Partitioned Context Modeling originated from Finite Multi-Order Context Modeling (FMOCM) and the text compression algorithm PPM [2]. A context model is one that uses preceding events to model the next event. For example, in the string ``object'' the character ``t'' is said to occur within the context ``objec''. The length of a context is termed its order. In the example string, ``jec'' would be considered a third order context for `` t''. Techniques that predict using multiple contexts of varying orders (e.g.``ec'', ``jec'', ``bjec'') are termed Multi-Order Context Models [2]. To prevent the model from quickly growing beyond available resources, most implementations of a multi-order context model limit the highest order modeled to some finite number m, hence the term Finite Multi-Order Context Model. In these examples we have used letters of the alphabet to illustrate how this modeling works in text compression. For modeling file access patterns, each of these letters is replaced with a unique file.
A context model uses a trie [11], a data structure based on a tree, to efficiently store sequences of symbols. Each node in this trie contains a symbol (e.g. a letter from the alphabet, or the name of a specific file). By listing the symbols contained on the path from the root to any individual node, each node represents an observed pattern. The children of every node represent all the symbols that have been seen to follow the pattern represented by the parent. To model access probabilities we add to each node a count of the number of times that pattern has been seen. By comparing the counts of the sequence just seen with the counts of those nodes that previously followed this pattern we can generate predictions of what file will be accessed next.
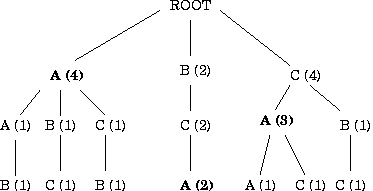
Figure 2 extends an example from Bell et al. [2] to illustrate how this trie would develop when given the sequence of events CACBCAABCA. In this diagram the circled node A represents the pattern CA, which has occurred three times. This pattern has been followed once by another access to the file A and once by an access to the file C. The third time is the last event to be seen and we haven't yet seen what will follow. We can use this information to predict both A and C each with a likelihood of 0.5. The state space for this model is proportional to the number of nodes in this tree, which is bounded by O(nm), where m is the highest order tracked and n is number of unique files. On a normal file system were the number of files can range between 10 thousand and 100 million such space requirements are unreasonable. In response, we developed the Partitioned Context Model (PCM).