![]()
![]()
![]()
Next: Adaptive parallelism Up: Adaptive
and Reliable Previous: The Cilk language and
The Cilk-NOW runtime system consists of several component programs that (in addition to macroscheduling duties discussed later) manage the execution of each individual Cilk program. In this section, we shall cover the architecture of a Cilk program as it is executed by the Cilk-NOW runtime system, explaining the operation of each component and their interactions.
In Cilk-NOW terminology, we refer to an executing Cilk program as a Cilk job. Since Cilk programs are parallel programs, a Cilk job consists of several processes running on several machines. One process, called the clearinghouse, in each Cilk job runs a system-supplied program called CilkChouse that is responsible for keeping track of all the other processes that comprise a given job. These other processes are called workers. A worker is a process running the actual executable of a Cilk program. Since Cilk jobs are adaptively parallel, the set of workers is dynamic. At any given time during the execution of a job, a new worker may join the job or an existing worker may leave. Thus, each Cilk job consists of one or more workers and a clearinghouse to keep track of them.
The Cilk-NOW runtime system contains additional components that perform macroscheduling as discussed in Section 6, but for the purpose of our present discussion, we need only introduce the "node managers." A node manager is a process running a system-supplied program called CilkNodeManager. A node manager runs as a background daemon on every machine in the network. It continually monitors its machine to determine when the machine is idle.
To see how all of these components work together in managing the execution of a Cilk job, we shall run through an example. (In describing interactions with the macroscheduler, we shall refer to the macroscheduler as a single entity, though actually, as we shall see in Section 6, the macroscheduler is a distributed subsystem with several components.) Suppose that a user sits down at a machine called Penguin to run the pfold program. In our example, the user types
pfold 3 7
at the shell, thereby launching a Cilk job to enumerate all protein foldings using 3 initial folding sequences and starting with the 7th one.
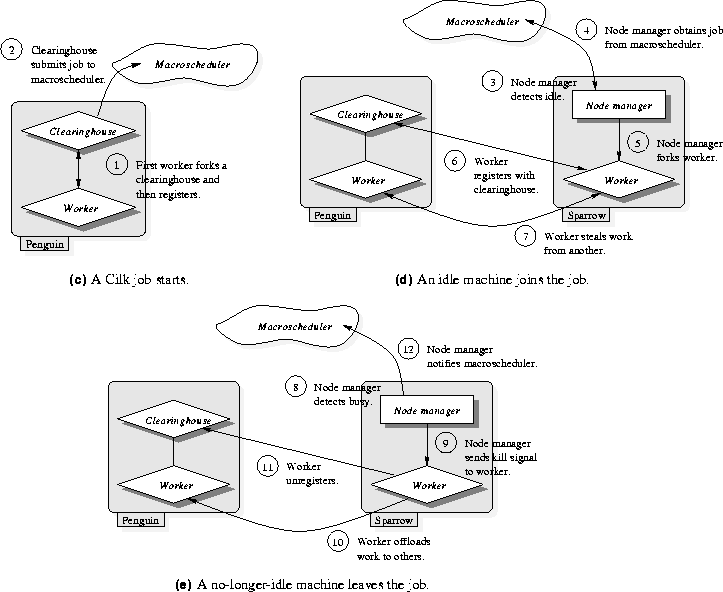
The new Cilk job begins execution as illustrated in Figure 4(c). The new process running the pfold executable is the first worker and begins execution by forking a clearinghouse with the command line
CilkChouse -- pfold 3 7 .
Thus, the clearinghouse knows that it is in charge of a job whose workers are running "pfold 3 7." The clearinghouse begins execution by sending a job description to the macroscheduler. The job description is a record containing several fields. Among these fields is the name of the Cilk program executable--in this case pfold--and the clearinghouse's network address. The clearinghouse then goes into a service loop waiting for messages from its workers. After forking the clearinghouse, the first worker registers with the clearinghouse by sending it a message containing its own network address. Now the clearinghouse knows about one worker, and it responds to that worker by assigning it a unique name. Workers are named with numbers, starting with number 0. Having registered, worker 0 begins executing the Cilk program as described in Section 2. We now have a running Cilk job with one worker.
Figure 4: (c) The first worker forks a
clearinghouse, and then the clearinghouse submits the job to the
macroscheduler. (d) When the node manager detects that its
machine is idle, it obtains a job from the macroscheduler and then
forks a worker. The worker registers with the clearinghouse and then
begins work stealing. (e) When the node manager detects that
its machine is no-longer idle, it sends a kill signal to the
worker. The worker catches this signal, offloads its work to other
workers, unregisters with the clearinghouse, and then terminates.
A second worker joins the Cilk job when some other workstation in the network discovers that it is idle, as illustrated in Figure 4(d). Suppose the node manager on a machine named Sparrow detects that the machine is idle. The node manager sends a message to the macroscheduler, and the macroscheduler responds with the job description of a Cilk job for the machine to work on. In this case, the job description specifies our pfold job by giving the name of the executable--pfold--and the network address of the clearinghouse. The node manager then uses this information to fork a new worker as a child with the command line
pfold -NoChouse -Address=clearinghouse-address -- .
The -NoChouse flag on the command line tells the worker that it is to be an additional worker in an already existing Cilk job. (Without this flag, the worker would fork a new clearinghouse and start a new Cilk job.) The -Address field on the command line tells the worker where in the network to find the clearinghouse. The worker uses this address to send a registration message, containing its own network address, to the clearinghouse. The clearinghouse responds with the worker's assigned name--in this case, number 1--and the job's command-line arguments--in this case, "pfold 3 7." Additionally, the clearinghouse responds with a list of the network addresses of all other registered workers. Now the new worker knows the addresses of the other workers, so it can commence execution of the Cilk program and steal work as described in Section 2. We now have a running Cilk job with two workers.
Now, suppose that someone touches the keyboard on Sparrow. In this case, the node manager detects that the machine is busy, and the machine leaves the Cilk job as illustrated in Figure 4(e). After detecting that the machine is busy, the node manager sends a kill signal to its child worker. The worker catches this signal and prepares to leave the job. First, the worker offloads all of its closures to other workers as explained in more detail in Section 4. Next, the worker sends a message to the clearinghouse to unregister. Finally, the worker terminates.
When a Cilk job is running, each worker periodically checks in with the clearinghouse. Specifically, each worker periodically (every 2 seconds) sends a message to the clearinghouse, and the clearinghouse responds with an update message informing the worker of any other workers that have left the job and any new workers that have joined the job. For each new worker that has joined, the clearinghouse also provides the network address. If the clearinghouse does not receive any messages from a given worker for an extended period of time (30 seconds), then the clearinghouse determines that the worker has crashed. In later update messages, the clearinghouse informs the other workers of the crash, and the other workers take appropriate remedial action as described in Section 5.
All communication between workers, and between workers and the clearinghouse, is implemented with UDP/IP [13, 40]. Knowing that UDP datagrams are unreliable, the Cilk-NOW protocols incorporate appropriate mechanisms, such as acknowledgments, retries, and timeouts, to ensure correct operation when messages get lost. We shall not discuss these mechanisms in any detail, and in order to simplify our exposition of Cilk-NOW, we shall often speak of messages being sent and received as if they are reliable. What we will say about these mechanisms is that they are built on top of UDP but without any effort to create a reliable message-passing layer. Rather these mechanisms are built directly into the runtime system's protocols, so in the common case when a message does get through, Cilk-NOW pays no overhead to make the message reliable.
We chose to build Cilk-NOW's communication protocols using an unreliable message-passing layer instead of a reliable one for two reasons, both based on end-to-end design arguments [38]. First, reliable layers such as TCP/IP [40] and PVM [41] perform implicit acknowledgments and retries to achieve reliability. Therefore, such layers either preclude the use of asynchronous communication or require extra buffering and copying. A layer such as UDP which provides minimal service guarantees can be implemented with considerably less software overhead than a layer with more service features. In the common case when the additional service is not needed, the minimal layer can easily outperform its fully-featured counterpart. Second, in an environment where machines can crash and networks can break, the notion of a "reliable" message-passing layer is somewhat suspect. A runtime system operating in an inherently unreliable environment cannot expect the message-passing layer to make the environment reliable. Rather, the runtime system must incorporate appropriate mechanisms into its protocols to take action when a communication endpoint or link fails. For these reasons, we chose to build the Cilk-NOW runtime system on top of a minimal layer of message-passing service and incorporate mechanisms directly into the runtime system's protocols in order to handle issues of reliability. The downside to this approach is complexity. The protocols implemented in the Cilk-NOW runtime system are complex: the code for these protocols takes almost 20 percent of the total runtime-system code, and the programming effort was probably near half of the total. Nevertheless, this was a one-time effort that we expect will reap performance rewards for a long time to come.