As organizations mature, they develop more tools. At Google, we continually create new external and internal services, as well as infrastructure to support these services. By 2013, we started outgrowing the simple automation workflows we used to update and maintain our services. Each service required complex update logic, and had to sustain infrastructure changes, frequent cluster turnups and turndowns, and more. The workflows for configuring multiple, interacting services were becoming hard to maintain— when they even existed. We needed a new solution to keep pace with the growing scale and variety of configurations involved. In response, we developed a declarative automation system that acts as a unified control plane and replaces workflows for these cases. This system consists of two main tools: Prodspec, a tool to describe a service's infrastructure, and Annealing, a tool that updates production to match the output of Prodspec. This article discusses the problems we had to solve and the architectural choices we made along the way.
Prodspec and Annealing have one fundamental aspect in common: rather than focusing on driving individual changes to production, focus on the state you want to reach. Instead of maintaining step-by-step workflows, service owners use their configuration of choice to describe what they intend their infrastructure to look like: which jobs to run, the load-balancer setup, the location of the database schema, and so on. Based on that information, Prodspec and Annealing take over and transform the configurations into a uniform structure, which is then actuated. The actuation is safe and continuous: the automation systems repeatedly compare the intended state as expressed in the user's model to the state of production, and automatically trigger a reconciliation when safe. Service owners are freed from having to manually shepherd configuration changes to production.
Since we started developing Prodspec and Annealing around 2015, the seemingly simple concept of intent-based actuation has become a de facto standard. A large part of Google production now has some layers characterized through their intended state, rather than relying on the emergent state created by workflows—a trend that's more broadly reflected across the industry.
There are a lot of moving pieces necessary to run a modern service. Particularly when talking about infrastructure-as-a-service, terminology can be confusing. For example, who is the "user"? The person or service using the infrastructure? The end user? Someone or something else?
Figure 1 shows how we'll talk about the various parties involved in this article:
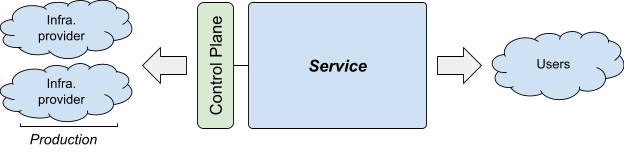
Service is a user-facing system a team wants to run, such as Gmail or Maps. A service can be composed of multiple narrower, internal services—for example, the Gmail service for detecting spam is just one of the services that makes up Gmail.
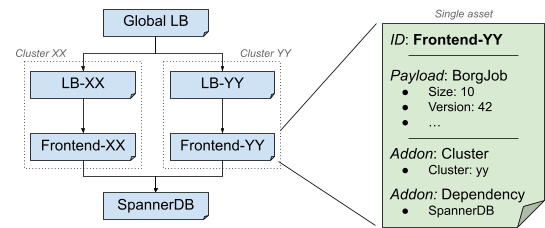
To help illustrate the ideas in this article, we will refer to the serving side of the Shakespeare service, a hypothetical service represented in Figure 2.
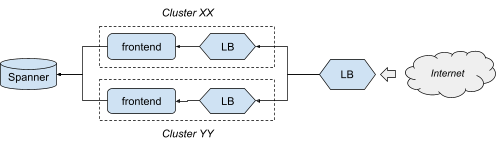
This service is a simplified web app, made of:
- A binary running in two clusters for redundancy, implementing the frontend logic.
- Load balancing, with both a per-cluster and a global configuration.
- A global Spanner database.
The Shakespeare service uses multiple infrastructure providers: Borg to run the binary, GSLB to manage the load balancing, and Google's shared Spanner infrastructure.
The control plane is what the service uses to manage production service infrastructure— for example, to add a VM or set up a load balancer. The control plane can range from humans ("I will copy my new binary to the server") to complex automated systems ("I'm using machine learning to control the updates"). The control plane includes change management: the logic in the control plane that allows the service to progress from one state of production to another in a safe and controlled way.
In the Shakespeare service, the control plane for the frontend is the Borg API, which configures the corresponding jobs and runs them in each cluster.
In this article, we define a job as a set of similar tasks, similar to a Kubernetes ReplicaSet. A task is a single running instance, often a single process, similar to a Kubernetes Pod. A given job runs all its tasks in a single cluster. A cluster is a set of compute nodes able to run multiple tasks and clusters, and is usually colocated geographically.
In Shakespeare service, each frontend is a job in a given cluster.
In the next sections we focus on how we introduced an explicit control plane for our production to improve change management.
Our Challenges
Service design tends to focus on the service infrastructure, addressing important but fundamentally static questions: How are your user requests served? Which servers and databases does your service use? How much traffic should your service support?
Those are important questions, but our services are alive and ever-changing: binary versions are updated, and instances are added and removed. Architectures also often evolve: we might want to add a new cache in a specific cluster, remove some outdated logging, and so on.
In 2014, we found ourselves in the position of not adequately accounting for the live nature of our services. For most of our services, we made infrastructure changes using hand-crafted procedural workflows: push x, then y; perform the odd change manually.
But teams were commonly managing tens of services apiece, and each service had many jobs, databases, configurations, and custom management procedures. The existing solutions were not scaling for two main reasons:
- Infrastructure configurations and APIs were heterogeneous and hard to connect together— for example, different services had different configuration languages, levels of abstraction, storage and push mechanisms, etc. As a result, infrastructure was inconsistent, and establishing common change management was difficult.
- Production change management was a brittle process, with little understanding of the interactions between changes. Automated turnups were an exercise in frustration.
The Configuration Gap
From an infrastructure provider perspective, a given service is likely to have significant redundancy in its configuration. In the Shakespeare service, everything runs under the same identity, so it's redundant to specify the user for each frontend job. However, because the infrastructure can run jobs for many services, configuration must still specify the user of each job.
A simple solution for the infrastructure provider is to provide a more advanced configuration surface—for example, a templating language. However, from the service perspective, this approach doesn't necessarily eliminate redundancy. The service has to configure multiple providers, and some information is usually common across those providers. For example, the name of a database is relevant both for the jobs using it (compute provider) and for configuring the database (database provider).
A configuration system is useful in these types of scenarios. Whoever maintains the service can create a high-level description of their service (for example, run N tasks in clusters x, y, and z), and the configuration system expands that description into a suitable format for each infrastructure provider.
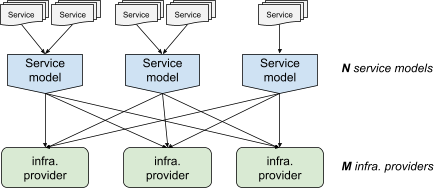
As long as you're only dealing with a few infrastructure providers, the NxM problem is manageable. As the number of infrastructure providers increases (look at the number of products available on Google Cloud, AWS or Microsoft Azure!), the quality and existence of these integrations starts to suffer.
Reducing the number of infrastructure providers is not really an option. Each provides a different service (for example, a key-value store, a pubsub system, etc.), and while some redundancy might exist, this is the exception more than the rule. It's also not feasible to have a single service model—that model would have to expose every single feature of each infrastructure provider, defeating the purpose of having a service model in the first place.
Google engineers were spending a significant amount of time connecting their preferred service model to the infrastructure they wanted to use. We clearly needed to approach configuration differently.
Deploying at Scale
Before we started addressing this problem space, we relied on traditional workflow engines. For example, a workflow outlined the steps to deploy a new binary: canary in cluster X, then deploy N at a time in clusters Y and Z, run a test, and so on. Creating a workflow required quite a bit of work, so we only had workflows for frequent cases like binary version updates. We often handled less common cases, such as turnups, manually. When a script existed, it was frequently outdated.
Those workflows are easy to conceptualize for the operator: do X, then Y. You want to add a load test? Just add a step. As appealing as these workflows are in many aspects, we were running into problems when scaling our usage of workflows.
First, scaling workflows led to a lot of duplication. Each service had a good reason to have some subtly different logic, which meant it needed a custom implementation. There were a few attempts at homogenizing workflow implementations, but only services fitting a very specific mold would fit. The resulting duplication made services across our fleet inconsistent. Best practices, such as progressive rollouts across clusters, were hard to enshrine in common parts.
It was becoming impossible to design each workflow by hand. Something had to change to reduce the number of interactions and expectations. Faced with a proliferation of service models and deployment scaling pains, we moved toward declarative management of our production through intent, managed by Prodspec, with continuous enforcement of that intent, performed by a system called Annealing.
Many of the concepts described in this article might be familiar from the broader market of service deployment and management. Declarative automation has become more common in the last few years, so you may find parallels to Google's declarative automation systems, Prodspec and Annealing, in your own production management environment.
- Annealing is built toward continuous enforcement. Annealing applies updated configurations only when it's safe to do so, and without requiring human interactions. Annealing also monitors the health of the service after applying a change.
- Terraform has a uniform configuration surface through HCL. Conversely, Prodspec directly consumes existing configuration sources.
- Prodspec forces hermeticity, allowing it to generate configuration data without access to the production it describes. This configuration data can be compared across versions and read by any tool— not only the actuation layers.
- Prodspec is authoritative and Annealing is built to recover state as needed from production. This avoids the need of a state file like Terraform, but requires clean resource naming from the infrastructure provider and impacts turndown management.
- Prodspec and Annealing scale to the millions of resources Google has to manage.
Intent Management: Prodspec
To solve the NxM problem (see The Configuration Gap), we introduced an explicit unified model of production called "Intent".
As shown in Figure 4, the intent model fits between the service models and the infrastructure providers. Rather than having to deal with many different service models, infrastructure providers feed from a unified intent. And instead of having to adapt to the idiosyncrasies of each infrastructure provider, service models can target a standardized representation (the intent model).
To return to the Shakespeare service: it would have a configuration driving its service model, which in turn would generate the intent necessary to configure Borg, load balancing, and Spanner.
This way, we separate the generation of the intent from the actuation of intent, shifting the NxM problem to a N+M situation, making the diversity of configurations and service models manageable.
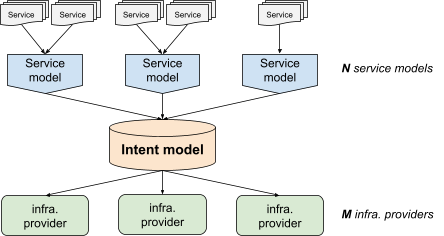
This explicit intent also allows us to introspect the configuration, which makes troubleshooting complex setups easier. For example, with a templating system directly integrated into a provider, it's hard to tell whether problems that arise are caused by your template logic, or by the provider's application of that logic. Explicit intent makes it easier to determine which layer (see Figure 4) is causing an issue. Is the intent what you expect? If yes, the problem is on the provider side. If not, the problem is with your service model.
- A data model that structures the content.
- A pipeline to generate the content.
- A serving infrastructure.
Data Model
Prodspec's declarative intent is modeled through a few abstractions, as shown in Figures 5 and 6:
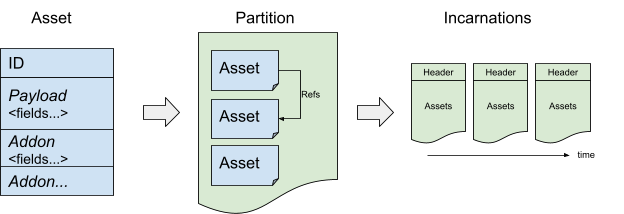
- Assets: Each asset describes a specific aspect of production.
- Partitions: Organize the assets in administrative domains.
- Incarnations: Represent snapshots of partitions at a given point in time.
Assets
Assets are the core of Prodspec's data model. An asset contains the configuration of one specific resource of a given infrastructure provider. For example, an asset can represent the resources in a given cluster or instructions for how to configure a specific job.
In the Shakespeare service (see Figure 6), we would want to have an asset for each frontend job, an asset representing the per-cell load-balancer configuration, an asset for the global load balancer configuration, and an asset for the Spanner DB schema.
- A string identifier, simply called "asset ID".
- A payload.
- Zero or more addons.
Partitions
Assets are grouped into administrative boundaries called partitions. Partitions typically match 1:1 with a service. However, there are exceptions. For example, a given user might want to have one partition for its QA environment and another for its Prod environment. Another user might use the same partition for both its QA and Prod environments. In practice, we leverage the notion of partitions to simplify many administrative aspects. To name a few aspects:
- Content generation occurs per partition.
- Many ACLs are set per partition.
- Enforcement is fully isolated per partition.
- An asset ID must be unique within a partition.
Incarnations
We regularly snapshot the content of a partition. Those snapshots are called incarnations, and each incarnation has a unique ID. Incarnations are the only way to access Prodspec data. Besides being a natural consequence of the generation logic (see Generation Pipeline), the incarnation model provides immutability and consistency.
Immutability ensures that all actors accessing Prodspec make decisions based on the same data. For example, if a server is responsible for validating that an asset is safe to push, the server actuating the push is guaranteed to work on the same data. Caching becomes trivial to get right, and it is possible to inspect the information used for automated decisions after the fact.
Generation Pipeline
Early on in Prodspec's development, we decided to separate how assets are created from how they are consumed.
- We can optimize the data model to make data easy to consume. Most data models avoid redundancy, as redundancy makes it difficult for writers to edit the data consistently. Because our model doesn't permit editing data in place, we can afford to generate duplicated information. This way, the logic in consumers can stay simple— for example, they don't need special logic to find out where the default value for a field is located, and instead just rely on the data to have been expanded in place.
- Integration with existing configuration. This was a major driver for creating our generation pipeline. In practice, users have integrated Prodspec with a large number of configuration formats and practices.
- Sources of Truth can be optimized for human or programmatic editing. This is useful because we need to configure network switches quite differently than how we configure the Google Maps frontend. For example, you might want to always change the binary version of all the frontend servers together. With a simple database approach, that would require editing every single asset, leading to potential inconsistencies, especially for more complex cases. Instead, with Prodspec you can have a source of truth with only one field for that binary version and generate all the frontend assets, guaranteeing their consistency.
- Easier backward compatibility. We commonly add a new field to fix or expand the semantics of an existing field. When we do so, we add logic in the generation pipeline to automatically fill in the content of one field with the other. This way, producers and consumers can be updated to use the new field progressively, and we don't need to perform any risky synchronized updates.
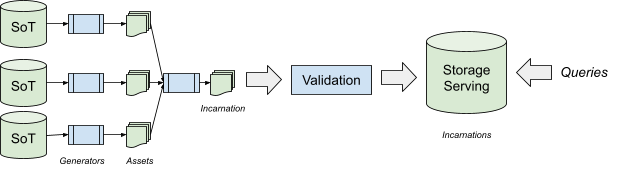
Sources of Truth are the starting point of the pipeline. Whenever a SoT changes, we rerun the full pipeline, which creates a new incarnation. This process occurs continuously. Because some partitions undergo many changes, we coalesce regeneration. Therefore, a new incarnation might be caused by multiple SoT changes.
A new user of Prodspec must choose which sources of truth will describe their service. In practice, most of our users fall into very common patterns, and choose a ready-to-use setup. For users with more specialized needs, we allow custom SoT formats and generators.
In the Shakespeare service, we might have a simple manifest to indicate where the frontend must run, its binary version, and its sizing. Those SoTs are sufficient to configure the frontend and load balancer assets. The database schema likely comes from another SoT.
We maintain most SoTs on our version control system, and execute generation logic as part of our hermetic build. Keeping SoTs in version control allows us to observe changes over time and to trace changes. Hermetic builds allow for reproducibility, a useful tool to help guarantee stable configuration and better debuggability.
We created Annealing to drive continuous deployment. Once intent is declared in Prodspec, we want production to match that intent. Updating the intent usually involves manual work and approval, but after that point, automation should remove the need for human interaction. Annealing takes that role.
- The enforcement layer, driven by the Enforcer, which drives changes from the intent in Prodspec to production.
- The strategies layer, driven by Strategist, which schedules enforcement by updating the intent.
Enforcement
Enforcer takes over the last mile of actuation. As shown in Figure 8, Enforcer tracks the intent and calls plugins to update the state of production. Enforcer has no control over the intent: its only decision is whether each specific asset can be pushed now or needs to be delayed.
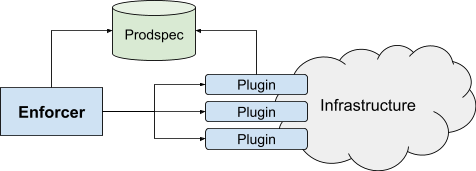
All interaction with the infrastructure occurs through plugins, as Enforcer never touches or looks at production directly. This allows any user to add more integration points, which is useful because services often have some specific needs, such as a custom config or APIs. The plugin approach also helps with deployment: instead of rolling out a monolithic binary, we roll out many small binaries, each with its own lifecycle.
- Asset plugins manage the interaction of Annealing with production for a given type of asset. Asset plugins implement two methods:
- Diff, to determine whether a given incarnation matches production. It is the only mechanism to extract information about the intent or the state of production.
- Push, to update production, using the configuration specified in the intent.
- Check plugins indicate whether an asset can be pushed now or should be delayed. All checks must pass for an asset to be pushed.
- Kubernetes controllers watch resources for changes. Annealing plugins do nothing unless explicitly called.
- Annealing plugins are more fine-grained. A single Kubernetes controller might look up whether an action is needed (asset plugin diff), verify that the change can be pushed now (check plugin), and perform the update (asset plugin push).
- Pinning: Determines which incarnation to use as intent.
- Diff: If no difference exists between intent and production, the loop iteration stops.
- Check: When a push is needed, verifies whether the push can proceed now. Otherwise, the loop iteration stops.
- Push: Updates the infrastructure based on the intent.
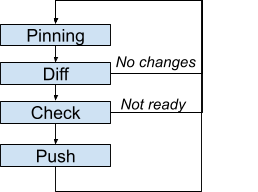
The loop does not pick up each incarnation one after the other, and there is no guarantee that each individual incarnation will be enforced. Instead, each iteration uses the latest incarnation. This approach avoids getting stuck on a broken incarnation. Instead, there's an opportunity to fix the intent, which will be automatically picked up. As a consequence, if a specific intermediate state must be reflected in production, you must wait for that state to be enforced before updating the intent further.
- The calendar check prevents pushes on weekends and holidays.
- The monitoring check verifies that no alert is currently firing, or that the system is not currently overloaded.
- The capacity check blocks pushes that would reduce the serving capacity below the maximum recent usage.
- The dependency solver orders concurrent changes to ensure the right order of execution.
- A request to push an asset A is made, as described in previous sections.
- Enforcer calls the check plugins, including the solver.
- The solver checks the diff of asset A. If the diff indicates a change not impacting capacity, the check passes.
- If the check finds a change in capacity, the solver queries the dependencies of the asset. Those dependencies are explicitly listed in Prodspec with an addon and are often automatically generated in the Prodspec generation pipeline.
- The solver requests a diff against production for each dependency B.
- If the diff on asset B indicates that it requires a capacity change for the service to operate properly after asset A is pushed, then the push of A is blocked until the diff on asset B disappears. Otherwise, asset A can proceed and be pushed.
Progressive Rollouts
Enforcer only takes care of the last mile: once it determines the specific intent for a given asset, Enforcer checks that it is safe to perform the update, then drives the update.
But what if you want to deploy a change progressively at a larger scale? Let's imagine that the Shakespeare service is running in 10 clusters instead of just one. You would not want to update every single cluster at the same time. Instead, you would want to set the new target state (for example, running v2 of the binary), and then update each asset in a controlled manner.
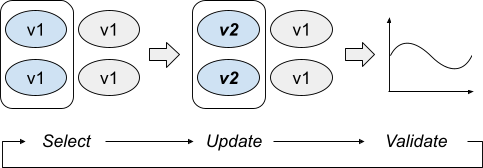
- Select: Determines which assets can be updated at this point of the rollout, based on the rollout policies and checks. Should we pick a specific cluster? Can we update more than one asset now?
- Update: Changes the state of production for the selected assets to the new state.
- Validate: Determines if the change was good. If not, the rollout should stop here, and potentially be followed by a rollback.
- Strategist runs these three steps continuously until all assets affected by the rollout are updated or it identifies a problem.
Select
The goal of the Select step is to pick which assets can be updated right now. This step can return nothing if no asset is ready to be pushed. In general, rollout policies are encoded here— for example, a policy that specifies that a canary should be pushed first, followed by some period of delay, and then incrementally to the rest of production, with some further delays between each step.
The select step is implemented through a stateless service called Target Selection. This service offers a single RPC method, where:
- The input is the rollout's list of assets and information about which assets have already been updated.
- The output is a list of assets that are not yet updated, but ready to be updated at this moment. This list can be, and often is, empty— for example, because some delay between stages of the rollout is configured.
- Push everything at once.
- Push one cluster at a time, in a predetermined order.
- Push one asset, then all other assets.
Update
Once assets are selected to be updated, Enforcer drives the actual production change. There are two fundamental ways to drive those changes:
- Actuation-based updates carefully push the intent. The intent represents the final desired state for all assets. The update step triggers enforcement of selected assets, while other assets are not actively enforced.
- Intent-based updates carefully change the intent. The intent represents the incremental desired state. The update step updates the SoT for the selected assets; all assets are continuously and immediately enforced in the background.
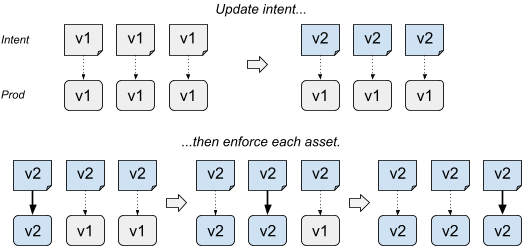
This approach has the advantage of being very simple: we just control how fast we advance along incarnations. It also acts as a catch-all mechanism: the specific changes to the SoT aren't really important because in practice, we carefully roll out the whole incarnation content.
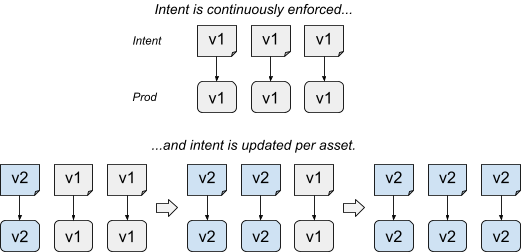
Intent-based rollouts are more complex than actuation-based rollouts. They require the ability to modify the intent programmatically. In the Prodspec model, this requirement means relying on a source of truth that's programmatically editable. The source of truth should also allow sufficient granularity to match how assets are selected.
To apply this model to the Shakespeare service, we need a SoT that allows us to specify the binary version of the frontend for each cluster independently.
Intent-based rollouts allow for rollouts impacting the same assets running in parallel— something not possible with actuation-based rollouts. The only constraint is that those rollouts must modify distinct aspects of the assets— for example, one rollout might change the binary version, while another rollout updates the flags.
Validate
Once the updates have been actuated, Annealing evaluates the impact to determine whether the rollout can continue, or if the rollout should be stopped or even rolled back. This step is automatic—we actively discourage manual validation of pushes beyond the very early stages.
- Enforcer level: Some Annealing plugins have built-in verification of asset-specific health. If a problem occurs, the push is signaled as failing.
- Strategist level: After we have selected and updated some assets, we verify the health of the service. We often introduce various waiting times to account for factors such as servers stabilizing after a push.
- Absolute values: We compare the monitoring to a configured value— for example, whether alerts are firing, or if errors are greater than 2%. This approach is robust as long as you can determine a baseline.
- Statistical: We compare the monitoring either against past values or against a control asset. While this approach tends to be more noisy, it requires almost no configuration and can work across many metrics. It can also catch anomalies beyond failure modes the service maintainer might have envisioned.
Integration with Workflows
Our objective with Prodspec and Annealing is to switch more production management toward an intent-driven model. In theory, we could manage all production changes through clever use of intent. However, we explicitly do not have a goal of converting all of production to an intent-driven model. In some cases, more traditional workflows make more sense.
- Size of the system: Intent-based actuation is useful when many changes occur in parallel, as you can encode the rules in a more intuitive way. For small systems with low concurrency, workflows tend to be easier to understand.
- Mental model: Do you have reasons to care about the exact detailed steps and want to be able to fine tune them, or do you just need the right thing to happen, as it is a detail of your infrastructure? The latter calls for intent; the former calls for a workflow.
- Complexity: Does the change require a lot of odd steps—for example, a one-time run of a batch job, some user inputs, and so on? If so, a workflow might be a good fit. Are you instead looking for consistency instead of fine tuning? Intent will help.
- Only one automation system should be responsible for a given part of production. For example, a common request is to have one system responsible for turnups and another system responsible for ongoing updates. Our experience shows that this practice introduces many synchronization problems, especially on more complex assets.
- State keeping should be minimal: you should rely on the state of production and the desired end state. State of production often evolves for more reasons than expected, and the more state you keep, the more likely the automation will make the wrong choice. We are often tempted to simplify the design of some plugin or workflow by storing extra state, but doing so often makes the system more fragile and harder to debug. This is not a hard rule— sometimes it does make sense to keep extra state, but determining when this is the right choice can be difficult.
Prodspec and Annealing act as a control plane between a service configuration and the infrastructure. The most obvious benefit of a centralized control plane is uniformity across how we manage production, but there are additional benefits, as well.
In the years since we shifted towards intent-based production management, we've learned a lot about what works and what doesn't. Here are a few of those lessons.
Enforcement
Having some form of continuous enforcement is fundamental for an intent-based configuration. Simply modeling intent results in stale and missing information. We've seen this problem in workflows created for managing turnups only, which have a track record of breaking when they're needed and requiring substantial effort to repair the workflow rather than executing the turnup manually. Continuous enforcement guarantees that the intent is either correct or very quickly fixed when a change impacts the intent. This in turn encourages people to manage their production via updates to intent, and to have many other tools feed from the intent. These behaviors reinforce the quality of the intent, leading to a virtuous cycle.
Modeling
Not everything in production fits well in an intent model. Data pipelines and batch jobs can be such cases. For example, it is possible to construct an intent representing batch jobs— an asset can indicate "this job must have run at least once in the last 24h"— while a plugin takes care of starting the job when the constraint is no longer valid. However, this setup is a bit awkward, and we haven't yet explored proper support for data pipelines and batch jobs through Prodspec and Annealing.
Adoption
The difficulty of adopting Prodspec and Annealing is probably the largest challenge we've faced. Switching to intent-based actuation requires a change in mindset, which takes time. At this point in our evolution, adoption is less of an issue, at least at the lower layers of the stack. However, the initial modeling of an existing service can be tough. This exercise often requires adapting complex sources of truth, which collectively may not contain all of the necessary information. Some production processes might need to adapt in order to move to intent-based actuation. For example, if you need to manually silence an alert during routine maintenance, you might need to instead make that alert more precise so you don't have to silence it the next time around.
Today, intent-based configuration and continuous enforcement are now largely accepted and adopted at Google. As we learn from our challenges and successes, our approach to intent-based actuation continues to evolve.
With special thanks to Niccolo' Cascarano, Adam Zalcman, Michael Wildpaner, Pim van Pelt, and Lee Verberne.

