As illustrated in (3) of Section 3,
the storage requirements for merely saving the utterance of a
passphrase can be significant. To overcome the storage limitations of
this particular IPAQ in light of this requirement--and in particular,
to permit saving multiple utterances in our user testing--we used a
1 GB IBM Microdrive![]() (in the compact flash expansion slot)
as a stable store. However, to avoid recording noise from the
Microdrive on disk seeks, the recordings are first written to a
primary partition in volatile memory. When the memory capacity is
reached, the Microdrive is automatically mounted, the data flushed to
an ext2 file system on the drive, and then unmounted. In the
event that a wireless connection can be established, the Microdrive
can be replaced with a wireless network card, and the data written to
a remote mount point.
(in the compact flash expansion slot)
as a stable store. However, to avoid recording noise from the
Microdrive on disk seeks, the recordings are first written to a
primary partition in volatile memory. When the memory capacity is
reached, the Microdrive is automatically mounted, the data flushed to
an ext2 file system on the drive, and then unmounted. In the
event that a wireless connection can be established, the Microdrive
can be replaced with a wireless network card, and the data written to
a remote mount point.
The IPAQ was used to record utterances from ten users. All ten users
were recorded saying the same passphrase multiple times, which in this
case was the address of Carnegie Mellon University: ``Carnegie Mellon
University, 5000 Forbes Avenue, Pittsburgh, Pennsylvania 15213''. The
user was approximately one foot away from the IPAQ's microphone. The
user was required to wait for at least one second between pressing the
``record'' button of our recording application and speaking, so as to
not interleave the voice signal with the device's attempts to perform
automatic gain control. (Since the automatic gain control converges
within ![]() seconds on the IPAQ, we later discarded the first half
second of recorded speech.) Each utterance was separated from the
next by approximately one minute. The acoustic environment in which
these utterances were recorded was a standard office environment, and
as such, background noise was significant. Six recordings of each
user--the ``training'' utterances--were used to determine the
distinguishing features for that user. The remaining recordings for
each user--the ``testing'' utterances, of which there were six from
each user on average--were each used to generate a feature
descriptor. Comparing each feature descriptor to the same user's
distinguishing features, to determine the number of distinguishing
features with which the feature descriptor was consistent, counted as
a ``true speaker'' trial. Comparing each feature descriptor to
another user's distinguishing features counted as an ``imposter''
trial.
seconds on the IPAQ, we later discarded the first half
second of recorded speech.) Each utterance was separated from the
next by approximately one minute. The acoustic environment in which
these utterances were recorded was a standard office environment, and
as such, background noise was significant. Six recordings of each
user--the ``training'' utterances--were used to determine the
distinguishing features for that user. The remaining recordings for
each user--the ``testing'' utterances, of which there were six from
each user on average--were each used to generate a feature
descriptor. Comparing each feature descriptor to the same user's
distinguishing features, to determine the number of distinguishing
features with which the feature descriptor was consistent, counted as
a ``true speaker'' trial. Comparing each feature descriptor to
another user's distinguishing features counted as an ``imposter''
trial.
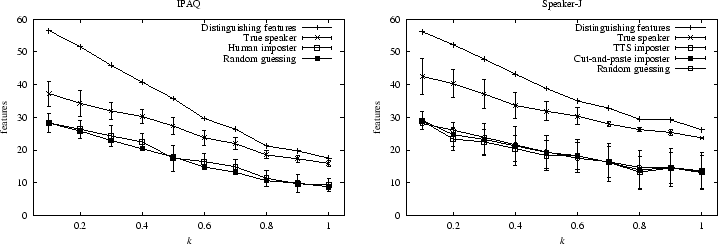
The results of this analysis are shown in the left side of
Figure 4. This graph demonstrates the average
number of distinguishing features per user as a function of ![]() , and
the average number of these that the feature descriptor of a true
speaker or an imposter matched.10 The
error bars on the true speaker and imposter curves show one standard
deviation above and below the average.
, and
the average number of these that the feature descriptor of a true
speaker or an imposter matched.10 The
error bars on the true speaker and imposter curves show one standard
deviation above and below the average.
There are several points worth noting about these results. First, the
gap between the ``distinguishing features'' and ``true speaker''
points indicates the number ![]() of error corrections that
would need to be performed during the key regeneration process to
achieve a reasonably low false reject rate. For example, if
of error corrections that
would need to be performed during the key regeneration process to
achieve a reasonably low false reject rate. For example, if ![]() , then
, then
![]() should achieve a reasonable false
reject rate, and correcting
should achieve a reasonable false
reject rate, and correcting ![]() errors is feasible on today's devices
(see Section 4.3). Unfortunately, this data
suggests that choosing
errors is feasible on today's devices
(see Section 4.3). Unfortunately, this data
suggests that choosing ![]() yields fewer distinguishing features
than we would like for security (
yields fewer distinguishing features
than we would like for security (
![]() only). A second
point worth noting is that the human imposters, even when saying the
same passphrase as the true user, did not match significantly more of
the true user's distinguishing features than if they had simply
guessed a random feature descriptor (shown by the ``random guessing''
line in Figure 4, which is simply half the
``distinguishing features'' line).
only). A second
point worth noting is that the human imposters, even when saying the
same passphrase as the true user, did not match significantly more of
the true user's distinguishing features than if they had simply
guessed a random feature descriptor (shown by the ``random guessing''
line in Figure 4, which is simply half the
``distinguishing features'' line).