
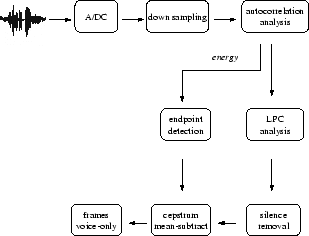
Of course, the benefits of signal processing in terms of producing a clean representation of the user's utterance must be weighed against the computational cost of the signal processing itself. The challenge is to find the right balance of eliminating environmental effects early via signal processing, versus relying on the error correction in the key generation step to compensate for the effects of noise and silence in the user's utterance. In this section we describe the series of signal processing steps that we believe best achieves this balance. These steps are pictured in Figure 1 and described textually below.
 |
As the speaker utters her passphrase, the signal is sampled at a
predefined sampling rate, which is the number of times the
amplitude of the analog signal is recorded per second. The minimum
sampling rate supported by our target platform, the IPAQ![]() (see Section 5.1), is
(see Section 5.1), is ![]() kHz; i.e.,
kHz; i.e., ![]() samples are
taken per second.7 Each sample is represented by a fixed number of bits.
Obviously, the more bits there are per sample, the better is the
resolution of the reconstructed signal, but the more storage is
required for saving and processing the utterance. In our
implementation, we represent the signal using
samples are
taken per second.7 Each sample is represented by a fixed number of bits.
Obviously, the more bits there are per sample, the better is the
resolution of the reconstructed signal, but the more storage is
required for saving and processing the utterance. In our
implementation, we represent the signal using ![]() bits per
sample. Therefore, the amount of storage required per second of
recorded speech is
bits per
sample. Therefore, the amount of storage required per second of
recorded speech is
To make subsequent processing on the device efficient, our
implementation first makes several modifications to the recorded
speech to reduce the number of samples. For example, we
down-sample the ![]() samples per second to only
samples per second to only ![]() samples
per second, effectively achieving an
samples
per second, effectively achieving an ![]() kHz sampling rate. For most
voice-related applications, a sampling rate of 8 kHz is sufficient to
reconstruct the speech signal. In fact, nearly all phone companies in
North America use a sampling rate of 8 kHz [21].
kHz sampling rate. For most
voice-related applications, a sampling rate of 8 kHz is sufficient to
reconstruct the speech signal. In fact, nearly all phone companies in
North America use a sampling rate of 8 kHz [21].
Down sampling must be performed with some care, however, due to the
sampling theorem [20]. The sampling theorem tells us
that the sampling rate must exceed twice the signal frequency to
guarantee an accurate and unique representation of the signal.
Failure to obey this rule can result in an effect called
aliasing, in which higher frequencies are falsely reconstructed as
lower frequencies. Down sampling to ![]() kHz therefore
implies that only frequencies up to
kHz therefore
implies that only frequencies up to ![]() kHz can be accurately
represented by the samples. Therefore, when down sampling to
kHz can be accurately
represented by the samples. Therefore, when down sampling to ![]() kHz we use
a low-pass digital filter with cutoff at
kHz we use
a low-pass digital filter with cutoff at ![]() kHz to strip higher
frequencies from the signal. That is, this filter takes sound of any
frequencies as input and passes only the frequencies of
kHz to strip higher
frequencies from the signal. That is, this filter takes sound of any
frequencies as input and passes only the frequencies of ![]() kHz or
less.
kHz or
less.
After down sampling, the signal is broken into ![]() millisecond (ms)
windows, each overlapping the next by
millisecond (ms)
windows, each overlapping the next by ![]() ms. Within each window are
ms. Within each window are
![]() samples (since
samples (since ![]() samples/second
samples/second ![]()
![]() seconds
seconds ![]()
![]() samples). Overlapping windows by
samples). Overlapping windows by ![]() ms avoids discontinuities
from one window to the next, and additional smoothing is performed
within each window to yield as smooth a signal as possible.
ms avoids discontinuities
from one window to the next, and additional smoothing is performed
within each window to yield as smooth a signal as possible.
The goal of the next signal processing steps is to derive a
frame from each window. A frame is a ![]() -dimensional vector of real
numbers called cepstral coefficients [20], which have
been shown to be a very robust and reliable feature set for speech and
speaker recognition. These cepstral coefficients are obtained using a
a technique called autocorrelation analysis. The basic premise
behind autocorrelation analysis is that each speech sample can be
approximated as a linear combination of past speech samples. The
extraction of a frame of cepstral coefficients using autocorrelation
analysis involves highly specialized algorithms that we do not detail
here, but that are standard in speech processing (linear predictive
coding [10]).
-dimensional vector of real
numbers called cepstral coefficients [20], which have
been shown to be a very robust and reliable feature set for speech and
speaker recognition. These cepstral coefficients are obtained using a
a technique called autocorrelation analysis. The basic premise
behind autocorrelation analysis is that each speech sample can be
approximated as a linear combination of past speech samples. The
extraction of a frame of cepstral coefficients using autocorrelation
analysis involves highly specialized algorithms that we do not detail
here, but that are standard in speech processing (linear predictive
coding [10]).
A side effect of generating frames is a calculation of the energy of the signal per window. The energy of a window is proportional to the average amplitudes of the samples in the window, measured in decibels (dB). Energy can be used to remove frames representing silence (which has very low energy) from the frame sequence, via a process called endpoint detection [13]. The silence portions of the feature frames are then removed and the voice portions concatenated.
Final modifications to the frame sequence are made via a technique called cepstral mean subtraction. In this technique, the component-wise mean over all frames is computed and subtracted from every frame in the sequence. Intuitively, if the mean vector is representative of the background noise or the channel characteristics in the recording environment, then subtracting that mean vector from all the frames yields a frame sequence that is more robust in representing the user's voice.
After this, the speech data is segmented and converted to a sequence of bits (a feature descriptor) as described in [16]. This feature descriptor is used to regenerate the secret key from the previously stored table of shares, as described in Section 2.