
Common practice for finding the peak rate is to script a sequence of runs for a
standard workload at a fixed linear sequence of escalating
load levels, with a preconfigured runlength ![]() and number of trials
and number of trials ![]() for
each load level. The algorithm is in essence a linear search for the peak
rate: it starts at a
default load level and increments the load level (e.g., arrival rate) by some
fixed increment until it drives the server
into saturation. The last load level
for
each load level. The algorithm is in essence a linear search for the peak
rate: it starts at a
default load level and increments the load level (e.g., arrival rate) by some
fixed increment until it drives the server
into saturation. The last load level ![]() before saturation is taken as
the peak rate
before saturation is taken as
the peak rate ![]() . We refer to this algorithm as strawman.
. We refer to this algorithm as strawman.
 |
 |
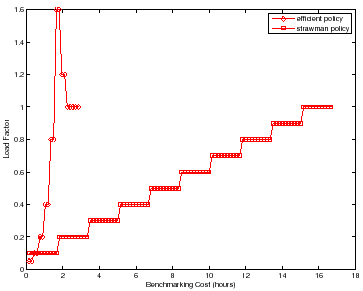
Strawman is not efficient. If the increment is too small, then it requires many iterations to reach the peak rate. Its cost is also sensitive to the difference between the peak rate and the initial load level: more powerful server configurations take longer to benchmark. A larger increment can converge on the peak rate faster, but then the test may overshoot the peak rate and compromise accuracy. In addition, strawman misses opportunities to reduce cost by taking ``rough'' readings at low cost early in the search, and to incur only as much cost as necessary to obtain a statistically sound reading once the peak rate is found.
A simple workbench controller with feedback can improve significantly on the
strawman approach to searching for the peak rate. To illustrate,
Figure 3 depicts the search for ![]() for two
policies conducting a sequence of experiments, with no concurrent testing. For
strawman we use runlength
for two
policies conducting a sequence of experiments, with no concurrent testing. For
strawman we use runlength ![]() =
= ![]() minutes,
minutes, ![]() trials, and a small
increment to produce an accurate result. The figure compares strawman to
an alternative that converges quickly on the peak rate using binary search, and
that adapts
trials, and a small
increment to produce an accurate result. The figure compares strawman to
an alternative that converges quickly on the peak rate using binary search, and
that adapts ![]() and
and ![]() dynamically to balance accuracy, confidence, and cost
during the search. The figure represents the sequence of actions taken by each
policy with cumulative benchmarking time on the x-axis; the y-axis gives the
load factor
dynamically to balance accuracy, confidence, and cost
during the search. The figure represents the sequence of actions taken by each
policy with cumulative benchmarking time on the x-axis; the y-axis gives the
load factor
![]() for each test load evaluated by
the policies. The figure shows that strawman can incur a much higher
benchmarking cost (time) to converge to the peak rate and complete the search
with a final accurate reading at load factor
for each test load evaluated by
the policies. The figure shows that strawman can incur a much higher
benchmarking cost (time) to converge to the peak rate and complete the search
with a final accurate reading at load factor ![]() . The strawman policy not
only evaluates a large number of test loads with load factors that are not close
to
. The strawman policy not
only evaluates a large number of test loads with load factors that are not close
to ![]() , but also incurs unnecessary cost at each load.
, but also incurs unnecessary cost at each load.
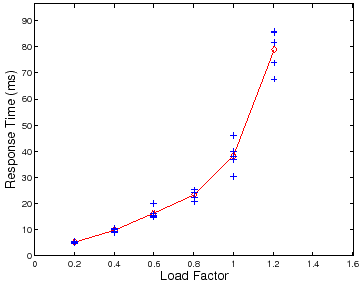
The remainder of the paper discusses the improved controller policies in more detail, and their interactions with the outer loop in mapping response surfaces.
varun 2008-05-13