
The runlength ![]() and the number of trials
and the number of trials ![]() together determine the
benchmarking cost incurred at a given test load
together determine the
benchmarking cost incurred at a given test load ![]() . The controller
should choose
. The controller
should choose ![]() and
and ![]() to obtain the confidence and accuracy desired for each
test load at least cost. The goal is to converge quickly to an accurate reading
at the peak rate:
to obtain the confidence and accuracy desired for each
test load at least cost. The goal is to converge quickly to an accurate reading
at the peak rate:
![]() and load factor
and load factor ![]() . High
confidence and accuracy are needed for the final test load at
. High
confidence and accuracy are needed for the final test load at
![]() , but accuracy is less crucial during the search for the peak rate.
Thus the controller has an opportunity to reduce benchmarking cost by adapting
the target confidence and accuracy for each test load
, but accuracy is less crucial during the search for the peak rate.
Thus the controller has an opportunity to reduce benchmarking cost by adapting
the target confidence and accuracy for each test load ![]() as the search
progresses, and choosing
as the search
progresses, and choosing ![]() and
and ![]() for each
for each ![]() appropriately.
appropriately.
At any given load level the controller can trade off confidence and
accuracy for lower cost by decreasing either ![]() or
or ![]() or both.
Also, at a given cost
any given set of trials and runlengths can give a high-confidence
result with wide confidence intervals (low accuracy), or a narrower confidence
interval (higher accuracy) with lower confidence.
or both.
Also, at a given cost
any given set of trials and runlengths can give a high-confidence
result with wide confidence intervals (low accuracy), or a narrower confidence
interval (higher accuracy) with lower confidence.
However, there is a complication: performance variability tends to increase as
the load factor ![]() approaches saturation. Figure 4 and
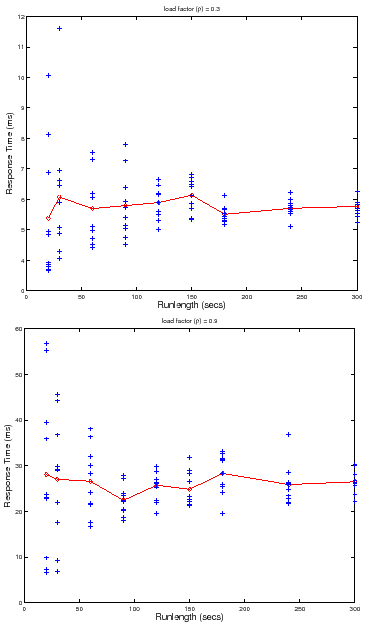
Figure 5 illustrate this effect. Figure 4 is a
scatter plot of mean server response time (
approaches saturation. Figure 4 and
Figure 5 illustrate this effect. Figure 4 is a
scatter plot of mean server response time (![]() ) at different test loads
) at different test loads
![]() for five trials at each load. Note that the variability across
multiple trials increases as
for five trials at each load. Note that the variability across
multiple trials increases as
![]() and
and
![]() . Figure 5 shows a scatter plot of
. Figure 5 shows a scatter plot of ![]() measures for multiple runlengths at two load factors,
measures for multiple runlengths at two load factors,
![]() and
and
![]() . Longer runlengths show less variability at any load factor, but for a
given runlength, the variability is higher at the higher load factor. Thus the
cost for any level of confidence and/or accuracy also depends on load level:
since variability increases at higher load factors, it requires longer
runlengths
. Longer runlengths show less variability at any load factor, but for a
given runlength, the variability is higher at the higher load factor. Thus the
cost for any level of confidence and/or accuracy also depends on load level:
since variability increases at higher load factors, it requires longer
runlengths ![]() and/or a larger number of trials
and/or a larger number of trials ![]() to reach a target level of
confidence and accuracy.
to reach a target level of
confidence and accuracy.
For example, consider the set of trials plotted in Figure 5. At
load factor ![]() and runlength of
and runlength of ![]() seconds, the data gives us
seconds, the data gives us ![]() %
confidence that
%
confidence that
![]() , or
, or ![]() % confidence that
% confidence that
![]() . From the data we can determine the runlength needed to achieve target
confidence and accuracy at this load level and number of trials
. From the data we can determine the runlength needed to achieve target
confidence and accuracy at this load level and number of trials ![]() : a runlength
of
: a runlength
of ![]() seconds achieves an accuracy of
seconds achieves an accuracy of ![]() % with
% with ![]() % confidence, but it
takes a runlength of
% confidence, but it
takes a runlength of ![]() seconds to achieve
seconds to achieve ![]() % accuracy with
% accuracy with ![]() %
confidence. Accuracy and confidence decrease with higher load factors. For
example, at load factor
%
confidence. Accuracy and confidence decrease with higher load factors. For
example, at load factor ![]() and runlength
and runlength ![]() , the data gives us
, the data gives us ![]() %
confidence that
%
confidence that
![]() (
(![]() % accuracy), or
% accuracy), or ![]() % confidence
that
% confidence
that
![]() (
(![]() % accuracy). As a result, we must increase the
runlength and/or the number of trials to maintain target levels of confidence
and accuracy as load factors increase. For example, we need a runlength of
% accuracy). As a result, we must increase the
runlength and/or the number of trials to maintain target levels of confidence
and accuracy as load factors increase. For example, we need a runlength of
![]() seconds or more to achieve accuracy
seconds or more to achieve accuracy ![]() % at
% at ![]() % confidence for
this number of trials at load factor
% confidence for
this number of trials at load factor ![]() .
.
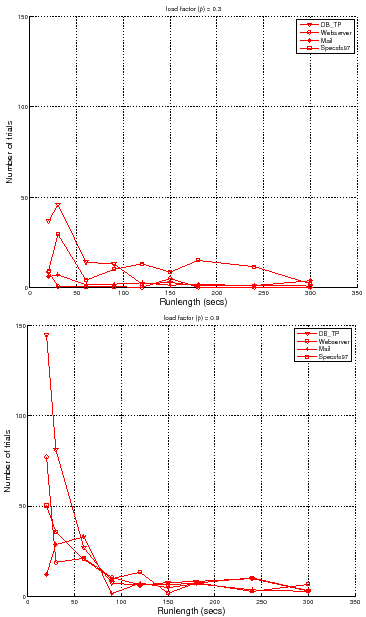
Figure 6 quantifies the tradeoff between the
runlength and the number of trials required to attain a target accuracy and
confidence for different workloads and load factors. It shows the number of
trials required to meet an accuracy of ![]() % at
% at ![]() % confidence level for
different runlengths. The figure shows that to attain a target accuracy and
confidence, one needs to conduct more independent trials at shorter runlengths.
It also shows a sweet spot for the runlengths that reduces the number of trials
needed. A controller can use such curves as a guide to pick a suitable
runlength
% confidence level for
different runlengths. The figure shows that to attain a target accuracy and
confidence, one needs to conduct more independent trials at shorter runlengths.
It also shows a sweet spot for the runlengths that reduces the number of trials
needed. A controller can use such curves as a guide to pick a suitable
runlength ![]() and number of trials
and number of trials ![]() with low cost.
with low cost.
 |
 |
varun 2008-05-13