![]()
![]()
![]()
Next: Cilk-NOW job architecture
Up: Adaptive and Reliable Previous: Introduction
In this section we overview the Cilk parallel multithreaded language and its runtime system's work-stealing scheduler [6, 8, 26]. For brevity, we shall not present the entire Cilk language, and we shall omit some details of the work-stealing algorithm. Since Cilk-2 forms the basis for the Cilk-NOW system, we shall focus on the Cilk-2 language and on the Cilk-2 runtime system as implemented without adaptive parallelism or fault tolerance.
A Cilk program contains one or more Cilk procedures, and each Cilk procedure contains one or more Cilk threads. A Cilk procedure is the parallel equivalent of a C function, and a Cilk thread is a nonsuspending piece of a procedure. The Cilk runtime system manipulates and schedules the threads. The runtime system is not aware of the grouping of threads into procedures. Cilk procedures are purely an abstraction supported by the cilk2c type-checking preprocessor [33].
Consider a program that uses double recursion to compute the Fibonacci function. The Fibonacci function fib(n) for positive n is defined as
![]()
Figure 2 shows how this function is written as a Cilk procedure consisting of two Cilk threads: Fib and Sum. While double recursion is a terrible way to compute Fibonacci numbers, this toy example does illustrate a common pattern occurring in divide-and-conquer applications: recursive calls solve smaller subcases and then the partial results are merged to produce the final result.
Figure 2: A Cilk procedure to compute the nth
Fibonacci number. This procedure contains two threads, Fib
and Sum.
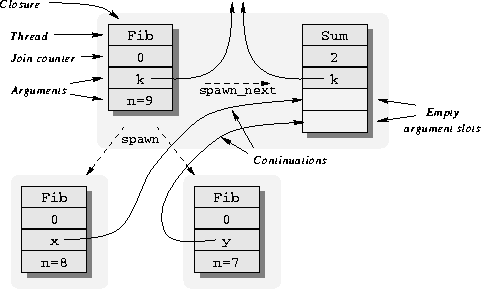
A Cilk thread generates parallelism at runtime by spawning a child thread that is the initial thread of a child procedure. A spawn is the parallel equivalent of a function call. A spawn differs from a call in that when a thread spawns a child, the parent and child may execute concurrently. After spawning one or more children, the parent thread cannot then wait for its children to return--in Cilk, threads never suspend. Rather, the parent thread must additionally spawn a successor thread to wait for the values "returned" from the children. The spawned successor is part of the same procedure as its predecessor. The child procedures return values to the parent procedure by sending those values to the parent's waiting successor. Thus, a thread may wait to begin executing, but once it begins executing, it cannot suspend. This style of interaction among threads is called continuation-passing style [4]. Spawning successor and child threads is done with the spawn_next and spawn keywords respectively. Sending a value to a waiting thread is done with the send_argument statement. The Cilk runtime system implements these primitives using two basic data structures: closures and continuations.
Figure 3: The Fib thread spawns a successor
and two children. For the successor, it creates a closure with 2
empty argument slots, and for each child, it creates a closure with a
continuation referring to one of these empty slots. The background
shading denotes Cilk procedures.
Closures are data structures employed by the runtime system to keep track of and schedule the execution of spawned threads. Whenever a thread is spawned, the runtime system allocates a closure for it from a simple heap. A closure consists of a pointer to the code for that thread, a slot for each of the thread's specified arguments, and a join counter indicating the number of missing arguments that need to be supplied before the thread is ready to run. The closure, or equivalently the spawned thread, is ready if it has obtained all of its arguments, and it is waiting if some arguments are missing. To run a ready closure, the Cilk scheduler invokes the thread using the values in the closure as arguments. When the thread dies, the closure is freed.
A continuation is a global reference to an empty argument slot of a closure, implemented as a compound data structure containing a pointer to a closure and an offset that designates one of the closure's argument slots. Continuations are typed with the C data type of the slot in the closure. In the Cilk language, continuations are declared by the type modifier keyword cont. For example, the Fib thread declares two integer continuations, x and y.
Using the spawn_next primitive, a thread spawns a successor thread by creating a closure for the successor. The successor thread is part of the same procedure as its predecessor. For example, in the Fib thread, the statement spawn_next Sum (k, ?x, ?y) allocates a closure with Sum as the thread and three argument slots, as illustrated in Figure 3. The first slot is initialized with the continuation k and the last two slots are empty. The continuation variables x and y are initialized to refer to these two empty slots, and the join counter is set to 2. This closure is waiting.
Similarly, using the spawn primitive, a thread spawns a child thread by creating a closure for the child. The child thread is the initial thread of a newly spawned child procedure. The spawn statement is semantically identical to spawn_next. For example, the Fib thread spawns two children as shown in Figure 3. The statement spawn Fib (x, n-1) allocates a closure with Fib as the thread and two argument slots. The first slot is initialized with the continuation x which, as a consequence of the previous statement, refers to a slot in its parent's successor closure. The second slot is initialized with the value of n-1. The join counter is set to zero, so the thread is ready.
An executing thread sends a value to a waiting thread by placing the value into an argument slot of the waiting thread's closure. The send_argument statement sends a value to the empty argument slot of a waiting closure specified by its argument. The types of the continuation and the value must be compatible. The join counter of the waiting closure is decremented, and if it becomes zero, then the closure is ready. For example, the statement send_argument (k, n) in Fib writes the value of n into an empty argument slot in the parent procedure's waiting Sum closure and decrements its join counter. When the Sum closure's join counter reaches zero, it is ready. When the Sum thread gets executed, it adds its two arguments, x and y, and then uses send_argument to "return" this result up to its parent procedure's waiting Sum thread.
At runtime, each processor maintains a "ready" deque (double-ended queue) which contains all of the ready closures. Whenever a closure is created, if its join counter is 0, then it is placed on the head of the ready deque. Whenever a send_argument call is made, the join counter is decremented, and if the join counter is decremented to zero, then the closure is placed on the head of the ready deque. When a thread finishes, the next thread to execute is chosen from the head of the ready deque.
If no threads are available in the ready deque, a processor engages in work stealing. To steal work, a processor, called the thief, chooses another processor, called the victim, at random and requests a closure to be sent back. If that processor has any closures in its ready deque, one is removed from the tail of the victim's ready deque and sent across the network to the thief, who will add this closure to its own ready deque. The thief may then begin work on the stolen closure. If the victim has no ready closures, it informs the thief who then tries to steal from another random processor until a ready closure is found or program execution completes.
This simple work-stealing scheduler has been shown, both
analytically and empirically, to deliver efficient and predictable
performance [6, 8, 9] for "well structured"
computations. A well structured computation is one in which
each procedure sends values (with send_argument) only to its
parent and only as the last action performed by its last thread. For
well structured computations executing on any number P of
processors, the execution time can be modeled accurately as ![]() where
where ![]() denotes the work of the computation--that is, the execution
time with 1 processor--and
denotes the work of the computation--that is, the execution
time with 1 processor--and ![]() denotes the critical-path
length--that is, the theoretical execution time on an ideal
machine with infinitely many processors. Such performance is within a
factor of 2 of optimal, and additionally when the critical path is
short compared to the amount of work per processor, such performance
displays linear speedup.
denotes the critical-path
length--that is, the theoretical execution time on an ideal
machine with infinitely many processors. Such performance is within a
factor of 2 of optimal, and additionally when the critical path is
short compared to the amount of work per processor, such performance
displays linear speedup.
The key element in proving this ![]() performance
bound is the fact that closures are always stolen from the tail of the
ready deque. For well structured computations, a closure that is on
the critical path must be at the tail of some processor's ready deque.
Thus, when processors are not executing closures, they are stealing
work and, therefore, are likely to be making progress on the critical
path. As a corollary to this result, the number of work-steal
attempts per processor is proportional to the critical-path length and
does not grow with the work. Thus, a computation with a sufficiently
short critical path compared to the work per processor can continue to
display linear speedup even when communication is very expensive. This
idea of amortizing overhead against the critical path plays an
important role in our later discussion of adaptive parallelism and
fault tolerance.
performance
bound is the fact that closures are always stolen from the tail of the
ready deque. For well structured computations, a closure that is on
the critical path must be at the tail of some processor's ready deque.
Thus, when processors are not executing closures, they are stealing
work and, therefore, are likely to be making progress on the critical
path. As a corollary to this result, the number of work-steal
attempts per processor is proportional to the critical-path length and
does not grow with the work. Thus, a computation with a sufficiently
short critical path compared to the work per processor can continue to
display linear speedup even when communication is very expensive. This
idea of amortizing overhead against the critical path plays an
important role in our later discussion of adaptive parallelism and
fault tolerance.