In this section, the use of path history to improve the target prediction accuracy is investigated. Path history consists of target addresses of recently executed branches. The history of target addresses provides useful correlation information that can be used to improve the branch prediction accuracy. Virtual method calls in Java programs exhibit correlation among the receiver types at call sites. This is due to the presence of correlation among consecutive call sites as shown in Figure 1. In this example, the shape object s invokes a series of virtual calls and the different call sites in the function drag_drop have the same receiver type. Another reason for the correlation is due to a sequence of virtual calls triggered by a single virtual method call and the presence of looping constructs as shown in Figure 2. Here, the invocation of a virtual method to print a string triggers a sequence of method invocations. The use of path history in exploiting such correlation among call sites to predict the destination of virtual calls is investigated in this paper.
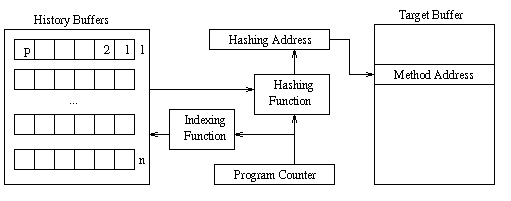
Figure 3 shows the predictor based on the use of path history information. The program counter stores the address of the virtual method call site. An indexing function of the program counter is used to access the path history information corresponding to the call site. Then a hashing function of the path history information from the history buffers and the program counter is used to form the hashing address. This address is used to index the target buffer to obtain the target address. The various parameters involved in the design of such a predictor include the number of history buffers (n), path history length (p), the number of bits of each target address registered in the history buffer (b), the hashing function, and the structure of the target buffer. The target buffer could either be tagless or a tagged buffer. In a tagless buffer, the hashing address is used to index into the buffer and no tag comparisons are involved. Hence, the mapping of two different hashing addresses in to the same target buffer location are not distinguished. In contrast, the tagged buffer has a tag associated with each entry. These tags help to distinguish different history patterns that map to the same location. The influence of these parameters on the performance of the predictor is studied in the subsequent sections.
T1 - Number of virtual calls executed
|