
We obtained CPU-time profiles, using DCPI, for the proxy server during periods of heavy load, for both the original kernel (Table 6) and our modified kernel (Table 7). Each profile covers a period of exactly one hour. The tables include all procedures accounting for at least 1% of the non-idle CPU time.
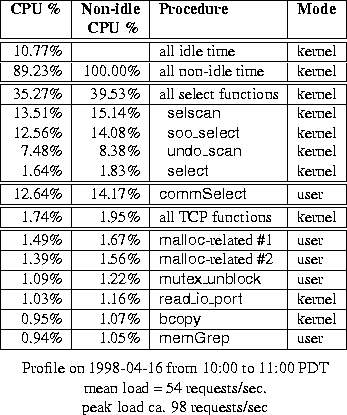
Table 6: Profile of unmodified kernel on live proxy
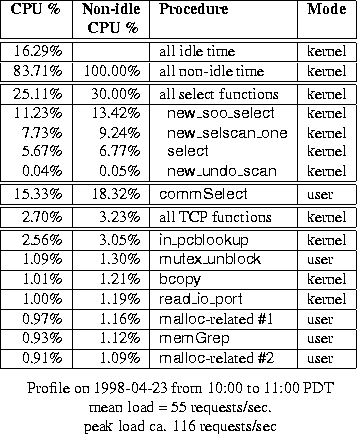
Table 7: Profile of modified kernel on live proxy
The first column in each profile shows the fraction of CPU time spent in each function or group of procedures. As the first row in each table shows, even during periods of heavy load, some time is spent in the kernel's idle thread and its children. Therefore, the second column shows the fraction of non-idle CPU time spent in all non-idle procedures; this is a more useful basis for comparing the two kernels. Note that the profiles include a mixture of kernel-mode and user-mode procedures.
The modified kernel spends 30% of the non-idle CPU time in select() and related procedures, compared to almost 40% spent in such procedures by the unmodified kernel. However, kernel-mode select() processing is still a significant burden on the CPU. As in Figure 2, considerable time is spent in the user-mode commSelect() procedure (Squid and Netcache apparently use slightly different names for the same procedure). These observations support our belief that the bitmap-based select() programming interface leads to unnecessary work, and probably to significant capacity misses in the data caches.
In experiments with simulated loads, we observed that NetCache on our
kernel calls select() about 7 times as it does on the unmodified
kernel. We believe this is because our faster select() causes a
NetCache thread to return from select() with usually only one
ready descriptor . Before the next event arrives, other NetCache threads call
select() to discover this event again. In the unmodified kernel,
each call to select() takes longer, and returns multiple events.
This may account for the heavy use of select() in
Table 7.
. Before the next event arrives, other NetCache threads call
select() to discover this event again. In the unmodified kernel,
each call to select() takes longer, and returns multiple events.
This may account for the heavy use of select() in
Table 7.
In this application, even the unmodified kernel spends very little time in ufalloc() (0.20%). However, the modified kernel spends even less time in ufalloc() (0.03%). For this proxy, the total number of open file descriptors is relatively small. However, one might expect this fraction to become more significant at higher request rates.
We are not entirely sure what caused the significant increase in time that the modified kernel spends in in_pcblookup. This may be the result of an unfortunate collision in the direct-mapped data caches.
We note that in this real-world environment, for both versions of the kernel, just over 1% of the non-idle CPU time is spent in all kernel-related data movement (the bcopy()). Even less time is spent computing checksums. A moderate amount of time (between 2% and 3%) is spent in TCP-related functions (which have been highly optimized in Digital UNIX). These measurements reinforce the emphasis placed by Kay and Pasquale[9] on ``non-data touching processing overheads''; however, they failed to recognize that the poor scalability of select() would ultimately dominate the other costs.