We all know the importance of keeping software up-to-date in defending against attacks. Some of the most catastrophic security incidents (such as, the 2017 Equifax hack affecting approximately 150 million users [1]) were the result of unpatched vulnerabilities. Similarly, our own past research has demonstrated that, just by existing, web applications receive hundreds of attack probes on a daily basis [2],[3]. This need to keep software up to date, begs the following question: how can we tell the version of a piece of software?
When we consider a single machine, the answer is straightforward: log-in to that machine and check the version of the software in question. What happens, however, when we need to answer that question, not for a single machine for which we have access to, but for potentially tens of thousands of machines of a large organization? To make things more interesting, these machines are not conveniently situated in one place but typically scattered across multiple different departments and administrative domains, without a clear understanding of who is responsible for what machine.
"Fingerprinting" is an overloaded term in computer security, which can refer to fingerprinting browsers, servers, Tor connections, and anything in between. In the context of web applications, fingerprinting refers to being able to establish the type and version of a web application running on a remote server, without having any special access to that server. That is, using web-application fingerprinting, one could discover that a specific web application deployed on one’s network is a 2021 version of WordPress and therefore one that is highly outdated and most likely vulnerable to attacks.
In the context of computer security, web application fingerprinting enables the following constructive capabilities:
- Identifying Vulnerabilities: By knowing the specific version of a web application, administrators and security professionals can determine if it has any known vulnerabilities. This allows organizations to patch these vulnerabilities before they can be exploited by attackers.
- Compliance and Auditing: Some regulatory frameworks require organizations to maintain an up-to-date inventory of the software running on their systems. Fingerprinting helps automate this process, ensuring ongoing compliance across departments.
- Identifying shadow IT infrastructure: Information technology resources (software, hardware, devices, and services) can be used within an organization without the knowledge of that organization. Web-application fingerprinting can help uncover these resources which are typically forgotten and therefore often outdated.
Web application fingerprinting tools analyze the content and behavior of a website to determine which application and what version is being used. These tools generally rely on two main techniques: fingerprinting static content and fingerprinting dynamic content.
Fingerprinting Static Content
Static content refers to files that do not change in response to user interactions. Examples include JavaScript files, CSS files, image files, and documentation files (e.g., README, Changelog).
Fingerprinting tools that focus on static content (such as BlindElephant) typically calculate hashes (e.g. MD5 or SHA256) of these files. By comparing the hashes of files on a target website with a database of known hashes from different versions of web applications, these tools can often identify the application and its version.

The above code snippets show an example of web-application fingerprinting using static content. The change of a single digit in a JavaScript file produces radically different hashes which can then be associated with different versions. In this way, if a web application fingerprinting tool finds a file with the 3086[...]4df7 hash on a target website, it will conclude the web application in question is most likely WordPress version 5.8.1. The more positive matches between file hashes and a specific web application version, the more confident the tool can be of its prediction.
Fingerprinting Dynamic Content
Unlike static-content fingerprinting which is incidental (i.e. the web application is not trying to communicate any version information through its static files), dynamic-content fingerprinting largely relies on explicit type and version information that is already present in a web application, if one knows where to look. This version information can be present in HTML Meta Tags, version artifacts in local URLs, and any other version information present in the body of arbitrary files served over that web application.
Here we see three different examples of how a web-application fingerprinting tool can identify that a target web application is WordPress by just looking for the right strings in the HTML pages already served by that web application.

While web-application fingerprinting appears straightforward, there are many things we do not know about it. Can these tools actually be used to accurately identify the type and version of a web application? Are there enough differences from version to version for these tools to pick up or is there a large chance of version collisions where a tool cannot differentiate between multiple versions of the same web application? What is the performance difference between ideal conditions (scanning off-the-shelf web applications with as little customization as possible) vs. the real world (scanning real web applications in the wild)? Is it possible to improve the performance of these tools without actually changing their source code?

In our recently published paper at USENIX Security 2024 [4], we designed and developed WASABO to answer these exact questions. WASABO (shown in Figure 3) is a container-based web application testbed system allowing us to stage any version of a web application for laboratory testing of each fingerprinting tool, as well as automate large-scale online fingerprinting campaigns. Using WASABO, we were able to evaluate the performance of six popular web application fingerprinting tools (including BlindElephant, WhatWeb, and Wappalyzer) against thousands of versions of popular web applications (including WordPress and Drupal). For example, WASABO includes containers for 558 WordPress versions, from version 3.5.1 to version 6.1.1 which are used to evaluate the accuracy of the evaluated fingerprinting tools.
Accuracy in Controlled Settings
In ideal conditions, where the web applications were freshly installed without any modifications, 94.8% of them were correctly identified by at least one fingerprinting tool. However, the tools often failed to provide a single, definitive version of the application, leading not only to confusion but also to the potential hiding of real vulnerabilities in one’s infrastructure.
Security impact of version collisions
When multiple versions of a web application produce the same fingerprint, we refer to them as version collisions. In our experiments, we discovered that dynamic-content fingerprinting is less susceptible to collisions since if a version string is not present in a target web application, the tool does not attempt to “guess” the right version (as static-content fingerprinting does). The more versions that are included in a version-collision output, the more difficult it is for an operator to draw any conclusions about the up-to-date status of the scanned web application.
Our most extreme example was the WhatWeb’s fingerprinting tool which, when scanning WordPress v. 3.7.36 produced versions 3.7, 3.7.1, and 3.7.36 which are 7.5 years apart between the earliest and latest versions.
To understand the effect of collisions on vulnerability discovery, we recorded the 10 most severe CVEs for the evaluated web applications and assessed the extent to which a version collision involved one of the affected versions. Through this experiment, we discovered 82 instances where a vulnerable version of a web application was incorrectly labeled as a non-vulnerable version. For instance, CVE-2020-13664 was a high-severity vulnerability in Drupal that allowed remote code execution affecting Drupal version 9.0.0. One of the evaluated tools produced a version collision when fingerprinting that vulnerable version of Drupal, with the collision including versions 9.0.0 and 9.0.1 (the first version where that vulnerability was patched). Trusting the most recent version from that prediction would lead to ignoring that vulnerable deployment in one’s organization.
In theory, there is no difference between theory and practice; but in practice, there is.
Putting the issue of version-collisions aside, based on the laboratory experiments of WASABO, one may be tempted to conclude that these fingerprinting tools work really well. Yet, the real world is not like the lab. Users of popular web applications tend to customize them before releasing them by installing themes and plugins, deleting files they do not require, and even adopting hardening steps to explicitly counter unwanted fingerprinting attempts. How do these implicit and explicit customizations affect the performance of fingerprinting tools?
When we tested the same fingerprinting tools on real-world websites, their performance dropped significantly—up to 80% in some cases.
Tools were unable to detect files to hash, could not identify the right root directory from which to request files, could not find version strings in pages, and sometimes were detected by anti-bot solutions which altogether denied them access to a web application.
Our most unexpected source of trouble were Content Distribution Networks (CDNs). CDNs not only cache files closer to users but can apparently minify certain types of files, such as JavaScript scripts, to further improve a web application’s performance. In this way, a fingerprinting tool receives a minified version of a JavaScript library from the CDN which produces no matches in its fingerprint database, and therefore degrades its overall performance.
Making the ink more potent
Given the severe drop in performance of web application fingerprinting tools in the wild vs. ideal conditions, we wondered whether it would be possible to improve that performance. Changing their code to account for the aforementioned issues was possible but not desirable. Any new version of these tools would not include our patches and any new tools that may be released in the future could not benefit from our improvements.
As a result, we decided to include a proxy layer in WASABO turning it into a form of network middleware. The purpose of this proxy layer is to change the web requests as they leave the tool and before they are sent to the web application in a way that counters the most common reasons of why these tools failed when scanning real-world applications. Specifically, WASABO applies the following transformations to improve the accuracy of fingerprinting:
- Cache-Breakers: Adding random query parameters to requests to bypass caching mechanisms that might alter the content served to the fingerprinting tool.
- Web Path Prediction: Analyzing the structure of the target site to predict alternative paths for resources that might have been moved or renamed.
- Real-Browser Requests: Use a real web browser to make requests instead of the HTTP libraries used by the fingerprinting tools, thereby bypassing some forms of bot detection.
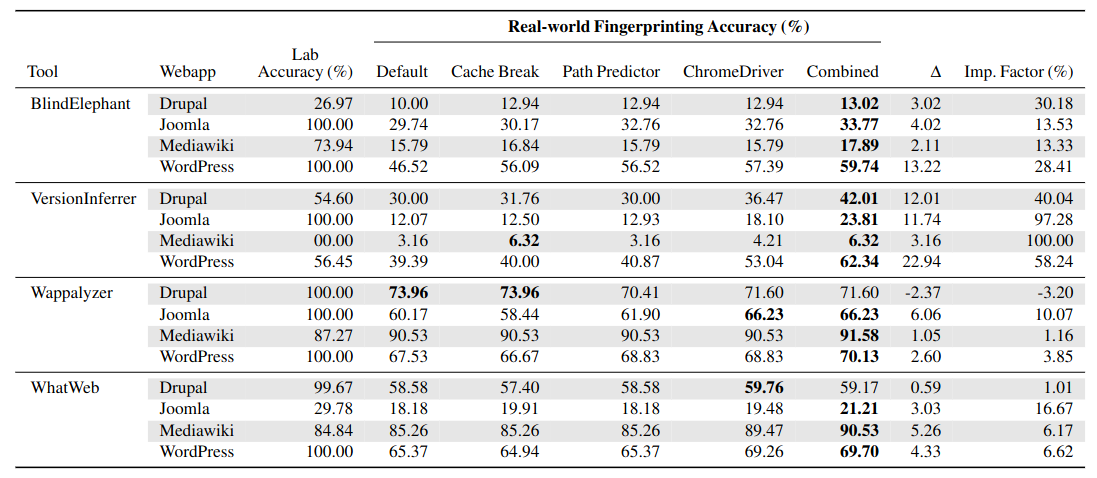
The following table shows not only the drop in accuracy of different tools when comparing ideal conditions and the real world (Lab Accuracy vs. Default Columns) but also the improvement of our tool-agnostic WASABO middleware, increasing their fingerprinting accuracy by as much as 22.9%. The tools that benefited the most from our middleware were the ones relying on static fingerprinting techniques and were therefore the most susceptible to content changes (some of which WASABO was able to undo).
Knowing the type and version of a remote web application is incredibly powerful in both a defensive as well as an offensive context. Given accurate fingerprinting tools, defenders can find outdated web applications in haystacks of servers and prioritize their patching. Offensively, attackers can confirm that a remote web application is indeed vulnerable before revealing their exploits to possible intrusion detection systems running at the server side.
In this work, we explored not just how web application fingerprinting is supposed to work in theory but to what extent these techniques work in the real world. Through our WASABO system, we discovered that the current generation of fingerprinting tools (particularly the ones that depend on static fingerprinting vectors) are brittle with the smallest of server-side changes being sufficient to throw them off balance. While this is good news in terms of limiting an attacker’s capabilities, it also limits the usefulness of these tools in the aforementioned defensive context. We also demonstrated how a couple of clever, tool-agnostic request changes can significantly improve the fingerprinting performance of the affected tools.
We are making WASABO available [5] to the community to motivate and support additional research in web-application fingerprinting, both in terms of making it better so that defenders can use it, but also detecting it when it is done in an unauthorized manner.
This material is based upon work supported by Office of Naval Research (ONR) under grant N00014-24-1-2193 as well as by the National Science Foundation (NSF) under grants CNS-2211575 and CNS-1941617. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the Office of Naval Research or the National Science Foundation.

