Not long ago, the idea of an “AI assistant” inside a build pipeline sounded like science fiction. Code copilots in editors were one thing, but plugging an LLM into CI/CD — the sacred path from commit to deploy — seemed reckless. And yet, as AI gained traction in developer workflows, I found myself wondering: could an AI help us after code was pushed, not just before? Could it speed reviews, flag risks, or even generate quick fixes?
This article is about what happened when I tried. Spoiler: the assistant was neither a magic bullet nor a catastrophe — but it forced me to rethink what “reliability” means when your build system starts talking back.
To keep the story clear and accessible, here are the key terms as I’ll use them:
- Pull Request (PR): A code change proposal submitted for review before merging into the main branch.
- CI/CD: Continuous Integration / Continuous Deployment. Automated processes that build, test, and deploy software.
- Inline vs. Async AI: Inline means the AI runs in the critical path of the build pipeline (blocking progress). Async means the AI runs after the build completes, posting results separately.
- Validator: A lightweight check that confirms or downgrades AI suggestions (e.g., using linters or static analyzers).
- Guardrails: The safety mechanisms (validation, circuit breakers, cost controls) that make AI outputs reliable in production environments.
- Hallucination: When an AI confidently generates a suggestion that is factually wrong or doesn’t exist (e.g., recommending a package that isn’t real).
I work on a large-scale, cloud-native platform with micro-frontends, data pipelines, and search clusters serving millions of requests daily. Velocity matters: every week, dozens of Pull Requests (PRs) merge, triggering tests, builds, and deployments. I already used AI locally for code generation and review, but the bottleneck was further down:
- Pull Request (PR) reviews sometimes stalled waiting for a human to weigh in.
- Test coverage lagged for edge cases.
- Deployment checks often required repetitive validation.
The idea was simple: insert an AI assistant into the CI/CD path, where it could:
- Add comments to PRs (flagging risky changes).
- Suggest unit tests for uncovered code paths.
- Annotate release logs with potential issues.
It sounded futuristic, but achievable.
Here’s how I imagined the flow:
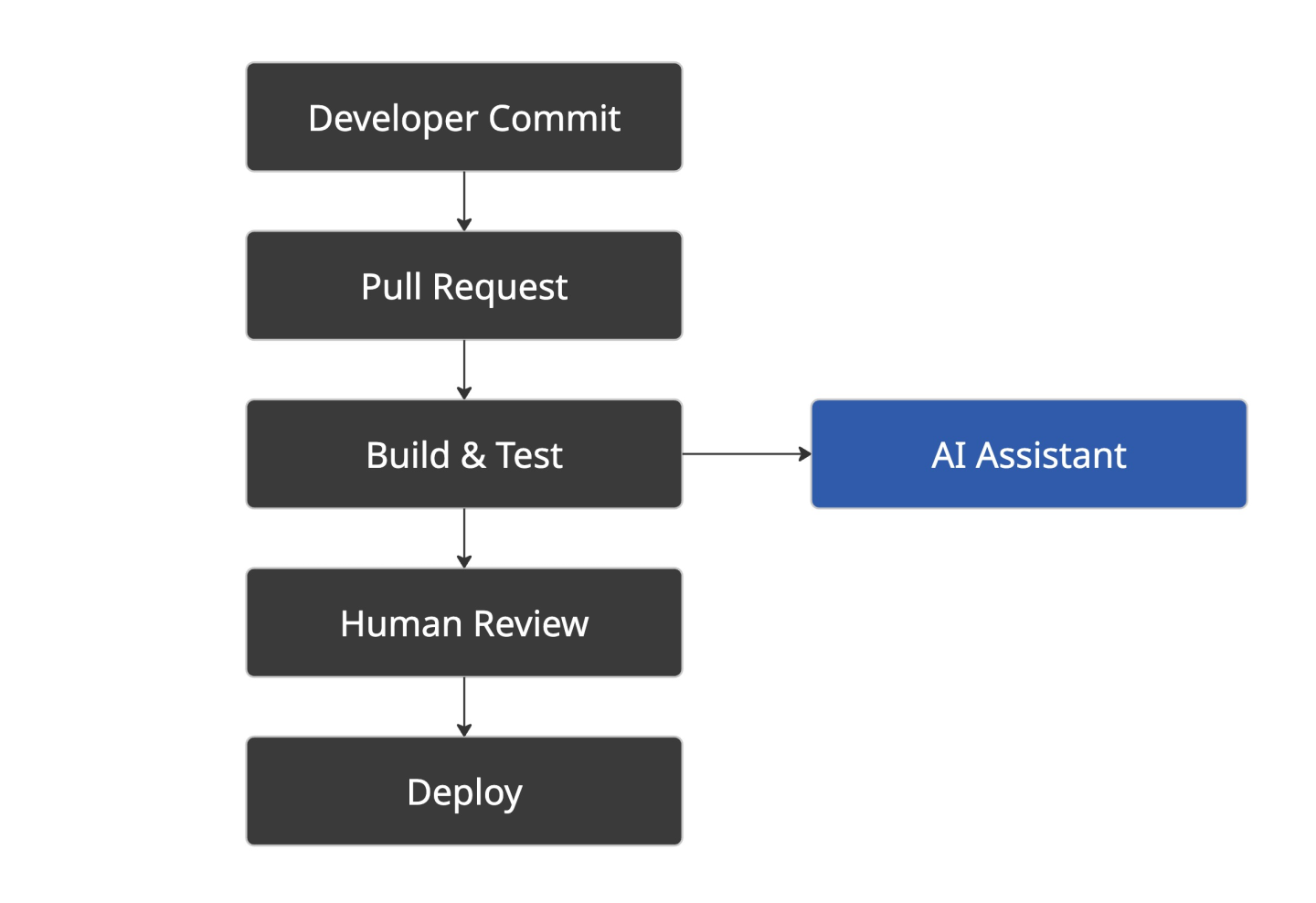
At this stage, the AI assistant was just another hook in the pipeline. Things didn’t go so smoothly.
I didn’t ship a Copilot-in-the-cloud. I added an untrusted decision-maker into a safety-critical path. Predictably, it bit me.
1) Confidently wrong reviews (hallucinated diffs)
Symptom: PR comments flagging issues that didn’t exist.
AI: ❌ "Line 3: The import 'pandas' is unused — please remove it."
import pandas as pd
def transform(data):
return pd.DataFrame(data) # <-- clearly used here
Cause: The model guessed based on patterns, not actual analysis.
Fix: Treat AI comments as advisory unless validated.
2) Latency cliffs in the critical path
Symptom: Pipeline runtime jumped from ~8 minutes to 18–22 minutes.
Cause: Token-heavy prompts, retries, and inference delays.
Fix: Move AI off the critical path and add circuit breakers.

3) Cost spikes
Symptom: “Pennies per call” turned into runaway bills at scale.
Cause: Dozens of PRs × multiple prompts × retries.
Fix: Rate limiting, token caps, and auto-disabling when thresholds exceeded.
4) Bad suggestions in unfamiliar stacks
Symptom: In one case, the AI confidently recommended adding Jest (a JavaScript testing framework) in a repository that wasn’t even using JavaScript.
Fix: Add a repo profile to prompts and enforce stack guards to prevent stack mismatches.
5) Extra burden on reviewers
Symptom: Reviewers felt obligated to fix every AI suggestion.
Fix: Mark AI feedback as “[Advisory]” unless validated.
6) Risky release note summaries
Symptom: AI hallucinated a breaking change:
AI Release Notes: "⚠️ Breaking change: API endpoint /v2/search removed"
Reality: Endpoint still existed — AI inferred this from a refactor.
Fix: Only summarize merged commits; require human sign-off on version bumps.
Guardrails turned an interesting demo into a production-worthy tool. The theme: async first, validate everything, fail safe.
Validation as First-Class
AI output is untrusted input. I built cheap, layered checks to keep noise out:
- Static analysis confirmation (linters, type checkers).
- Test oracles (run test suites on AI-generated tests).
- Stack guards (reject mismatched tools).
- Dependency checks (verify existence, allow-list).
- Security gates (block unsafe code suggestions).
# scripts/validate_ai_suggestions.py
import subprocess
def is_unused_import_real(py_files):
r = subprocess.run(["flake8", "--select=F401", *py_files],
capture_output=True, text=True)
return "F401" in r.stdout
def matches_repo_profile(suggestion, profile):
if "jest" in suggestion.lower() and profile["lang"] != "javascript":
return True
return False
def validate(ai_comment, changed_files, profile):
issues = []
if "unused import" in ai_comment.lower() and not is_unused_import_real(changed_files.get("py", [])):
issues.append("unused-import-hallucination")
if matches_repo_profile(ai_comment, profile):
issues.append("stack-mismatch")
return issues
Example flow:
AI: ❌ "Null pointer possible at line 128."
Validator: ⚠️ Could not confirm with static analysis.
Posted: [Advisory] Possible null pointer (unconfirmed).
Async, Not Inline
Inline inference killed velocity. I moved AI to an async path: if build and tests passed, a bot posted AI comments afterward.

# .github/workflows/pr-ai-review.yml
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm ci && npm test
ai-review:
needs: build
if: needs.build.result == 'success'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Generate AI Review
run: |
python scripts/ai_reviewer.py \
--pr ${{ github.event.pull_request.number }} \
--out comments.json
- name: Validate & Post
run: |
python scripts/validate_and_post.py comments.json
Circuit Breakers
When using the LLM model to check an update, if cost or latency thresholds were exceeded, the AI stage automatically disabled itself until manually reset. This prevented runaway GPU spend.
#!/usr/bin/env bash
set -euo pipefail
START=$(date +%s)
MAX_SEC=30
resp=$(ai-cli generate "$@" || true)
ELAPSED=$(( $(date +%s) - START ))
if [ $ELAPSED -gt $MAX_SEC ] || [ -z "$resp" ]; then
echo "AI step skipped (elapsed=${ELAPSED}s)" >&2
exit 0
fi
printf "%s" "$resp"
Before diving into the comparison, it’s worth grounding this with a few quick checks. In practice, the difference between a useful AI suggestion and a hallucination often came down to simple tests: running a suggested edge-case test, verifying whether a dependency actually existed, or confirming with static analysis. These small validations highlighted the split between genuine value and misleading noise.
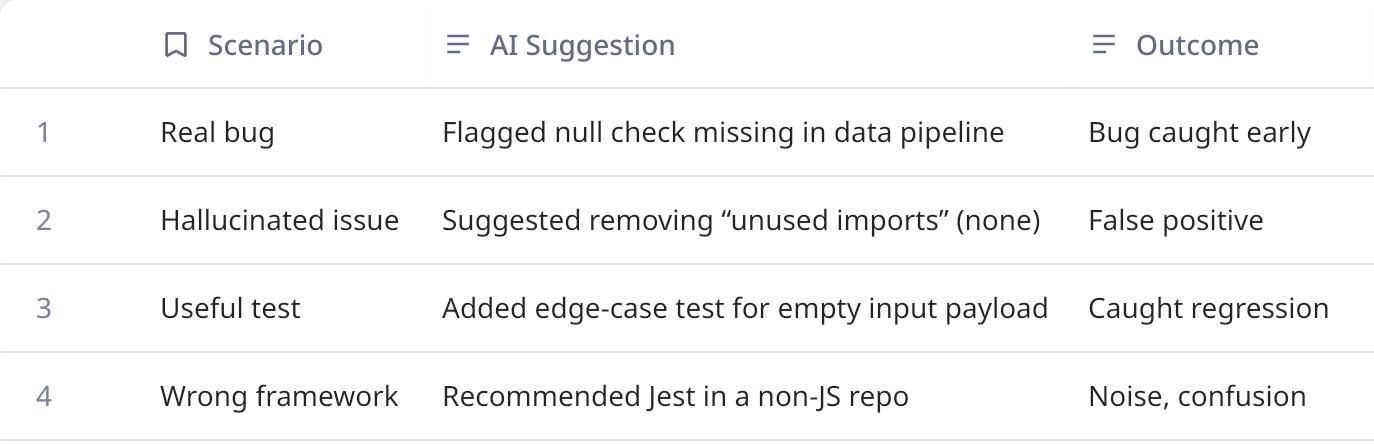
- Test Suggestions. One AI-generated test saved me:
def test_empty_input_payload():
result = transform([])
assert result == []
This trivial case revealed a regression where the transform function blew up on empty lists.
- Release Notes. AI summaries sped up QA and PM handoffs.
- Knowledge Transfer. Junior developers used AI comments flagged as “[Advisory]” as prompts to learn.
- AI is untrusted input. Validate before acting.
- Don’t block pipelines. Async keeps velocity.
- Guardrails are mandatory. Cost/latency breakers are non-negotiable.
- Expect culture shock. Engineers need clear guidance.
- Focus on leverage. Release notes + tests delivered ROI.
Putting AI in a CI/CD pipeline isn’t about automating developers out of the loop. It’s about augmentation — faster feedback, better documentation, more edge cases caught. But without guardrails, the costs (latency, money, trust) outweigh the benefits.
The real lesson: when your build system starts talking back, treat it with the same skepticism you’d give any external service. Trust, but verify. And never forget that reliability is the first feature.
