Data-only attacks, those that do not affect a program’s control flow, have long been considered too sophisticated and niche to pose a practical threat. With our research, however, we have built a tool that automatically generates them with surprising ease. We explain how such attacks work, and why our tool, Einstein, calls upon both researchers and vendors alike to rethink their mitigation strategies.
Suppose you are a hacker and you just found a bug that allows you to overwrite data in a victim program. Such a scenario is not uncommon: Microsoft, Google, and Mozilla report that about 70% of their security bugs are indeed such memory safety bugs [1, 2, 3]. The question then becomes, as a hacker, how do you weaponize this bug into a real exploit?
In the past, it would have been relatively straightforward: you could, for example, use the bug to conduct a control-flow hijacking attack, overwriting code pointers in the program [4], forcing it to execute your own malicious code. However, due to decades of research (resulting in defenses such as DEP, CFI, CPI, etc.), it is now very difficult to divert a program’s control flow away from the code that it intends to execute. Hence, weaponizing the bug in such a way is now often infeasible in practice.
In our recently published paper at USENIX Security 2024 [5], we present a practical approach to an entirely different method of exploitation: letting the program execute all of its intended code (e.g., any benign functions, system calls, etc.), but with malicious data. These so-called data-only attacks have been known for quite some time [6], but were assumed to be too application-specific or complex to pose any practical threat [7]. In our work, we show that such assumptions are not justified. In particular, we implemented a scalable and automated solution, Einstein, that demonstrates that building data-only attacks is easy — well within reach of low-effort attackers. In this article, we will discuss the insights that allow Einstein to automatically generate such exploits with surprising ease, and the implications of our findings on software vendors.
Let us first walk through one of the classic data-only attacks described in the literature, which exploits a victim web server [6] (simplified for clarity). At start up, the server reads its configuration file to initialize its data. One such configuration option is the CGI-BIN path, which is the directory it uses to execute external programs. In our example, the server sets its cgi_bin_path variable to "/usr/local/server/cgi-bin". We assume that the server has a program in its CGI-BIN directory, sort_script, that a client can use to sort numbers. Moreover, the server has a memory safety bug that allows a malicious client to overflow some buffer and overwrite, for instance, the contents of the cgi_bin_path variable to "/bin":
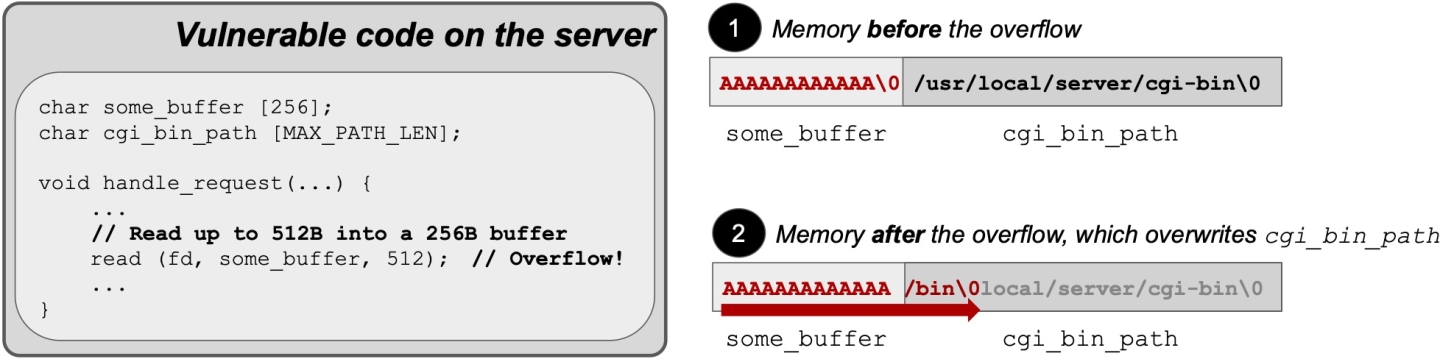
Of course, the low-level details of the memory safety bug could differ from this (e.g., it could be a use-after-free rather than a buffer overflow), but nonetheless, the question arises: how could an attacker weaponize such a bug? To answer this question, we will show first how the server interacts with a benign client, then how it interacts with a malicious client:
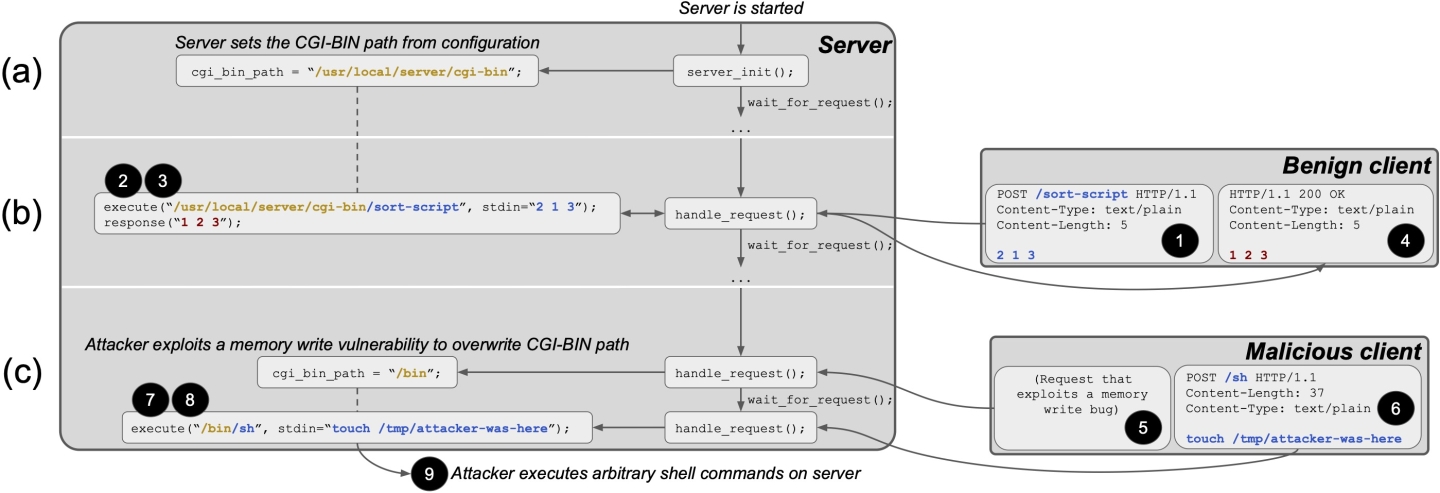
After the server initializes (Fig. 2a), it begins processing requests. A benign client interacts with it as follows (Fig. 2b):
- ➊ The client sends a “POST sort-script” request with the unsorted numbers “2 1 3” in the request body.
- ➋ The server concatenates the CGI-BIN path and the request’s path to determine the program to be executed, “/usr/local/server/cgi-bin/sort-script”.
- ➌ The server executes the program, i.e., the sort script, and passes in “2 1 3” as its input. It does so by invoking the execve system call, which instructs the operating system to run the script on behalf of the server.
- ➍ The script sorts the numbers and outputs “1 2 3”, which the server forwards to the client in its HTTP response.
Let us now sketch how a malicious client could exploit this (Fig. 2c):
- ➎ The client exploits the bug to set the cgi_bin_path to the string “/bin” (Fig. 1).
- ➏ The client sends a “POST /sh” request with “touch /tmp/attacker-was-here” in the request body.
- ➐ The server concatenates the CGI-BIN path and the request’s path to determine the program to be executed, “/bin/sh”.
- ➑ The server executes the program, i.e., the system shell, and passes in “touch /tmp/attacker-was-here” as its input. It does so by invoking the execve system call, which instructs the operating system to run the shell on behalf of the server.
- ➒ The shell creates the file /tmp/attacker-was-here.
First, the victim server does not execute any malicious code provided by the client; all harmful actions are triggered by malicious data. The attack effectively modifies only the arguments of the execve syscall. Other than that, the benign and malicious executions are equivalent — when handling a request, the victim server performs the same steps, and executes the same functions, albeit with different arguments.
Second, this attack is very powerful, as it allows the attacker to execute arbitrary programs on the victim machine. In our example, the client only creates the file /tmp/attacker-was-here, but any shell command is possible, e.g., to install a malicious program or to exfiltrate data.
Despite the discovery of data-only attacks almost two decades ago, conventional wisdom says they rarely pose a practical threat, either because they are too application-specific or too complex.
Application-specific. As pointed out by the authors of the example attack, building such an attack “require[s] sophisticated knowledge about program semantics”. In other words, an attacker has to become so familiar with the server’s inner-workings — either through reverse-engineering its code, or studying its protocols, etc. — that they know that out of all the program’s data, the cgi_bin_path variable specifically is security-critical, and that a POST request that is malformed in a very specific way can exploit it. In all likelihood, this kind of labor-intensive, application-specific analysis is prohibitively expensive, and hence, according to conventional wisdom, such data-only attacks are too niche to pose a practical threat.
Complex. Recent approaches to building data-only attacks foray into complex territory, under the assumption that simpler attacks — such as the example attack — are not generally at reach. In particular, they assume the need either to solve complex data-flow constraints using heavyweight analyses, or to deviate the victim program away from the code it intends to execute to circumvent a variety of defenses. Several approaches even go so far as to construct highly complicated, Turing-complete machines — something real-world attackers rarely need.
Exploitation requires neither extensive knowledge of the program semantics, nor the solving of complex data-flow constraints, nor the diversion of the control flow in a complicated (or even any) way.
Inspired by the quote attributed to Albert Einstein, we present a simple (but not too simple) data-only attack exploitation pipeline, named Einstein, that builds attacks with surprising ease. It generates data-only attacks using an application-agnostic technique, proving that such attacks are well within reach of low-effort attackers.
Application-agnostic. Rather than attempting to understand application-specific semantics (e.g., the corner cases of the HTTP protocol), Einstein targets a universal interface used by any program to communicate with the operating system kernel: its syscalls. In particular, we track the data that ends up in syscall arguments, determining whether an attacker can corrupt them to e.g., execute arbitrary code via execve or modify files in the filesystem via write.
Simple. Moreover, Einstein abstracts away unnecessary complexities and, instead, targets the exploits that are not only the simplest to identify, but also the most promising for an attacker. In particular, Einstein automatically generates exploits for the security-sensitive syscalls along a program’s (already valid) runtime path, and whose arguments are (simply) copied verbatim from attacker-controllable data. As detailed later, this simple approach can automatically generate a surprisingly large number of practical data-only exploits in popular real-world programs.
How Einstein builds the example attack
To explain how Einstein works, we walk through each step of how it builds the example attack and how it crafts the arguments of a security sensitive system call. We assume that the attacker has access to a program that is equivalent to the one deployed by their prospective victim, so they can run the server locally for analysis. Einstein takes the victim program as input, and operates in two stages: first, it generates candidate exploits; and second, it confirms whether each candidate exploit is indeed a working exploit. For an explanation of the finer points of the design beyond the scope of this example — e.g., how Einstein tracks unbounded data, chains together multiple syscalls, etc. — please refer to our paper [5].
Candidate exploit generation. To generate candidate exploits, Einstein tracks all attacker-corruptible data at runtime, determining which can influence the arguments of security-sensitive syscalls. To facilitate this, we first start the server with Einstein’s binary-level instrumentation (Fig. 3a, ➊). The instrumentation adds support for dynamic taint analysis, which allows us to track any “tainted” program data at runtime [8]. The server starts up, initializes its cgi_bin_path, and starts waiting for requests. Einstein models an attacker exploiting the memory safety bug by uniquely tainting any data that it could potentially corrupt, e.g., the string “/usr/local/server/cgi-bin”, but also all other data within reach of it. Additionally, we record the tainted data in a memory snapshot (➋).
Next, Einstein continues executing the program and tracks how the tainted data propagates throughout the program’s execution as the server handles a workload consisting of benign requests (➌). For instance, it sends the “POST /sort-script” request from Fig. 2b. Then, while handling the request, the server passes the tainted string as an argument to the execve syscall. Einstein identifies this flow of attacker-controllable data into a security-sensitive syscall, and records information about it, such as the arguments and their taintedness (➍).
Then, Einstein determines that execve’s pathname and argv parameters are not only tainted with an identifier that corresponds to cgi_bin_path, but they are in fact identical to cgi_bin_path. We refer to this kind of (very) straightforward data flow as an identity data flow. Einstein builds a candidate exploit for the identity data flow by generating (address, value) pairs that specify that the memory write bug could exploit the execve by overwriting the cgi_bin_path from "/usr/local/server/cgi-bin" to "/bin" (➎).
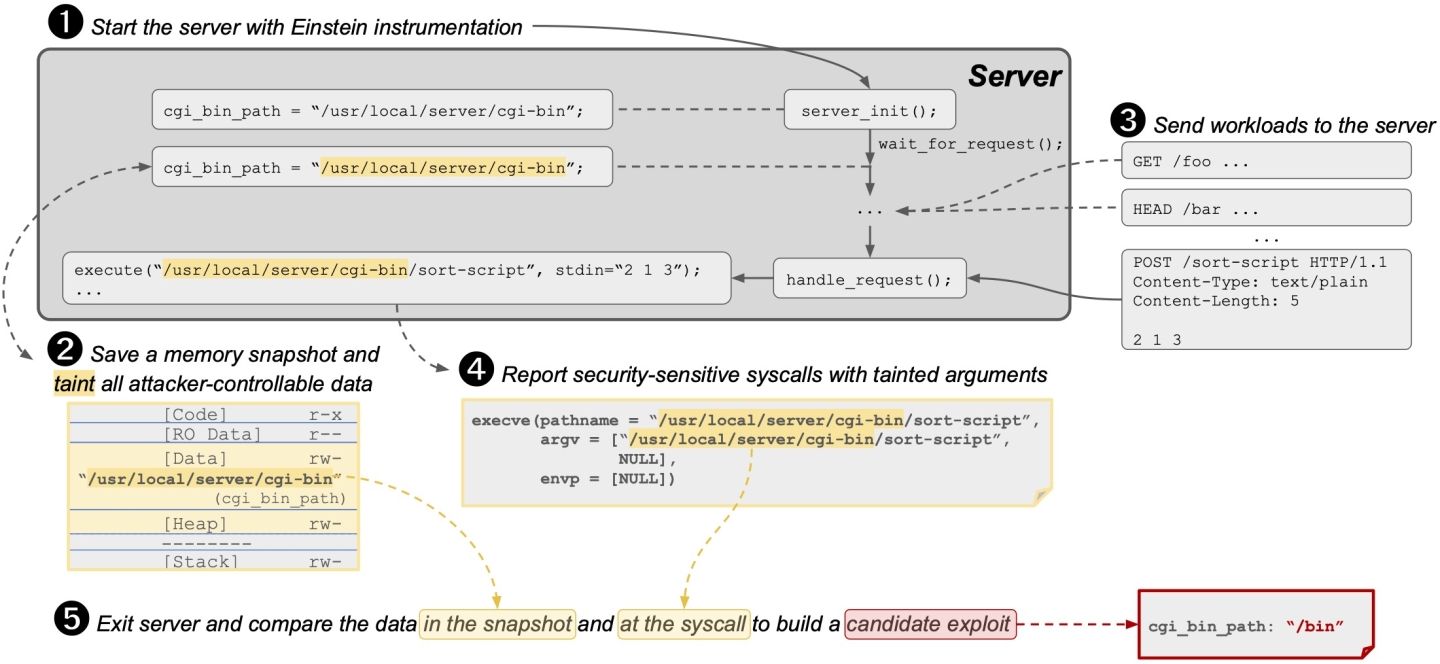
Exploit confirmation. Even though we have identified an identity data flow from attacker data into a syscall argument, we are not guaranteed that it is necessarily exploitable. For example, before executing the file, the server may double-check that it is within some preset, hard-coded directory, thereby mitigating the vulnerability. Hence, we confirm whether each candidate exploit is indeed a working exploit.
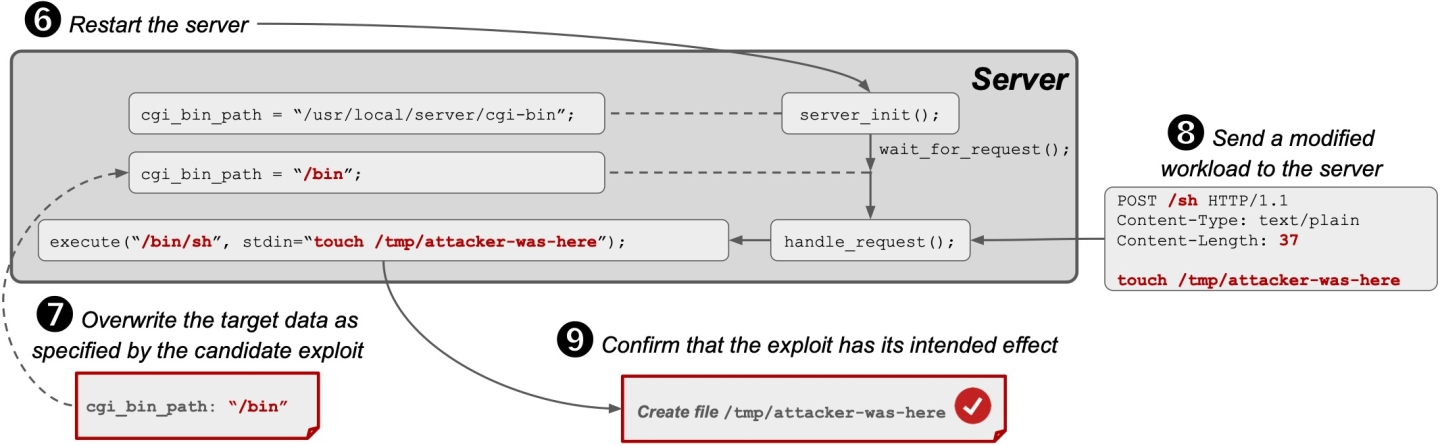
To confirm the exploit, we first restart the server (Fig. 3b, ➏). Then, at the point where an attacker may exploit the memory write bug, Einstein overwrites the data that is specified by the candidate exploit, changing cgi_bin_path to "/bin" (➐). Next, we send a workload to exploit the gadget — in this case, a “POST /sh” request with a shell command to create a file (➑). Finally, Einstein confirms that the file is indeed created, thereby confirming that the candidate exploit is indeed a working exploit (➒).
Evaluation
We have seen how Einstein can automatically build the example attack from almost two decades ago. Now, let us see how it performs against popular servers today. Although we follow previous work by targeting server applications, we note that other types of applications (e.g., those with more limited user-input interaction and few obviously dangerous syscalls) may well be at risk.
We target the web servers httpd, lighttpd, and nginx; and the database servers postgres and redis — all of which have been shown to be at risk of weaponizable memory write bugs. To generate workloads for the target servers, we use their test suites. Moreover, because nginx is a common target for exploitation case studies, we confirm the candidate exploits that Einstein generates for nginx.
We first refer to Table 1, which presents the number of attacker-tainted syscalls per target program, and the percentage of those that have an identity data flow from attacker data. We observe that an attacker may corrupt many security-sensitive syscall arguments, and (with the exception of postgres) the high rate of identity flows (84–98%) allows us to generate candidate exploits for the vast majority of them. We refer to our paper [5] for a full breakdown per syscall argument. Despite the test suites generating relatively low code coverage (27–49%), Einstein still uncovers many security-sensitive issues. Further work into increasing coverage would undoubtedly yield even more dire results.
| Target program | Security-sensitive syscalls with tainted arguments (% with an identity data flow from attacker data) | Code coverage |
|---|---|---|
| httpd | 1834 (97%) | 27.3% |
| lighttpd | 92 (98%) | 27.8% |
| nginx | 1623 (82%) | 49.1% |
| postgres | 2105 (27%) | 46.5% |
| redis | 218 (84%) | 33.6% |
Next, we refer to Table 2, which presents the number of confirmed exploits for nginx. We observe that the exploits offer many primitives to attacker: a vulnerable execve gives us a Code-Execution primitive, vulnerable file-configuring syscalls (e.g., openat) combined with vulnerable file-write syscalls (e.g., write) give us 17 Write-What-Where primitives, vulnerable socket-configuring syscalls (e.g., connect) combined with vulnerable socket-write syscalls (e.g., sendmsg) give us 41 Send-What-Where primitives, etc. We refer to our paper for a description of two such exploits that bypass state-of-the-art mitigations [5]. Despite conventional wisdom dictating that data-only attacks are too complex or too niche to be practical, we can conclude that an attacker indeed has a diverse set of primitives at their disposal against popular server programs, even today.
| Attack Primitive | Count |
|---|---|
| Code-Execution | 1 |
| Write-What-Where | 17 |
| Write-What | 375 |
| Write-Where | 79 |
| Send-What-Where | 41 |
| Send-What | 372 |
| Send-Where | 59 |
| Total | 944 |
We presented Einstein, a data-only attack exploitation pipeline, which automatically builds exploits against popular servers and bypasses state-of-the-art mitigations. The question, then, is how do we properly mitigate such attacks? To answer this, let us consider two features that a proper mitigation would provide: (1) comprehensiveness, i.e., mitigating an attack surface entirely; and (2) practicality, i.e., requiring little effort to deploy, and, therefore, being more amenable to practical adoption.
For control-flow hijacking attacks in the old days, the parameters were relatively well-defined: they would typically overwrite a code pointer, which would then corrupt an indirect branch (e.g., a return instruction). Hence, the mitigations for such attacks (e.g., DEP, CFI, CPI) can generally afford to be both comprehensive and practical.
On the other hand, data-only attacks present a unique challenge: they may overwrite any data (not just code pointers), which may then corrupt any operation (not just indirect branches, or even syscalls, for that matter). Hence, the mitigations for such attacks can generally afford only to be either comprehensive or practical. That is, comprehensive defenses (e.g., memory safety, DFI) are impractical, because they either incur poor performance or require onerous changes in the software or hardware. Meanwhile, practical defenses (e.g., memory error scanning, selective DFI, syscall filtering) are noncomprehensive, because, as Einstein demonstrates, they leave part of the attack surface vulnerable.
Generating exploits that trivially bypass the practical defenses, Einstein highlights that vendors should strongly consider deploying one or more of the comprehensive defenses. Vendors may also use Einstein to mitigate vulnerabilities on a case-by-case basis, however, a general solution — e.g., by making the comprehensive defenses more practical — poses a pressing direction for future research.



