilation, and a sandboxed execution environment, enables kernel-speed execution with robust safety guarantees. Its dynamic loading capabilities and rich tooling ecosystem provide programmability and flexibility, allowing for real-time system introspection and modification without kernel recompilation or reboots. The ideas behind eBPF are changing how we think about system-level programming.
eBPF has democratized access to kernel-level control, allowing a broader range of developers to innovate safely within the kernel. Furthermore, eBPF's ability to provide rich, real-time, low-overhead data positions it as a foundational technology for building truly intelligent, responsive, and self-optimizing infrastructure. As the technology continues to evolve and its ecosystem matures, eBPF is poised to reshape how complex computing systems are designed, built, and operated for years to come.
Where to learn more about eBPF:
