Billions of people around the world use Google’s products every day, and they count on those products to work reliably. Behind the scenes, Google’s services have increased dramatically in scale over the last 25 years — and failures have become rarer even as the scale has grown. Google’s SRE team has pioneered methods to keep failures rare by engineering reliability into every part of the stack. SREs have scaled up methods that have gotten us very far—Service Level Objectives (SLOs), error budgets, isolation strategies, thorough postmortems, progressive rollouts, and other techniques. In the face of increasing system complexity and emerging challenges, we at Google are always asking ourselves: what's next? How can we continue to push the boundaries of reliability and safety?
To address these challenges, Google SRE has embraced systems theory and control theory. We have adopted the STAMP (System-Theoretic Accident Model and Processes) framework, developed by Professor Nancy Leveson at MIT, which shifts the focus from preventing individual component failures to understanding and managing complex system interactions. STAMP incorporates tools like Causal Analysis based on Systems Theory (CAST) for post-incident investigations and System-Theoretic Process Analysis (STPA) for hazard analysis.
In this article, we will explore the limitations of our traditional approaches and introduce you to STAMP. Through a real-world case study and lessons learned, we'll show you why we believe STAMP represents the future of SRE not just at Google, but across the tech industry.
Ideas like error budgets worked well with products that were largely stateless web services, but today our products have losses that must never occur—error budgets of zero. The types of failures we need to prevent have evolved beyond what error budgets can effectively address. Issues like privacy breaches, data loss, and regulatory compliance demand absolute prevention, not just low frequency and rapid mitigation. In addition to these elevated expectations, our systems also become more complex every year. Sophisticated automation has enabled us to scale, AI and ML are now core to almost every product we build, and cost and energy efficiency are as important as user-visible features.
SRE has always worked to not simply react to failures, but to anticipate and prevent them. But anticipating failures has proven wickedly difficult at Google, a system defined by one of the largest codebases in history. And AI is only increasing this challenge. How can SREs comprehend and manage the ever-increasing complexity of our systems, anticipate potential failures before they occur, and design safer, more reliable systems from the ground up?
The answer lies in a paradigm shift. Systems theory, control theory, and their application to solving problems through systems-thinking gives SREs a way to understand and manage complexity, all the way up to Google’s planet-scale systems. The future of SRE will use system-theoretic methods to provide comprehensive, efficient, and effective results in the AI-era.
The easiest way to introduce this new model is to contrast it with the way we traditionally thought about our systems. In general, any hazard analysis method consists of three parts:
A way to model the system
A way to explain how problems occur (a theory of causation)
A search algorithm
Although we never formalized it with theory, SRE has developed an effective method for analyzing hazards in our systems. Like every software engineering organization, we depend on accurate software architecture models to understand how things work. These models are often data flow models, showing how network requests or data move between different parts of the system.
This modeling technique gives rise to a common default of cause-and-effect reasoning to explain how problems might occur. We think deeply about dependencies in a linear data flow model — reliable operations come from careful management of dependencies. We use SLOs to understand the reliability guarantees of different components in a system, and ensure that those guarantees meet or exceed the caller’s requirements.
Finally, we commonly use induction to search for hazards. Induction, or bottoms-up reasoning from discrete events to general patterns, is how we approach writing the action items in a postmortem. We ask postmortem authors to think beyond repairing the one incident to what might prevent an entire class of incidents. We leverage postmortems to identify patterns and trends across Google. We ask SRE teams to do the same thing with their operational interrupts. A goal of SRE is to transform discrete alerts into engineering solutions that eliminate the cause of the problem altogether.
These practices have been instrumental in our ability to maintain reliability while scaling our operations to serve billions of users daily. They've allowed us to learn from failures, improve our systems incrementally, and build a culture of reliability across the organization.
However, we've seen our systems get more complex every year, and data flow models don’t scale to our enormous complexity. Without a consistent way to use abstraction, RPC diagrams and software architecture models become too complex to analyze, and are almost always either incomplete or out of date.
These kinds of models also provide no information about the dynamics of the system.
Which RPCs can initiate a flow?
How do errors propagate?
Which components could cause a critical outage? Which can only cause minor issues?
What if one component interaction is safe in some contexts, but unsafe in others?
What is the overall goal that the system is trying to achieve?
What responsibility does each component in the system have with respect to that overall goal?
Looking at a data flow diagram with more than 100 nodes is overwhelming—where do you even begin to search for flaws? Even more insidious are flaws that occurred at the requirements definition phase of the system's construction. A design might implement its requirements flawlessly. But what if requirements necessary for the system to be safe were incorrect or, even worse, missing altogether?
Learning from failures doesn’t necessarily help you anticipate and prevent something that has never happened. Inductive reasoning is powerful when there is a lot of data to draw from, but we work very hard to prevent failures that are often the source of that data.
In general, our approach to reliability over the last fifteen years has aimed at ensuring that our systems behave correctly and consistently according to the way we designed it.
The future of SRE, leveraging systems thinking, will address a second and even more fundamental question: is “the way we designed it” correct? Answering this question requires a new approach.
The first time system designs challenged their creators' ability to understand them was in the early twentieth century. Sophisticated guidance systems, electronic computers, rockets, and radars all pushed engineers beyond what the traditional tools of component analysis, manual adjustments based on observed outputs, and trial and error could handle. In response, a new field emerged at the intersection of mathematics, engineering, and systems thinking: control theory. Today, as we navigate an increasingly complex world of autonomous systems, adaptive networks, and AI- and ML-powered systems, the principles of control theory developed in those formative post-war years continue to provide the theoretical backbone for managing and optimizing systems across diverse fields.
Leveson's groundbreaking work on STAMP in the early 2000s represented a paradigm shift in system safety. Building upon the foundations laid by cybernetics pioneer Norbert Wiener and control theorists like Rudolf Kalman, Leveson recognized that safety is an emergent property that can only be analyzed at the system-level, rather than an attribute of individual system components. STAMP applies control theory principles to safety engineering, viewing accidents not as a chain of events, but as complex interactions between system components, including human operators and software. Today, Leveson's STAMP methodology offers a robust framework for understanding and mitigating risks in complex socio-technical systems, demonstrating the enduring relevance and adaptability of control theory principles in our rapidly evolving technological landscape.
In "An Introduction to Cybernetics," W.R. Ashby lays out the fundamental requirements for control, which Leveson later incorporated into her STAMP methodology. Leveson recognized the relevance of these cybernetic principles to system safety and adapted them for use in analyzing system safety.
"In order to control a process, four conditions are required:
Goal Condition: The controller must have a goal or goals (for example, to maintain the setpoint).
Action Condition: The controller must be able to affect the state of the system. In engineering, actuators implement control actions.
Model Condition: The controller must be (or contain) a model of the system.
Observability Condition: The controller must be able to ascertain the state of the system. In engineering terminology, observation of the state of the system is provided by sensors."
These four conditions provide a structured way to think about control in complex systems. When applying STAMP to our SRE practices, we can use these conditions as a checklist to ensure we have the necessary elements in place for effective control.
A prevalent way of explaining the cause of an outage at Google is as a linear sequence of failures. As we'll show, this type of causality model has limitations when analyzing system safety. Sentences like, "a bug combined with insufficient rate limits, caused thousands of servers to go offline" abound in our postmortems. We don't explicitly call out our use of a linear chain causality model, but as Leveson writes, "accident models explain why accidents occur, and they determine the approaches we take to prevent them. While you might not be consciously aware you are using a model when engaged in these activities, some (perhaps subconscious) model of the phenomenon is always part of the process." (Leveson 2012, 15)
Many problems stem from choosing an inadequate causality model. If we see outages as the result of a branching chain of events then the obvious solution is to break the chain before the failure. This will inevitably lead us to look for where some component failed—where the software had a bug, or a server crashed, or was overloaded with traffic—and work to prevent that failure. We'll add redundancy, or rework the server to be more reliable, or introduce failure isolation, or add tests to catch problems. These techniques will all work, but only up to a point. We haven't addressed any of the larger systemic factors that might reintroduce the problems somewhere else. We have only looked at relationships that are directly related to the outage. Also, picking the first event in the chain (the "root cause") is subjective. When did the outage really begin? When the servers went offline? Or when the rate limits were changed? Or when the bug was introduced? Or when the maintenance operation was first automated? There is an infinite regress problem here.
STAMP shifts our perspective on accidents from a linear chain of failure events to a control problem. We want our model to explain accidents that result from component failures (like server crashes and buggy automation), but also external disturbances (environmental factors in our datacenters or subsea Internet cables), interactions between components of the system (including human-human, human-software, and software-software interactions), and also incorrect or inadequate behavior of individual system components—flawed algorithms or decision making.
Instead of asking "What software service failed?" we ask “What interactions between parts of the system were inadequately controlled?” In complex systems, most accidents result from interactions between components that are all functioning as designed, but collectively produce an unsafe state. If this all seems abstract, don't worry—we're going to tie these concepts together with a real-life example.
Another incredibly important implication of an accident model is that it helps you analyze the time dimension of an accident. In a linear chain, there is a sequence of events laid out over time, but it only describes two states that the system can be in—normal operations, before the last event in the chain occurs and the system has not yet had an accident, and loss operations, after the last event in the chain occurs and the accident begins.
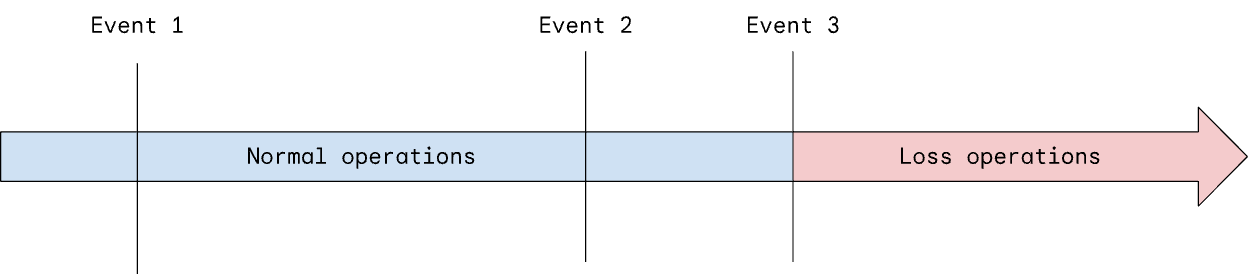
The transition from normal operations to loss operations is typically very sudden—there is almost no time to react to prevent it. This is one reason why SRE uses a combination of fast burn and slow burn SLOs for detecting problems that might be developing but aren't yet at the point of causing real harm. However, these SLOs are normally attributes of individual system components.
STAMP formalizes this concept at the system level as hazard states. "A hazard is a system state or set of conditions that, together with a particular set of worst-case environmental conditions, will lead to a loss [for one or more stakeholders in the system]." (STPA Handbook, 17)
Hazard states are not discrete events. They do not describe anything at the individual system component-level. A hazard state is a property of the system as a whole, and the system can be in a hazard state for a long period of time before an accident occurs. That gives engineers a much larger target to aim at when trying to prevent outages. Rather than trying to eliminate any single failure that could occur anywhere in the system, we work to prevent the system from entering a hazard state. And if we do enter a hazard state, if we can detect it and take action to transition from the hazard state back to normal operations, we can prevent any accident from occurring. In some cases, the system is in a hazard state for a long time—a bug is introduced but never triggered, an alert fires but no one receives it, a server is underprovisioned but suddenly receives traffic from a popular new product feature, etc.

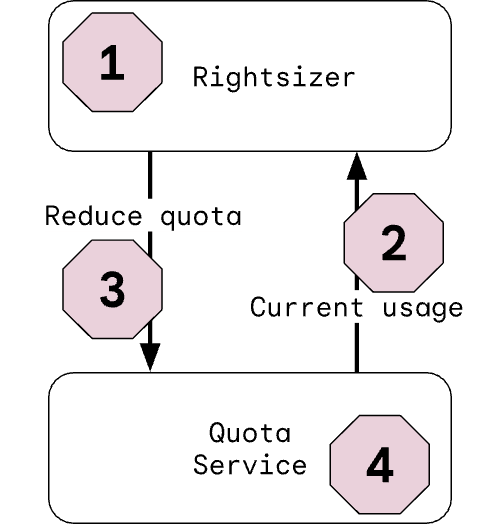
An example of this phenomenon occurred at Google in 2021. We set and enforce resource quotas for some kinds of internal software running on our infrastructure. To maximize efficiency, we also monitor how much of its quota each software service uses. If a service consistently uses less resources than its quota, we automatically reduce the quota. In STPA terms, this quota rightsizer has a control action to reduce a service's quota. From a safety perspective, we then ask when this action would be unsafe. As one example, if the rightsizer ever reduced a service's quota below the actual needs of that service, it would be unsafe—the service would be resource-starved. This is what STPA calls an unsafe control action (UCA).
STPA analyzes each interaction in a system to determine comprehensively how the interaction must be controlled in order for the system to be safe. Unsafe control actions lead to the system entering one or more hazard states. There are only four possible types of UCA:
A required control action is not provided.
An incorrect or inadequate control action is provided.
A control action is provided at the wrong time or in the wrong sequence.
A control action is stopped too soon or applied for too long.
This particular unsafe control action—reducing an assigned quota to be less than what the service requires—is an example of the second type of UCA.
Simply identifying this unsafe control action by itself is only partially useful. If "quota rightsizer reduces the assigned quota under what the service requires" is unsafe, then preventing that behavior is what the system must do, i.e. "quota rightsizer must not reduce the assigned quota under what the service currently requires." This is a safety requirement. Safety requirements can be very useful for formulating future designs, elaborating testing plans, and helping people understand the system. And let’s be honest—even mature software systems can operate in ways that are undocumented, unclear, and surprising.
Nonetheless, what we really want is to anticipate all of the concrete scenarios that lead to a hazard state. Again, STPA has a simple and comprehensive way to structure an analysis to find all of the scenarios that could lead the quota rightsizer to violate this safety requirement.
So in the case of the rightsizer, there are four archetypal scenarios that we can investigate.
Scenarios in which the rightsizer has incorrect behavior.
Scenarios in which the rightsizer gets incorrect feedback (or no feedback at all).
Scenarios in which the quota system never receives an action from the rightsizer (even though the rightsizer tried to send one).
Scenarios in which the quota system has incorrect behavior.
One specific scenario quickly jumped out to us when analyzing the rightsizer. It gets feedback on the current resource usage from the quota service. As implemented, the calculation of current resource usage is complicated, involving different data collectors and some tricky aggregation logic. What if something went wrong with this complex calculation, resulting in a value that was too low? In short, the rightsizer would react exactly as designed and reliably shrink a service’s quota to the incorrect lower usage level.
Exactly the disaster we wanted to prevent.
Up to this point, lots of attention had been paid to getting the quota adjustment algorithm right and reliably producing the correct outputs, namely, the action to adjust a service’s quota. However, the feedback path—including the service’s current resource usage—had been less well understood.
This highlights a major advantage of STPA—by looking at the system level and by modeling the system in terms of control-feedback loops, we find issues both in the control path and the feedback path. As we run STPA on more and more systems, we see that the feedback path is often less well understood than the control path, but just as important from a system safety perspective.
As we dug into the feedback paths for the rightsizer, we saw many opportunities to improve them. None of these changes looked like a traditional reliability solution—it didn’t boil down to managing the rightsizer with a different SLO and error budget. Instead, the solutions showed up in other parts of the system and involved redesigning parts of the stack that had previously appeared to be unrelated–again, an advantage of STPA’s system theory approach.
In the 2021 incident, incorrect feedback about the resources used by a critical service in Google's infrastructure was sent to the rightsizer. The rightsizer calculated a new quota, allocating far fewer resources than the service was actually using. As a precautionary measure, this quota reduction was not immediately applied, but was held for several weeks to give time for someone to intervene in case the quota was wrong.
Of course, major incidents are never simple events—the next problem was that despite adding the delay as a safety feature, feedback about the pending change was never sent to anyone. The entire system was in a hazard state for weeks, but because we weren't looking for it, we missed our chance to prevent the loss that followed. After several weeks, the quota reduction was applied resulting in a significant outage. Using STPA, we have anticipated problems just like this one in many different systems across Google.
As Leveson writes in Engineering a Safer World: "In [STAMP], understanding why an accident occurred requires determining why the control was ineffective. Preventing future accidents requires shifting from a focus on preventing failures to the broader goal of designing and implementing controls that will enforce the necessary constraints." This shift in perspective - from trying to prove the absence of problems to effectively managing known and potential hazards - is a key principle in our system safety approach.
Rather than seeing complexity as a bug, SRE teams at Google are leveraging control theory and methods like STPA and CAST to lead us to more comprehensive and proactive approaches to reliability, moving beyond simply reacting to failures to actively designing safer systems from the ground up.
We have analyzed some of Google's most complex systems with STPA, and with relatively little effort (think: engineer-weeks of work per analysis), we have found hundreds of scenarios with a wide range of impacts. Because we found these scenarios before they led to an outage, we were able to mitigate them with a combination of quick "band-aid" fixes and much more carefully planned software engineering, leveraging the regular planning process across Google to make the system safer while also minimizing the costs and disruptions associated with the work. Our ongoing work is focused on extremely complex Google Cloud systems, Google's massive internal networking systems, and multiple Google products.
The success of SRE at Google has always been due to the amazingly talented engineers who have worked 24/7 to ensure that Google's products work at scale. Dedication, ingenuity, and lots of hard work have made Google's products the benchmark for high reliability and performance. The evolution of SRE towards system safety methods gives our engineers an entirely new way to understand the systems we build, and provides us even stronger guarantees about how they work. Complexity is increasing everywhere, and Google's engineers will be ready to face it in order to provide the same exceptional performance in the next era.

