“Security is a reliability problem.”
– Common wisdom in modern DevSecOps culture
Site Reliability Engineering (SRE) is about keeping systems fast, available, and trustworthy. In today's world of cloud computing and microservices, reliability now means more than just preventing downtime—it also involves defending against security threats and keeping data safe. Security problems, like DDoS attacks or identity breaches, can harm your system’s reliability as much as technical errors or outages. When either happens, users lose trust and your service’s reputation suffers.
This is why SecSRE is important: it’s an approach where security and reliability work together. The goal is to build systems that are strong, observable, and protected—so they can keep running well and keep out attackers at the same time.
In the past, security checks happened at the very end of the delivery process. That was fine when systems were simple. But today’s cloud-based, fast-moving systems are too complex for that approach.
Now, security problems happen just as quickly as reliability problems. Both need:
The solution is to build security into every step of the process, not just at the end. This way, issues are spotted earlier, handled faster, and the system stays safer and more reliable.
SecSRE extends the proven SRE toolbox—SLIs and SLOs, automation, observability, chaos testing, and blameless postmortems—to security. This involves:
- Designing secure-by-default architectures that fail safely.
- Integrating continuous security observability into monitoring stacks.
- Automating threat detection and response, similar to performance alerts.
- Stress-testing defenses with controlled chaos experiments.
The result is a system that remains reliable under normal conditions and resilient against attacks, emerging vulnerabilities, and operational surprises.
SecSRE builds on the proven practices of Site Reliability Engineering (SRE), adapting them to strengthen security while preserving reliability.
| SRE Principle | SecSRE Adaptation |
|---|---|
| SLIs & SLOs | Add security-focused metrics like MTTD, MTTR, and patch cadence to track performance. |
| Error Budgets | Use breach budgets to define acceptable security risk exposure. |
| Automation | Embed security checks into CI/CD, configuration management, and Infrastructure-as-Code. |
| Chaos Engineering | Run controlled security failure simulations to test resilience. |
| Blameless Postmortems | Analyze incidents without blame to improve security processes. |
Metrics-Driven Security with Automation & Observability
You can’t improve what you don’t measure — and you can’t measure effectively without automation and observability. Just as SRE teams use SLIs and SLOs to quantify availability, SecSRE applies the same discipline to security — ensuring performance is visible, measurable, and actionable.
“You can’t manage what you can’t measure.” — Common principle reinforced in SecurityScorecard guidance
Security SLIs
Service Level Indicators measure how effectively security objectives are being met:
- Mean Time to Detect (MTTD) – How quickly a security incident is identified.
- Mean Time to Respond (MTTR) – How quickly a detected incident is mitigated or resolved.
- Security Incident Frequency – Number of P0/P1 security incidents over a defined time period.
- Patch Cadence – The speed at which security patches are applied, a proven predictor of security outcomes.
- Control Health – Uptime and availability of critical security controls (e.g., WAF, EDR, SIEM).
“Measurement without analysis and action wastes time and money and contributes to uncertainty and risk rather than reducing them.” — Lance Hayden, IT Security Metrics
Security SLOs
Service Level Objectives turn those indicators into measurable targets:
| Security SLI | Sample SLO |
|---|---|
| Patch latency for critical vulns | 99% patched within 7 days |
| MTTD (Mean Time to Detect) | Detect P0 (critical) attacks within 5 minutes |
| MTTR (Mean Time to Respond) | Mitigate incidents within 30 minutes |
| Control Health | 99.9% uptime for all critical security controls |
Breach Budgets for Security
In reliability engineering, an error budget defines the maximum allowable downtime before corrective action is taken. Security Site Reliability Engineering (SecSRE) adapts this principle to create a breach budget—a measurable threshold for acceptable security risk before remediation work must take priority.
“The inverse of your SLO is your error budget—how much unreliability you are willing to tolerate.” — Google SRE Workbook [1]
“The global average cost of a data breach skyrocketed to $4.88 million in 2024—a 10% increase from the year before, the biggest annual rise since the pandemic.” — IBM Cost of a Data Breach Report 2024 [2]
These figures underscore why breach budgets are essential—they ensure security risks are quantified, tracked, and addressed before they can escalate into costly incidents.
Automation-First Approach
Manual security checks don’t scale in fast-moving environments. SecSRE applies automation to embed security seamlessly into every stage of software delivery, ensuring continuous protection without slowing down innovation.
The DevSecOps Handbook states [3]: “Security must be built into every stage of the software delivery lifecycle — not bolted on at the end.” This philosophy underpins the SecSRE automation strategy, ensuring security is proactive and integrated, rather than reactive and siloed.
Key Practices:
- Security Gates in CI/CD – Automatically fail builds if critical vulnerabilities are detected.
- Continuous Compliance Scans – Identify configuration drift or policy violations without human intervention.
- Observability-Driven Metrics – Collect detection coverage, alert latency, and incident trends to guide breach budget and response improvements.
- Automated Access Governance – Enforce just-in-time (JIT) approvals, auto-expire unused credentials, and flag excessive or privileged permissions in infrastructure and cloud IAM.
- Privilege Escalation Detection – Alert on unusual admin rights or role changes.
- Automated Alerting – Use tuned alerting mechanisms to minimize false positives and reduce alert fatigue.
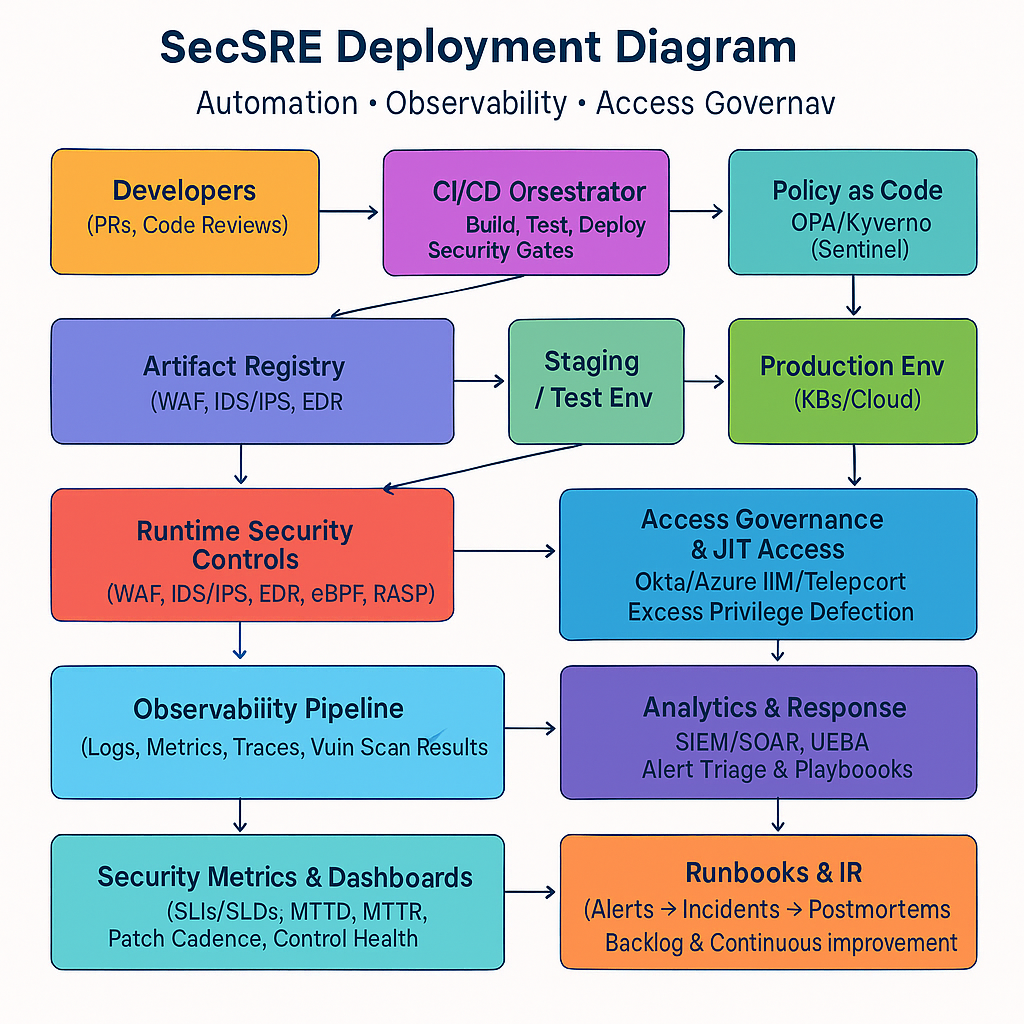
Architecture flow along with the tools used
Chaos Engineering for Security (with Fuzzing)
If chaos engineering helps us uncover reliability weaknesses, it can also reveal hidden security gaps. SecSRE promotes deliberate, controlled security “chaos experiments,” such as:
“GameDay… a project to increase reliability by purposefully creating major failures on a regular basis.” — Jesse Robbins, on chaos engineering in AWS
- Simulating credential leaks – to test detection and response.
- Injecting malicious traffic – to validate intrusion prevention rules.
- Temporarily disabling a security control – to measure fallback mechanisms.
- Running fuzzing campaigns – against APIs, services, and input-handling components to discover unexpected vulnerabilities or crashes before attackers can exploit them.
“You’d define a steady state and your control groups. You’d form your hypothesis… run an experiment… verify the results.” — Crystal Hirschorn
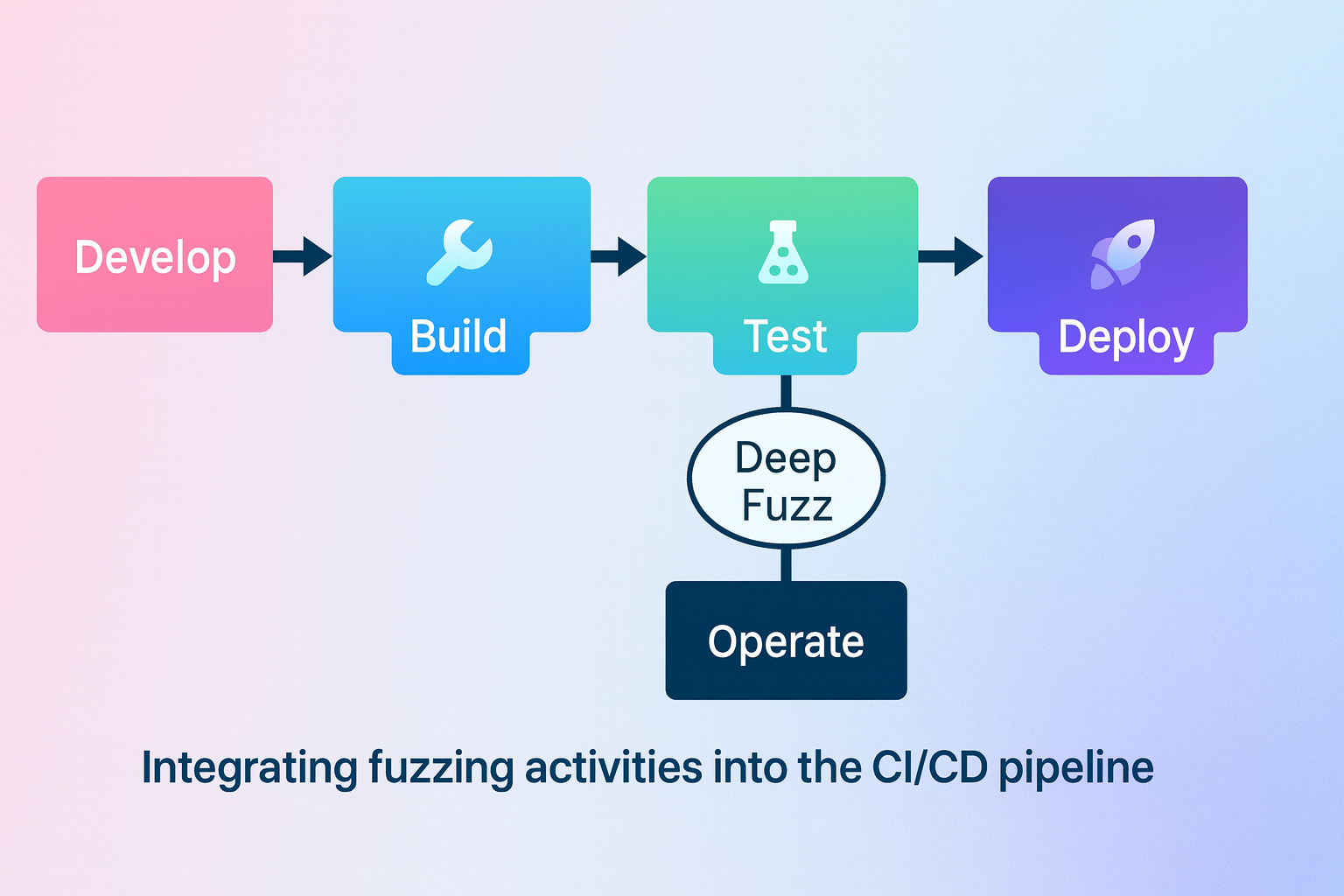
- Code Commit – Developer pushes changes to the repository.
- Automated Build – Pipeline triggers build and dependency checks.
- Static/Dynamic Analysis – Security scanners run for known vulnerabilities (e.g., CVEs, Secrets).
- Deep Fuzzing Stage – Tools like AFL++, OSS-Fuzz, or Jazzer run targeted fuzz tests on binaries or APIs, generating high-volume, randomized inputs to expose edge-case failures.
- Fail on Detection – If critical issues are discovered, the build fails automatically.
- Reporting & Metrics – Results feed into security observability dashboards for tracking detection coverage, time-to-detect, and remediation rate.
Blameless Security Postmortems
In security-centric Site Reliability Engineering (SecSRE), the goal of a postmortem is not to assign fault but to turn every incident into a structured learning opportunity that hardens both systems and teams.
- Structured, Security-Focused Reviews – Every postmortem follows a consistent, security-oriented template that captures timelines, attack vectors, exploited vulnerabilities, control failures, and detection gaps. Ensures repeatable, bias-free analysis and benchmarking against prior incidents.
- Systemic Root Cause Analysis – Focus on system-level weaknesses like policy gaps, configuration drift, insufficient monitoring coverage, or delayed patching, rather than individual mistakes.
- Cross-Functional Collaboration – Security, reliability, and development teams jointly participate, ensuring findings reflect operational realities and remediation plans are feasible and risk-prioritized.
- Actionable, Measurable Outcomes – Each postmortem produces concrete security improvements (e.g., updated detection rules, automated CI/CD guardrails, policy changes) tracked to completion with clear success criteria.
- Organizational Security Memory – Lessons learned are documented in a centralized, accessible repository and periodically reviewed to strengthen resilience and accelerate onboarding for future threats.
Challenges and Ownership in SecSRE
Adopting Security Site Reliability Engineering (SecSRE) blends two traditionally separate worlds—security and reliability. The payoff is huge, but so are the challenges.
1. Defining Responsibility
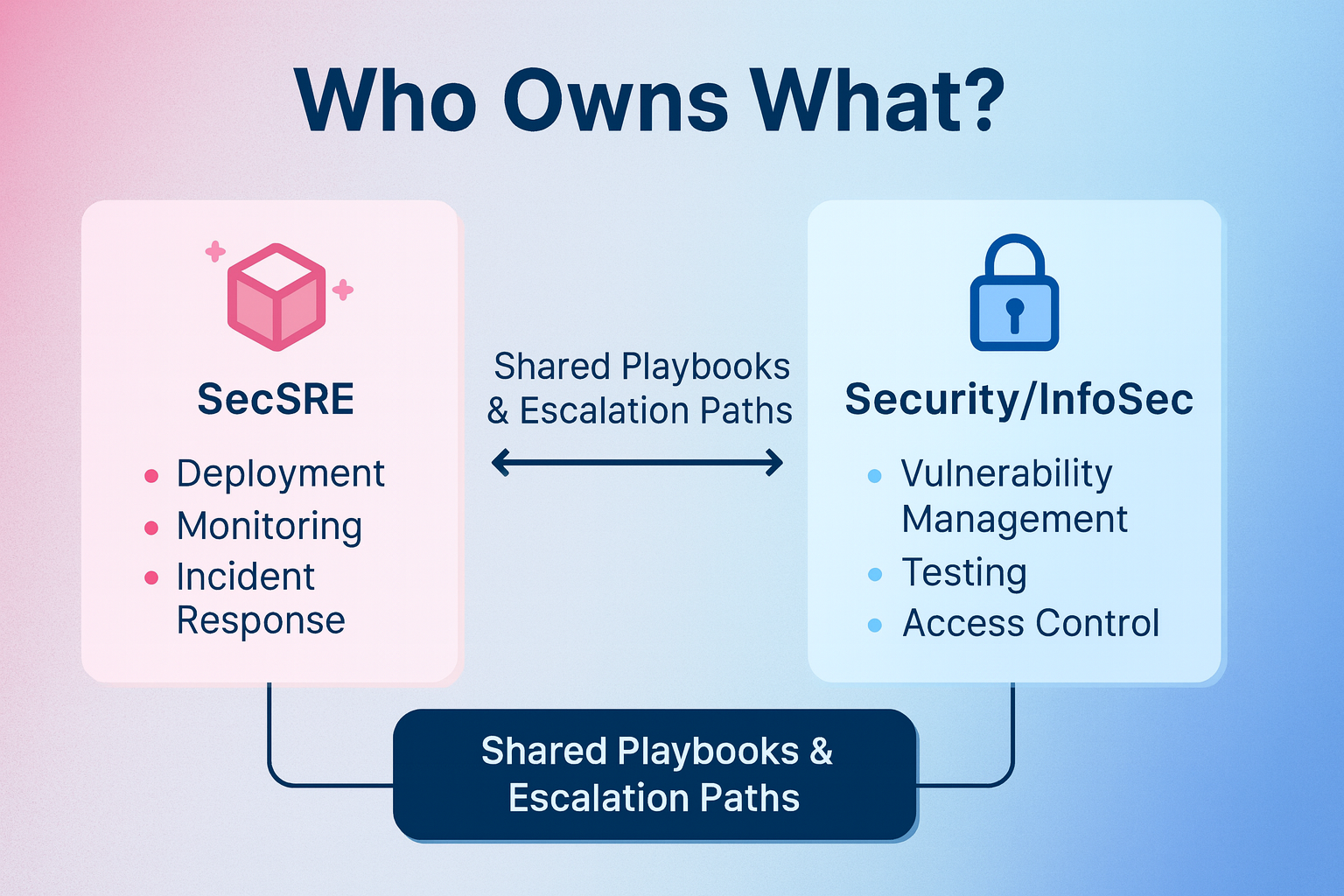
Security and reliability often live in different departments, with different metrics and mindsets. Without clear ownership, important work risks falling through the cracks. A shared model that assigns specific accountability for each area—like the “Who Owns What?” diagram—keeps everyone aligned.
2. Bridging Skill Gaps
SREs excel at uptime, automation, and performance tuning, but may lack deep knowledge of threat modeling or secure coding. Security teams know risks and vulnerabilities inside-out but may be unfamiliar with production constraints. Cross-training, joint drills, and shared tools help both sides learn from each other.
3. Cultural Alignment
SRE culture prizes speed and reducing toil, while security sometimes prioritizes thoroughness over velocity. In SecSRE, both need to meet in the middle—integrating strong controls without slowing innovation.
4. Measuring What Matters
Meaningful metrics are tricky when balancing both reliability and security. Without agreed-upon measures, it’s impossible to track whether the system is getting safer and more reliable. This is where joint SLIs/SLOs and shared dashboards become essential.
|
|
This ownership map ensures that every security and reliability responsibility – from patch management to incident response – has a clear point of accountability. It transforms SecSRE from a shared aspiration into a structured, day-to-day reality. |
Several organizations already embody aspects of SecSRE:
- Google Cloud has shown how SRE automation techniques improve Security Operations Center workflows [2].
- Datadog merged SRE and Security teams to improve both incident response times and accountability [3].
- Mindflow.io advocates treating security as part of system reliability rather than as a separate function [4].
SRE teams already know how to build reliable, fault-tolerant systems. Extending that mindset to security means:
- Treating security failures like availability failures.
- Automating security processes as rigorously as deployments.
- Defining security SLIs and tracking breach budgets.
- Designing systems that assume security controls can—and will—fail.
SecSRE is not a job title. It is a shared responsibility model that makes security a first-class citizen in engineering culture.
We are grateful to Roy Antonyraj for their guidance and constructive feedback.

