
The average-case (ACET) and worst-case execution times (WCET) to perform an IPC read/write operation are both important factors in the performance of an IPC algorithm. A low ACET would indicate that the algorithm generally incurs low computation overheads. However, to provide timeliness guarantees in embedded real-time systems, the scheduler must account for the WCET. An algorithm with low ACET but high WCET may result in poor system utilization.
The ACET and WCET of the SMP versions of the eight evaluated algorithms are shown on the top and bottom rows, respectively, in Figure 12. The SMP versions of the algorithms include bus-lock operations to ensure the atomic operation of the critical CAS and TAS instructions with multiple processors. The message size is 8 bytes, and the task set consists of 1 writer and 20 readers, of which a varying fraction are fast readers. Specifically, we evaluated these algorithms when the reader set contains 20%, 40%, 60% and 80% fast readers. The first three pairs of columns on the graphs are for the three single-writer, multiple-reader algorithms and their corresponding transformed algorithms. We can see significant reductions in both the ACET and WCET from comparison of the transformed algorithms with the original ones. As the number of fast readers in the reader set increases, the reduction in computation time for the transformed algorithms gets more pronounced. ACETs for Double Buffer and Chen's algorithms improve by as much as 66%, and for Peterson's algorithm by as much as 38%. This trend is shown in Figure 15(a).
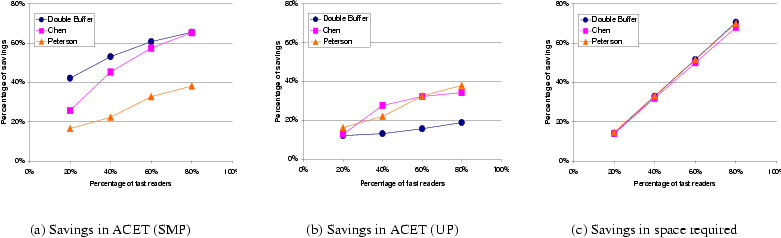 |
Although the amount of improvement is a non-decreasing function of the percentage of fast readers in the reader set, the magnitude of this improvement depends on the particular algorithm. In these experiments, all of the transformed algorithms perform better than the original versions except for the WCET of the Double Buffer algorithm. This can be attributed to the fact that the WCET for the Double Buffer algorithm occurs in the slow readers. As this time is not affected by the number of slow readers in the system, the WCET does not improve. For the other algorithms, the WCETs occur in the writers, whose overheads are functions of the number of slow readers, and, therefore, improve greatly.
It is interesting to note that even though the ACET of the lock-based algorithm is only up to 4 times larger than those of the transformed wait-free algorithms, its WCET is much higher -- 4 to 30 times higher. This is in fact an underestimate of the true overhead of the lock-based mechanism, since we assume no blocking time here. In actual systems, unless the system employs mechanisms to limit blocking times, the lock-based execution time may be unbounded.