
As we observed in section 1, Maltzahn et. al. [11] found that the Squid proxy server performs no better than the older CERN proxy under real workloads, contradicting the study by Chankhunthod et al.[5], which concluded that Harvest is an order of magnitude faster than the CERN proxy. Indeed, a simple LAN-based experiment using a simulated client load does show a big performance difference between Squid and the CERN proxy.
In an attempt to explain this peculiar result, we tried to understand why Squid's performance under real load is so much worse than under ideal conditions. One factor that is different in the two scenarios is that under real load Squid manages a much larger number of simultaneous connections than in a LAN-based test scenario. This is because of much larger delays experienced in WANs. Because WAN environments have larger round-trip times (RTTs), and are more likely to exhibit packet losses, HTTP connections tend to last much longer in WAN environments than in simple LAN environments. Therefore, for a given connection arrival rate, a WAN-based HTTP server will have more open connections than a server in a LAN environment.
Richardson's measurements of Digital's Palo Alto Web proxies [19] show between 30 and 950 simultaneously open connections, depending on time of day. Richardson's measurements also show that while the median response time is about 250 msec., the mean is 2.5 seconds: some connections stay open for a very long time. The large ratio of mean to median holds over a wide range of response sizes (although the 10:1 ratio only holds when all response sizes are considered together). This implies that at any given time, most of the open connections are cold (idle for long intervals), and only a few are hot.
Following this intuition, we tried to evaluate the effect of a large number of cold connections on Squid performance. We used DCPI [1] to profile a system running the Squid proxy under a carefully designed request load. To simulate the effect of large WAN delays, we set up a dummy HTTP client process on a client machine. This process opened a large number (100-2000) of connections to the Squid server but subsequently made no requests on these connections. We refer to this process as the load-adding client. Another process on the client machine simulated a small number (10-50) of HTTP clients, which repeatedly made HTTP requests of the proxy. Each request retrieved a 1259-byte response. We used the scalable client (S-Client) architecture from Banga and Druschel [3].
In our tests, we ran the Squid server process on an AlphaStation 500 (400Mhz 21164, 8KB I-cache, 8KB D-cache, 96KB level 2 unified cache, 2MB level 3 unified cache, SPECint95 = 12.3) equipped with 192MB of physical memory. The server operating system was Digital UNIX 4.0B, with the latest patches that were available at the time. The client machine was a 333Mhz AlphaStation 500 (same cache configuration as above, SPECint95 9.82) with 640MB of physical memory, running DUNIX 3.2C. The Squid version used was Squid-1.1.11. The client and server were connected using a 100Mbps FDDI network.
This experiment indicates that up to 53% of the system's CPU time is being spent inside select() (and its various components - selscan(), soo_select(), etc.). Up to 11% of the CPU is being spent by the user process in collating information from the bitmaps returned by select().
Our detailed results are shown in Figure 1. The x-axis represents the number of cold connections. Curves are plotted, for both 10 hot connections and 50 hot connections, showing the percentage of CPU time spent in kernel-mode functions related to select(), and the percentage of CPU time spent in the user-mode select() loop.
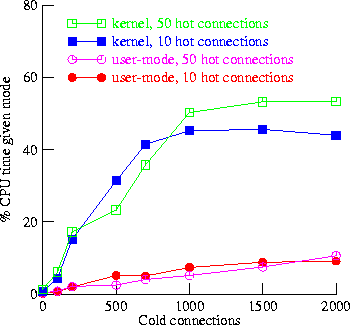
Figure 1: select() costs in unmodified kernel
Figure 1 shows that the costs of both the kernel select() implementation and the user-mode select() loop rise significantly with increasing numbers of cold connections. Also, these costs are relatively independent of the number of hot connections, up to about 1000 cold connections.
The costs are initially linear in the number of cold connections, but eventually they flatten out. As the number of cold connections increases, the system spends more CPU time in each call to select(), and so the calls to select() come less often. This causes the number of pending events returned by select() to increase (at low loads, select() usually returns just one pending event, but when called infrequently, it often returns several). The cost of each select() call is thus amortized over a larger number of interesting events. Thus, the total CPU cost of select(), which is proportional to the number of select()s per second times the cost of each select, tends to level off.
These numbers were generated with a request load of about 100 requests/second. At higher rates, select() is still important, but ufalloc() also consumes significant CPU time, because of its linear search algorithm. A typical DCPI profile for the system above, with 750 cold connections, 50 hot connections, and 220 new connections/second, is shown in Table 1.
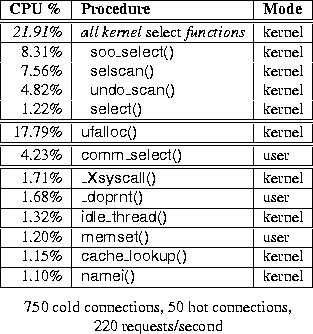
Table 1: Example profile for unmodified kernel
In summary, the current implementations of select() and ufalloc() do not scale well with the number of open connections in a server process. Both algorithms do work that is linear in the number of connections being managed by the process, and proxies in WAN environments tend to have many open connections. In the next section we will describe our implementation of scalable versions of these functions.