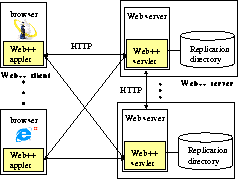
The Web++ architecture is shown in Figure 1. It consists of Web++ clients and Web++ servers. Both client-to-server and server-to-server communication is carried on top of the standard HTTP 1.1 protocol [18]. Users submit their requests to Web++client, which is a Smart Client [44], i.e., a standard Web browser (Netscape Navigator 4.x or Microsoft Internet Explorer 4.x) extended by downloading a cryptographically signed applet. The Web++applet must be signed so that it can execute outside of the security "sandbox". The Web++ client sends user requests to a Web++server, which is a standard HTTP server extended either with a Web++servlet or a server-side proxy. The Web++ server returns the requested resource that can be either statically or dynamically generated.
Each Web++ resource contains a set of logical URLs to reference other resources. Before resource retrieval, each logical URL is bound to one of the physical URLs that corresponds to one of the resource replicas. A physical URL is the naming scheme currently used on the Web as specified in [6]. A logical URL is similar to Uniform Resource Name (URN) [39] in that it uniquely identifies a single resource independently of its location. Unlike the URN specification, there are no restrictions on syntax of logical URLs. In fact, a physical URL of resource replica can also be considered as a logical URL1. The only difference between a logical and a physical URL lies in their interpretation at resource retrieval time. While a physical URL is directly used to retrieve a resource, a logical URL first must be bound to a physical URL. The binding is done by the Web++ applet that executes within the user's browser.
After receiving a resource, the Web++ applet intercepts any events that are triggered either due to the browser's parsing of a resource or due to a user following logical URLs embedded in a retrieved resource. For each logical URL the applet finds a list of physical URLs that correspond to the resource's replicas. The list is embedded into the referencing resource by the Web++ servlet. Using the resource replica selection algorithm, the applet selects the physical URL that corresponds to a resource held by an available server that is expected to deliver the best response time for the client. If, after sending the request, the client does not receive a response, the applet fails over to the next fastest server. This process continues until the entire list of physical URLs is exhausted or the resource is successfully retrieved.
Each server maintains a replication directory that maps each logical URL into a set of physical URLs that identify the locations of replicas of the resource. For example, the replication directory may contain an entry
/misc/file.txt :
https://server1.com/files/miscFile.txt
https://server2.com/misc/file.txt
Web++ servers are capable of creating, destroying and updating resource replicas. After creation or destruction of a replica each server automatically updates its local copy of the replication directory and propagates the update to other servers. The servers guarantee eventual consistency of their replication directories in the presence of concurrent updates propagated from different servers. Web++ servers also pre-process each HTML resource sent to a client by embedding physical URLs corresponding to each logical URL that occurs in the resource. The servers also embed a reference to the Web++ client applet within each HTML resource. Finally, Web++ servers also keep track of the load associated with their resources. The load statistics can be used by user-supplied policies that determine when, where and which resource should be replicated or when a replica should be destroyed.