
The MBFS and NFS servers were run on a SPARC 20 with 128 MB of memory and a Seagate ST31200W disk with a 10ms average access time. We ran up to 10 simultaneous client machines on each server. Each client was a SPARC 20 with 64 MB of memory and a 10ms Seagate local disk (for the UFS tests). Tmpfs tests used the standard UNIX temp file system. All machines were connected by a 100 Mbps Ethernet and tests were run during the evening hours when the network was lightly loaded. We computed confidence intervals for each test. The confidence intervals were typically within 5% of the total runtime and as a result are not shown in the graphs.
Five tests with different workloads were run:
(1) write throughput for large
files,
(2) small file create/write/delete throughput,
(3) a mixture of file and directory creation with large and small
files,
(4) a manual edit test,
and
(5) the Andrew Benchmark.
Each of the tests focused on write traffic to files or directories.
Read traffic was minimal and did not contribute to any speedups observed.
Each test was run several times and averaged.
The results show two graphs: (1) a line-graph illustrating the
scalability of MBFS versus NFS in terms of total runtime, and (2)
a pie-chart of the 10-client test describing how much each operation
contributed to the overall speedup. Each slice of the pie-chart
depicts the percentage of runtime improvement caused by that
operation. The numbers in parenthesis list the average speedup over
NSF for the operation. The first number in the pair gives the
absolutes speedup in milliseconds and the second number gives the
relative speedup in terms of a percentage
(
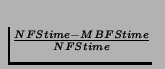 ).
).
To measure the baseline write performance, we used a large-write throughput test. Each client creates a copy of an existing 10 MB file. Because the new file is a copy, disk persistence is not required. The original 10 MB files is preloaded into the client cache to eliminate read traffic from the test. Figure 1(a) shows that MBFS performs better than NFS (despite NFS's use of asynchronous writes) because of contention at the disk. Note that as the number of clients increases, the server's maximum receive rate quickly becomes the bottleneck in this test. Figure 1(b) shows that 91% of the overall runtime savings were due to improved write operations, with 9% of the improvement arising from the fact the MBFS does not issue a final commit operation. In other words, even when writes are asynchronous, the server response time is significantly slower than MBFS memory-only writes.
Figure 2(a) shows the results of the Andrew Benchmark that tests several aspects of file system performance: making directories, copying files to those directories, scanning the directories, read the file contents, and perform a compilation. To more accurately isolate the file system performance, we subtracted the CPU time used by the compiler during the compilation phase. Because all the data and directories are generated or copied, none of the writes required disk persistence. Improvements range from 40% with one client (a perceivable improvement to the user) to as much as 64%. Figure 2(b) clearly illustrates that all savings come from operations that typically require disk persistence: mkdir, create, write, setattr, and commit.
Figure 3(a) shows the results of the small file test where each client repeatedly (100 times) creates a file, writes 1K of data, and deletes the file. The test measures directory and metadata performance and models applications that generate several small files and then deletes them (for example, compilers). The results are extremely impressive with MBFS processing 313 files per second compared with NFS's 13 per second at 10 clients.
Figures 4(a) and 4(b) show the results of untaring the TCL 7.5 source code. Untar is an I/O bound program that creates multiple directories and writes a variety of file sizes (all easily recreatable from the tar file). Again, the results are perceivably faster to the user.
In all the tests MBFS outperformed both NFS and UFS (local disks). More surprising is how often MBFS challenged tmpfs performance despite the lack of callbacks in the current implementation. Similar performance tests were performed in a Linux environment with even better results since Linux's NFS version 2 does not support asynchronous writes.
Finally, we ran an edit test in which we edited various files, composed email messages, and created web pages. All files required disk persistence. As expected there was no, or minimal, performance gains.
![\begin{figure}
\center
\subfigure[Run-time scalability]{
\psfig{figure=andrew_s...
...peration Improvement]{
\psfig{figure=andrew_pie.eps,width=2.6in} }
\end{figure}](img3.gif)
![\begin{figure}
\center
\subfigure[Run-time scalability]{
\psfig{figure=metadata...
...ration Improvement]{
\psfig{figure=metadata_pie.eps,width=2.6in} }
\end{figure}](img4.gif)
![\begin{figure}
\center
\subfigure[Run-time scalability]{
\psfig{figure=untar_sc...
...Operation Improvement]{
\psfig{figure=untar_pie.eps,width=2.6in} }
\end{figure}](img6.gif)