
In order to build the process image for a given executable file, modern operating systems need to glue together multiple modules (dynamically-linked libraries) at program load time. This happens because programs are not self-contained in terms of functionality.
The system provides service definitions to complete the image. These definitions are located using fixed resolution policies. This results in essentially the same execution environment at every run of the same program. However, as we illustrate in the introduction, there are situations in which it can be very helpful to make variations in this image. Moreover, these variations should not be limited by source code availability, nor by arbitrary rules embedded in operating system components. This motivates our interest on making the process of building the runnable image more controllable by users and programs themselves.
The goal of our research is to enable `ad-hoc' execution environments, by allowing applications to build appropriate execution environments for themselves, according to performance requirements, efficiency concerns and functionality needs. This covers the improvement or tuning of services (e.g. service specialization or result `memoization' - see [17]), the addition of new functionality to do data stream processing (e.g. encryption or compression) or to perform new tasks (e.g. cooperation with resource managers), and even restructuring the execution environment (e.g. code co-location and distribution).
In Figure 1 we show the phases in which we conceptually divide the process of executing a program. Two scenarios are shown: the usual one (left side) and the extended one (right side). The meaning of each stage is as follows: loading brings all the required modules into the address space, reference resolution finds definitions for unresolved references, extension introduces new modules in the address space, binding allows to customize bindings, execution enters application code, termination exits application code and cleanup shuts down extensions. For each stage, we show which inputs determine its behavior. The stages shaded and surrounded by thick lines are provided by our tools.
In the extension stage, we check for the need of extending the image using configuration information that can change at every run. If extensions are needed, the right modules are introduced in the process image. Then, the binding stage arranges these modules to be executed by setting up bindings appropriately. This stage is independent from the previous one. Therefore, it is possible to modify bindings without loading extensions.
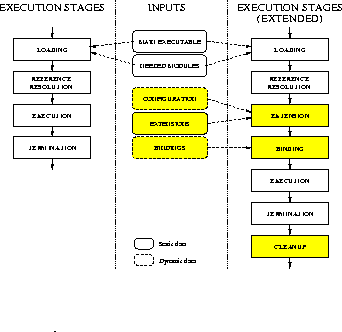
Figure 1: Usual and extended execution stages
The tools described in this paper introduce an extension to the runtime loader and linker. This extension provides basic functionality to load and bind unforeseen modules and services, as well as to reconsider actual bindings. This functionality works entirely at user-level and complements the traditional dynamic loading and linking services. This is achieved by means of additional stages after program loading, devoted to adapt/extend the execution environment. These tools also export services, making them available during execution, to allow on-the-fly adaptation.
These tools are being used by various projects in our department for trace collection, scheduling research and I/O research. They have helped us to test the stability and validity of our services and abstractions.