| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX '05 Paper
[USENIX '05 Technical Program]
Maintaining High Bandwidth under Dynamic Network ConditionsDejan Kostic, Ryan Braud, Charles Killian, Erik Vandekieft, James W. Anderson, Alex C. Snoeren and Amin Vahdat 1 Department of Computer Science and Engineering University of California, San Diego
Abstract:
The need to distribute large files across multiple wide-area sites is
becoming increasingly common, for instance, in support of scientific
computing, configuring distributed systems, distributing software
updates such as open source ISOs or Windows patches, or disseminating
multimedia content. Recently a number of techniques have been proposed
for simultaneously retrieving portions of a file from multiple remote
sites with the twin goals of filling the client's pipe and overcoming
any performance bottlenecks between the client and any individual
server. While there are a number of interesting tradeoffs in locating
appropriate download sites in the face of dynamically changing network
conditions, to date there has been no systematic evaluation of the
merits of different protocols. This paper explores the design space of
file distribution protocols and conducts a detailed performance
evaluation of a number of competing systems running in both controlled
emulation environments and live across the Internet. Based on our
experience with these systems under a variety of conditions,
we propose, implement and evaluate Bullet
The rapid, reliable, and efficient transmission of a data object from
a single source to a large number of receivers spread across the
Internet has long been the subject of research and development
spanning computer systems, networking, algorithms, and theory.
Initial attempts at addressing this problem focused on IP multicast, a
network level primitive for constructing efficient IP-level trees to
deliver individual packets from the source to each receiver.
Fundamental problems with reliability, congestion control,
heterogeneity, and deployment limited the widespread success and
availability of IP multicast. Building on the experience gained from
IP multicast, a number of efforts then focused on building application-level overlays [2,9,10,12,24] where a source would transmit the content,
for instance over multiple TCP connections, to a set of receivers that
would implicitly act as interior nodes in a tree built up at the
application level.
|
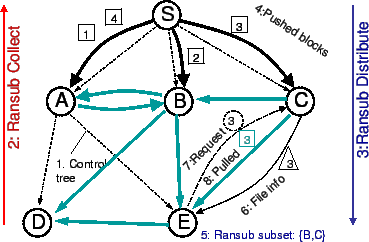 |
Figure 1 depicts the architectural overview of
Bullet![]() . We use an overlay tree for joining the system and for
transmitting control information (shown in thin dashed lines, as step
1). We use RanSub [12], a scalable, decentralized
protocol, to distribute changing, uniformly random subsets of
file summaries over the control tree (steps 2 and 3). The source pushes
the file blocks to children in the control tree (step 4). Using RanSub,
nodes advertise their identity and the block availability. Receivers use this information (step 5) to choose a set of
senders to peer with, receive their file information (step 6),
request (step 7) and subsequently receive (step 8) file blocks,
effectively establishing an overlay mesh on top of the underlying control tree. Moreover, receivers make
local decisions on the number of senders as well as the amount
of outstanding data, adjusting the overlay mesh over time to conform to
the characteristics of the underlying network. Meanwhile, senders keep
their receivers updated with the description of their newly received
file blocks (step 6). The specifics of our implementation are
described below.
. We use an overlay tree for joining the system and for
transmitting control information (shown in thin dashed lines, as step
1). We use RanSub [12], a scalable, decentralized
protocol, to distribute changing, uniformly random subsets of
file summaries over the control tree (steps 2 and 3). The source pushes
the file blocks to children in the control tree (step 4). Using RanSub,
nodes advertise their identity and the block availability. Receivers use this information (step 5) to choose a set of
senders to peer with, receive their file information (step 6),
request (step 7) and subsequently receive (step 8) file blocks,
effectively establishing an overlay mesh on top of the underlying control tree. Moreover, receivers make
local decisions on the number of senders as well as the amount
of outstanding data, adjusting the overlay mesh over time to conform to
the characteristics of the underlying network. Meanwhile, senders keep
their receivers updated with the description of their newly received
file blocks (step 6). The specifics of our implementation are
described below.
We have implemented Bullet![]() using MACEDON. MACEDON [22]
is a tool which makes
the development of large scale distributed systems simpler by allowing us
to specify the overlay network algorithm without simultaneously
implementing code to handle data transmission, timers, etc. The
implementation of Bullet
using MACEDON. MACEDON [22]
is a tool which makes
the development of large scale distributed systems simpler by allowing us
to specify the overlay network algorithm without simultaneously
implementing code to handle data transmission, timers, etc. The
implementation of Bullet![]() consists of a generic file distribution
application, the Bullet
consists of a generic file distribution
application, the Bullet![]() overlay network algorithm, the existing basic
random tree and RanSub algorithms, and the library code in MACEDON.
overlay network algorithm, the existing basic
random tree and RanSub algorithms, and the library code in MACEDON.
The generic download application implemented for Bullet![]() can operate in
either encoded or unencoded mode. In the encoded mode, it operates by
generating continually increasing block numbers and transmitting them using
macedon_multicast on the overlay algorithm. In unencoded mode, it
operates by transmitting the blocks of the file once using macedon_multicast. This makes it possible for us to compare download
performance over the set of overlays specified in MACEDON. In both encoded
and unencoded cases, the download application also supports a request
function from the overlay network to provide the block of a given sequence
number, if available, for transmission. The download application also
supports the reconstruction of the file from the data blocks delivered to
it by the overlay. The download application is parameterized and can take
as parameters block size and file name.
can operate in
either encoded or unencoded mode. In the encoded mode, it operates by
generating continually increasing block numbers and transmitting them using
macedon_multicast on the overlay algorithm. In unencoded mode, it
operates by transmitting the blocks of the file once using macedon_multicast. This makes it possible for us to compare download
performance over the set of overlays specified in MACEDON. In both encoded
and unencoded cases, the download application also supports a request
function from the overlay network to provide the block of a given sequence
number, if available, for transmission. The download application also
supports the reconstruction of the file from the data blocks delivered to
it by the overlay. The download application is parameterized and can take
as parameters block size and file name.
RanSub is the protocol we use for distributing
uniformly random subsets of peers to all nodes in the overlay. Unlike
a centralized solution or one which requires state on the order of the
size of the overlay, Ransub is decentralized and can scale better with
both the number of nodes and the state maintained.
RanSub requires an overlay tree to propagate random subsets,
and in Bullet![]() we use the control tree for this purpose. RanSub
works by periodically distributing a message to all members of the
overlay, and then collecting data back up the tree. At each layer of
the tree, data is randomized and compacted, assuring that all peers
see a changing, uniformly random subset of data. The period
of this distribute and collect is configurable, but for Bullet
we use the control tree for this purpose. RanSub
works by periodically distributing a message to all members of the
overlay, and then collecting data back up the tree. At each layer of
the tree, data is randomized and compacted, assuring that all peers
see a changing, uniformly random subset of data. The period
of this distribute and collect is configurable, but for Bullet![]() , it is
set for 5 seconds. Also, by decentralizing the random subset
distribution, we can include more application-state, an abstract which
nodes can use to make more intelligent decisions about which nodes
would be good to peer with.
, it is
set for 5 seconds. Also, by decentralizing the random subset
distribution, we can include more application-state, an abstract which
nodes can use to make more intelligent decisions about which nodes
would be good to peer with.
In order for nodes to fill their pipes with useful data, it is
imperative that they are able to locate and maintain a set of peers
that can provide them with good service. In the face of bandwidth
changes and unstable network conditions, keeping a fixed number of
peers is suboptimal (see Section 4.4). Not only
must Bullet![]() discard peers whose service degrades, it must also
adaptively decide how many peers it should be downloading from/sending
to. Note that peering relationships are not inherently bidirectional;
two nodes wishing to receive data from each other must establish
peering links separately. Here we use the term ``sender'' to refer to
a peer a node is receiving data from and ``receiver'' to refer to a
peer a node is sending data to.
discard peers whose service degrades, it must also
adaptively decide how many peers it should be downloading from/sending
to. Note that peering relationships are not inherently bidirectional;
two nodes wishing to receive data from each other must establish
peering links separately. Here we use the term ``sender'' to refer to
a peer a node is receiving data from and ``receiver'' to refer to a
peer a node is sending data to.
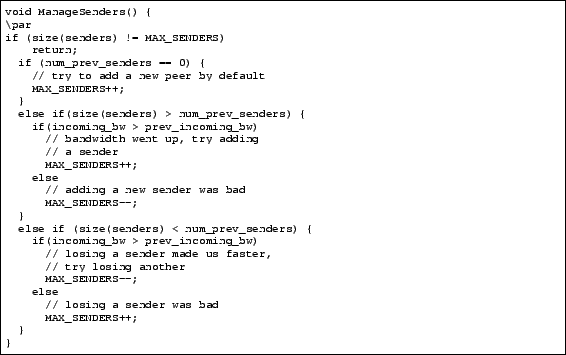
Each node maintains two variables, namely MAX_SENDERS and MAX_RECEIVERS, which specify how many senders and receivers the node
wishes to have at maximum. Initially, these values are set to 10,
the value we have experimentally chosen for the released
version of Bullet. Bullet![]() also imposes hard limits of 6 and 25 for
the number of minimum/maximum senders and receivers. Each time a node
receives a RanSub distribute message containing a random subset of
peers and the summaries of their file content, it makes an evaluation
about its current peer sets and decides whether it should add or
remove both senders and receivers. If the node has its current
maximum number of senders, it makes a decision as to whether it should
either ``try out'' a new connection or close a current connection
based on the number of senders and bandwidth received when the last
distribute message arrived. A similar mechanism is used to handle
adding/removing receivers, except in this case Bullet
also imposes hard limits of 6 and 25 for
the number of minimum/maximum senders and receivers. Each time a node
receives a RanSub distribute message containing a random subset of
peers and the summaries of their file content, it makes an evaluation
about its current peer sets and decides whether it should add or
remove both senders and receivers. If the node has its current
maximum number of senders, it makes a decision as to whether it should
either ``try out'' a new connection or close a current connection
based on the number of senders and bandwidth received when the last
distribute message arrived. A similar mechanism is used to handle
adding/removing receivers, except in this case Bullet![]() uses outgoing
bandwidth instead of incoming bandwidth.
Figure 2 shows the pseudocode for
managing senders.
uses outgoing
bandwidth instead of incoming bandwidth.
Figure 2 shows the pseudocode for
managing senders.
Once MAX_SENDERS and MAX_RECEIVERS have been modified,
Bullet![]() calculates the average and standard deviation of bandwidth
received from all of its senders. It then sorts the senders in order
of least bandwidth received to most, and disconnects itself from any
sender who is more than 1.5 standard deviations away from the mean, so
long as it does not drop below the minimum number of connections (6).
This way, Bullet
calculates the average and standard deviation of bandwidth
received from all of its senders. It then sorts the senders in order
of least bandwidth received to most, and disconnects itself from any
sender who is more than 1.5 standard deviations away from the mean, so
long as it does not drop below the minimum number of connections (6).
This way, Bullet![]() is able to keep only the peers who are the most
useful to it. A fixed minimum bandwidth was not used so as to not
hamper nodes who are legitimately slow. In addition, the slowest
sender is not always closed since if all of a peer's senders are
approximately equal in terms of bandwidth provided, then none of them
should be closed.
is able to keep only the peers who are the most
useful to it. A fixed minimum bandwidth was not used so as to not
hamper nodes who are legitimately slow. In addition, the slowest
sender is not always closed since if all of a peer's senders are
approximately equal in terms of bandwidth provided, then none of them
should be closed.
A nearly identical procedure is executed to remove receivers who are
potentially limiting the outgoing bandwidth of a node. However,
Bullet![]() takes care to sort receivers based on the ratio of their
bandwidth they are receiving from a particular sender to
their total incoming bandwidth. This is important because we do not
want to close peers who are getting a large fraction of their
bandwidth from a given sender. We chose the value of 1.5
standard deviations because 1 would lead to too many nodes being
closed whereas 2 would only permit a very few peers to ever be closed.
takes care to sort receivers based on the ratio of their
bandwidth they are receiving from a particular sender to
their total incoming bandwidth. This is important because we do not
want to close peers who are getting a large fraction of their
bandwidth from a given sender. We chose the value of 1.5
standard deviations because 1 would lead to too many nodes being
closed whereas 2 would only permit a very few peers to ever be closed.
In order to decide which strategy worked the best, we implemented all four
in Bullet![]() .
We present our findings in Section 4.3.
.
We present our findings in Section 4.3.
As seen in Section 4.5, using a fixed number of
outstanding blocks will not perform well under a wide variety of
conditions. To remedy this situation, Bullet![]() employs a novel flow
control algorithm that attempts to dynamically change the maximum
number of blocks a node is willing to have outstanding from each of
its peers. Our control algorithm is similar to
XCP's [11] efficiency controller, the feedback control loop
for calculating the aggregate feedback for all the flows traversing a
link. XCP measures the difference in the rates of incoming
and outgoing traffic on a link, and computes the total number of bytes
by which the flows' congestion windows should increase or
decrease. XCP's goal is to maintain 0 packets queued on the bottleneck
link. For the particular values of control parameters
employs a novel flow
control algorithm that attempts to dynamically change the maximum
number of blocks a node is willing to have outstanding from each of
its peers. Our control algorithm is similar to
XCP's [11] efficiency controller, the feedback control loop
for calculating the aggregate feedback for all the flows traversing a
link. XCP measures the difference in the rates of incoming
and outgoing traffic on a link, and computes the total number of bytes
by which the flows' congestion windows should increase or
decrease. XCP's goal is to maintain 0 packets queued on the bottleneck
link. For the particular values of control parameters
![]() , the control loop is stable for any link
bandwidth and delay.
, the control loop is stable for any link
bandwidth and delay.
We start with the original XCP formula and adapt it. Since we want to keep each pipe full while not risking waiting for too much data in case the TCP connection slows down, our goal is to maintain exactly 1 block in front of the TCP socket buffer, for each peer. With each block it sends, sender measures and reports two values to the receiver that runs the algorithm depicted in Figure 3 in the pseudocode. The first value is in_front, corresponding to the number of queued blocks in front of the socket buffer when the request for the particular block arrives. The second value is wasted, and it can be either positive or negative. If it is negative, it corresponds to the time that is ``wasted'' and could have been occupied by sending blocks. If it is positive, it represents the ``service'' time this block has spent waiting in the queue. Since this time includes the time to service each of the in_front blocks, we take care not to double count the service time in this case. To convert the wasted (service) time into units applicable to the formula, we multiply it by the bandwidth measured at the receiver, and divide by block size to derive the additional (reduced) number of blocks receiver could have requested. Once we decide to change the number of outstanding blocks, we mark a block request and do not make any adjustments until that block arrives. This technique allows us to observe any changes caused by our control algorithm before taking any additional action. Further, just matching the rate at which the blocks are requested with the sending bandwidth in an XCP manner would not saturate the TCP connection. Therefore, we take the ceiling of the non-integer value for the desired number of outstanding blocks whenever we increase this value.
Although Bullet![]() knows how much data it should request and from
whom, a mechanism is still needed that specifies when the requests
should be made. Initially, the number of blocks outstanding for all
peers starts at 3, so when a node gains a sender it will request up to
3 blocks from the new peer. Conceptually, this corresponds
to the pipeline of one block arriving at the receiver, with one more
in-flight, and the request for the third block reaching the sender.Whenever a block is received, the node re-evaluates the potential from
this peer and requests up to the new maximum outstanding.
knows how much data it should request and from
whom, a mechanism is still needed that specifies when the requests
should be made. Initially, the number of blocks outstanding for all
peers starts at 3, so when a node gains a sender it will request up to
3 blocks from the new peer. Conceptually, this corresponds
to the pipeline of one block arriving at the receiver, with one more
in-flight, and the request for the third block reaching the sender.Whenever a block is received, the node re-evaluates the potential from
this peer and requests up to the new maximum outstanding.
As mentioned previously, Bullet![]() uses a hybrid push/pull approach for
data distribution where the source behaves differently from everyone
else. The source takes a rather simple approach: it sends a block to
each of its RanSub children iteratively until the entire file has been
sent. If a block cannot be sent to one child (because the pipe to it
is already full), the source will try the next child in a round robin
fashion until a suitable recipient is found. In this manner, the
source never wastes bandwidth forcing a block on a node that is not
ready to accept it. Once the source makes each of the file blocks
available to the system, it will advertise itself in RanSub so that
arbitrary nodes can benefit from having a peer with all of the file
blocks.
uses a hybrid push/pull approach for
data distribution where the source behaves differently from everyone
else. The source takes a rather simple approach: it sends a block to
each of its RanSub children iteratively until the entire file has been
sent. If a block cannot be sent to one child (because the pipe to it
is already full), the source will try the next child in a round robin
fashion until a suitable recipient is found. In this manner, the
source never wastes bandwidth forcing a block on a node that is not
ready to accept it. Once the source makes each of the file blocks
available to the system, it will advertise itself in RanSub so that
arbitrary nodes can benefit from having a peer with all of the file
blocks.
From the perspective of non-source nodes, determining the order in
which to send requested blocks is equally as simple. Since Bullet![]() dynamically determines the number of outstanding requests, nodes
should always have approximately one outstanding request at the
application level on any peer at any one time. As a result, the sender
can simply serve requests in FIFO order since there is not much of a
choice to make among such few blocks. Note that this approach would
not be optimal for all systems, but since Bullet
dynamically determines the number of outstanding requests, nodes
should always have approximately one outstanding request at the
application level on any peer at any one time. As a result, the sender
can simply serve requests in FIFO order since there is not much of a
choice to make among such few blocks. Note that this approach would
not be optimal for all systems, but since Bullet![]() dynamically adjusts
the number of requests to have outstanding for each peer, it works
well.
dynamically adjusts
the number of requests to have outstanding for each peer, it works
well.
To conduct a rigorous analysis of our various design
tradeoffs, we needed to construct a controlled experimental
environment where we could conduct multiple tests under identical
conditions. Rather than attempt to construct a necessarily small
isolated network test-bed, we present results from experiments using
the ModelNet [28] network emulator, which allowed us to
evaluate Bullet![]() on topologies consisting of 100 nodes or more. In
addition, we present experimental results over the wide-area network
using the PlanetLab [20] testbed.
on topologies consisting of 100 nodes or more. In
addition, we present experimental results over the wide-area network
using the PlanetLab [20] testbed.
Our ModelNet experiments make use of 25 2.0 and 2.8-Ghz Pentium-4s running Xeno-Linux 2.4.27 and interconnected by 100-Mbps and 1-Gbps Ethernet switches. In the experiments presented here, we multiplex one hundred logical end nodes running our download applications across the 25 Linux nodes (4 per machine). ModelNet routes packets from the end nodes through an emulator responsible for accurately emulating the hop-by-hop delay, bandwidth, and congestion of a given network topology; a 1.4-Ghz Pentium III running FreeBSD-4.7 served as the emulator for these experiments.
All of our experiments are run on a fully interconnected mesh topology, where each pair of overlay participants are directly connected. While admittedly not representative of actual Internet topologies, it allows us maximum flexibility to affect the bandwidth and loss rate between any two peers. The inbound and outbound access links of each node are set to 6 Mbps, while the nominal bandwidth on the core links is 2 Mbps. In an attempt to model the wide-area environment [21], we configure ModelNet to randomly drop packets on the core links with probability ranging from 0 to 3 percent. The loss rate on each link is chosen uniformly at random and fixed for the duration of an experiment. To approximate the latencies in the Internet [7,21], we set the propagation delay on the core links uniformly at random between 5 and 200 milliseconds, while the access links have one millisecond delay.
For most of the following sections, we conduct identical experiments in two scenarios: a static bandwidth case and a variable bandwidth case. Our bandwidth-change scenario models changes in the network bandwidth that correspond to correlated and cumulative decreases in bandwidth from a large set of sources from any vantage point. To effect these changes, we decrease the bandwidth in the core links with a period of 20 seconds. At the beginning of each period, we choose 50 percent of the overlay participants uniformly at random. For each participant selected, we then randomly choose 50 percent of the other overlay participants and decrease the bandwidth on the core links from those nodes to 50 percent of the current value, without affecting the links in the reverse direction. The changes we make are cumulative; i.e., it is possible for an unlucky node pair to have 25% of the original bandwidth after two iterations. We do not alter the physical link loss rates that were chosen during topology generation.
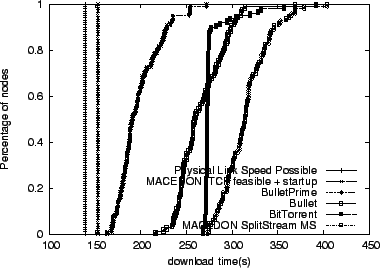
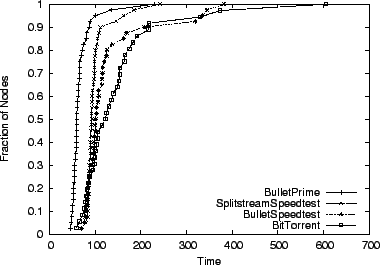
We begin by studying how Bullet![]() performs overall, using the
existing best-of-breed systems as comparison points. For reference,
we also calculate the best achievable performance given the overhead
of our underlying transport protocols. Figure 4 plots
the results of downloading a 100-MB file on our ModelNet topology
using a number of different systems. The graph plots the cumulative
distribution function of node completion times for four experimental
runs and two calculations. Starting at the left, we plot download
times that are optimal with respect to access link bandwidth in the
absence of any protocol overhead. We then estimate the best possible
performance of a system built using MACEDON on top of TCP, accounting
for the inherent delay required for nodes to achieve maximum download
rate. The remaining four lines show the performance of Bullet
performs overall, using the
existing best-of-breed systems as comparison points. For reference,
we also calculate the best achievable performance given the overhead
of our underlying transport protocols. Figure 4 plots
the results of downloading a 100-MB file on our ModelNet topology
using a number of different systems. The graph plots the cumulative
distribution function of node completion times for four experimental
runs and two calculations. Starting at the left, we plot download
times that are optimal with respect to access link bandwidth in the
absence of any protocol overhead. We then estimate the best possible
performance of a system built using MACEDON on top of TCP, accounting
for the inherent delay required for nodes to achieve maximum download
rate. The remaining four lines show the performance of Bullet![]() running in the unencoded mode, Bullet, and BitTorrent, our MACEDON
SplitStream implementation, in roughly that order. Bullet
running in the unencoded mode, Bullet, and BitTorrent, our MACEDON
SplitStream implementation, in roughly that order. Bullet![]() clearly
outperforms all other schemes by approximately 25%. The
slowest Bullet
clearly
outperforms all other schemes by approximately 25%. The
slowest Bullet![]() receiver finishes downloading 37% faster than for
other systems. Bullet
receiver finishes downloading 37% faster than for
other systems. Bullet![]() 's performance is even better in the dynamic
scenario (faster by 32%-70%), shown in
Figure 5.
's performance is even better in the dynamic
scenario (faster by 32%-70%), shown in
Figure 5.
We set the transfer block size to 16 KB in all of our experiments. This value corresponds to BitTorrent's subpiece size of 16KB, and is also shared by the Bullet and SplitStream. For all of our experiments, we make sure that there is enough physical memory on the machines hosting the overlay participants to cache the entire file content in memory. Our goal is to concentrate on distributed algorithm performance and not worry about swapping file blocks to and from the disk. Bullet and SplitStream results are optimistic since we do not perform encoding and decoding of the file. Instead, we set the encoding overhead to 4% and declare the file complete when a node has received enough file blocks.
 |
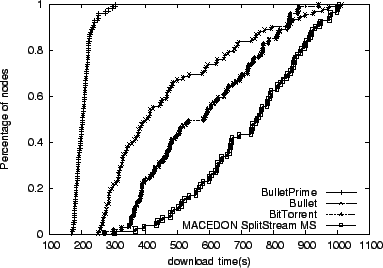 |
Heartened by the performance of Bullet![]() with respect to other
systems, we now focus our attention on the various critical aspects of
our design that we believe contribute to Bullet
with respect to other
systems, we now focus our attention on the various critical aspects of
our design that we believe contribute to Bullet![]() 's superior
performance. Figure 6 shows the
performance of Bullet
's superior
performance. Figure 6 shows the
performance of Bullet![]() using three different peer request
strategies, again using the CDF of node completion times. In this
case each node is downloading a 100 MB file. We argue the goal of a
request strategy is to promote block diversity in the system, allowing
nodes to help each other. Not surprisingly, we see that the first-encountered request strategy performs the worst. While the
rarest-random performs best among the strategies considered for 70%
of the receivers. For the slowest nodes, the random strategy performs
better.
When a receiver is downloading from senders over lossy links, higher
loss rates increase the latency of block availability messages due to
TCP retransmissions and use of the congestion avoidance
mechanism. Subsequently, choosing the next block to download uniformly
at random does a better job of improving diversity than the
rarest-random strategy that operates on potentially stale information.
using three different peer request
strategies, again using the CDF of node completion times. In this
case each node is downloading a 100 MB file. We argue the goal of a
request strategy is to promote block diversity in the system, allowing
nodes to help each other. Not surprisingly, we see that the first-encountered request strategy performs the worst. While the
rarest-random performs best among the strategies considered for 70%
of the receivers. For the slowest nodes, the random strategy performs
better.
When a receiver is downloading from senders over lossy links, higher
loss rates increase the latency of block availability messages due to
TCP retransmissions and use of the congestion avoidance
mechanism. Subsequently, choosing the next block to download uniformly
at random does a better job of improving diversity than the
rarest-random strategy that operates on potentially stale information.
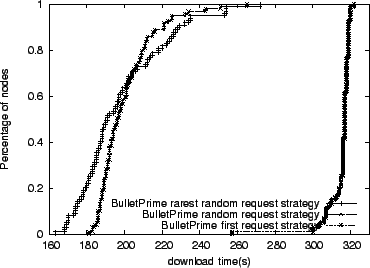 |
In this section we demonstrate the impossibility of choosing a single
optimal number of senders and receivers for each peer in the system,
arguing for a dynamic approach. In Figure 7 we contrast
Bullet![]() 's performance with 10 and 14 peers (for both senders and
receivers) while downloading a 100 MB file. The system configured with
14 peers outperforms the one with 10 because in a lossy topology like
the one we are using, having more TCP flows makes the node's incoming
bandwidth more resilient to packet losses. Our dynamic approach is
configured to start with 10 senders and receivers, but it closely
tracks the performance of the system with the number of peers fixed to
14 for 50% of receivers. Under synthetic bandwidth
changes (Figure 8), our dynamic approach
matches, and sometimes exceeds the performance of static setups.
's performance with 10 and 14 peers (for both senders and
receivers) while downloading a 100 MB file. The system configured with
14 peers outperforms the one with 10 because in a lossy topology like
the one we are using, having more TCP flows makes the node's incoming
bandwidth more resilient to packet losses. Our dynamic approach is
configured to start with 10 senders and receivers, but it closely
tracks the performance of the system with the number of peers fixed to
14 for 50% of receivers. Under synthetic bandwidth
changes (Figure 8), our dynamic approach
matches, and sometimes exceeds the performance of static setups.
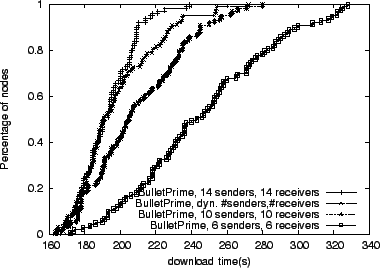 |
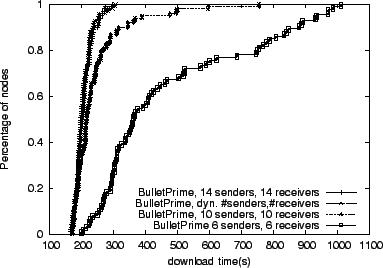 |
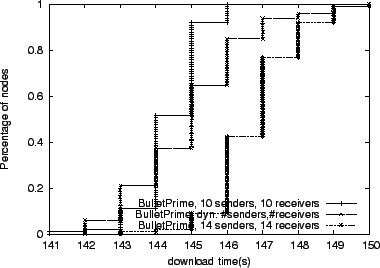 |
For our final peering example, we construct a 100 node topology with
ample bandwidth in the core (10Mbps, 1ms latency links) with 800 Kbps
access links and without random network packet
losses. Figure 9 shows that, unlike in the
previous experiments, Bullet![]() configured for 14 peers performs worse than in a setup with 10 peers. Having more peers in this
constrained environment forces more maximizing TCP connections to
compete for bandwidth. In addition, maintaining more peers requires
sending more control messages, further decreasing the system
performance. Our dynamic approach tracks, and sometimes exceeds, the
performance of the better static setup.
configured for 14 peers performs worse than in a setup with 10 peers. Having more peers in this
constrained environment forces more maximizing TCP connections to
compete for bandwidth. In addition, maintaining more peers requires
sending more control messages, further decreasing the system
performance. Our dynamic approach tracks, and sometimes exceeds, the
performance of the better static setup.
These cases clearly demonstrate that no statically configured peer set size is appropriate for a wide range of network environments, and a well-tuned system must dynamically determine the appropriate peer set size.
We now explore determining the optimal number of per-peer
outstanding requests. Other systems use a fixed number of outstanding
blocks. For example, BitTorrent tries to maintain five outstanding
blocks from each peer by default. For the experiments in this section,
we use an 8KB block, and configure the Linux kernel to allow large
receiver window sizes. In our first topology, there are 25
participants, interconnected with 10Mbps links with 100ms latency. In
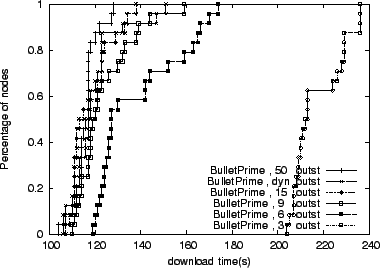
Figure 10 we show Bullet![]() 's performance when
configured with 3, 6, 9, 15, and 50 per-peer outstanding blocks for up
to 5 senders. The number of outstanding requests refers to the total number of block requests to any given peer, including blocks
that are queued for sending, and blocks and requests that are
in-flight.
As we can see, the dynamic technique closely tracks the performance of
cases with a large number of outstanding blocks. Having too few
outstanding requests is not enough to fill the bandwidth-delay product
of high-bandwidth, high-latency links.
's performance when
configured with 3, 6, 9, 15, and 50 per-peer outstanding blocks for up
to 5 senders. The number of outstanding requests refers to the total number of block requests to any given peer, including blocks
that are queued for sending, and blocks and requests that are
in-flight.
As we can see, the dynamic technique closely tracks the performance of
cases with a large number of outstanding blocks. Having too few
outstanding requests is not enough to fill the bandwidth-delay product
of high-bandwidth, high-latency links.
 |
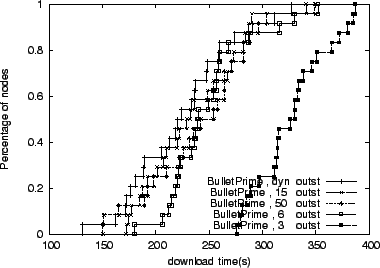
Although it is tempting to simplify the system by requesting the maximum
number of blocks from each peer, Figure 11
illustrates the penalty of requesting more blocks than it is required
to saturate the TCP connection. In this experiment, we instruct
ModelNet to drop packets uniformly at random with probability ranging
between ![]() and
and ![]() percent on the core links. Due to losses, TCP
achieves lower bandwidths, requiring less data in-flight for maximum
performance. Under these loss-induced TCP throughput fluctuations,
our dynamic approach outperforms all static
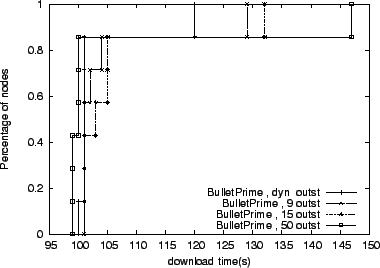
cases. Figure 12 provides more insight into this
case.
For this experiment, we have 8 participants including
the source, with 6 nodes receiving data from the source and reconciling
among each other over 10Mbps, 1ms latency links. We use 8KB blocks
and disable peer management. The 8th node is only downloading from the
6 peers over dedicated 5Mbps, 100ms latency links. Every 25 seconds,
we choose another peer from these 6, and reduce the bandwidth on its
link toward the 8th node to 100Kbps. These cascading bandwidth
changes are cumulative, i.e. in the end, the 8th node will have only
100Kbps links from its peers. Our dynamic scheme outperforms all fixed
sizing choices for the slowest, 8th node, by 7 to 22 percent. Placing
too many requests on a connection to a node that suddenly slows down
forces the receiver to wait too long for these blocks to arrive,
instead of retrieving them from some other peer.
percent on the core links. Due to losses, TCP
achieves lower bandwidths, requiring less data in-flight for maximum
performance. Under these loss-induced TCP throughput fluctuations,
our dynamic approach outperforms all static
cases. Figure 12 provides more insight into this
case.
For this experiment, we have 8 participants including
the source, with 6 nodes receiving data from the source and reconciling
among each other over 10Mbps, 1ms latency links. We use 8KB blocks
and disable peer management. The 8th node is only downloading from the
6 peers over dedicated 5Mbps, 100ms latency links. Every 25 seconds,
we choose another peer from these 6, and reduce the bandwidth on its
link toward the 8th node to 100Kbps. These cascading bandwidth
changes are cumulative, i.e. in the end, the 8th node will have only
100Kbps links from its peers. Our dynamic scheme outperforms all fixed
sizing choices for the slowest, 8th node, by 7 to 22 percent. Placing
too many requests on a connection to a node that suddenly slows down
forces the receiver to wait too long for these blocks to arrive,
instead of retrieving them from some other peer.
 |
 |
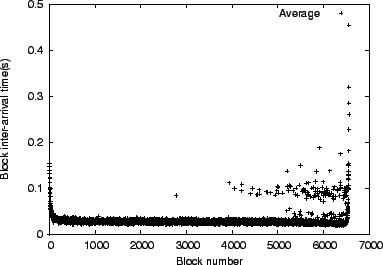 |
The purpose of this section is to quantify the potential benefits of
encoding the file at the source. Towards this end, Figure
13 shows the average block
inter-arrival times among the 99 receivers, while downloading a 100MB
file. To improve the readability of the graph, we do not show the
maximum block inter-arrival times, which observe a similar trend. A
system that has a pronounced ``last-block'' problem would exhibit a
sharp increase in the block inter-arrival time for the last several
blocks. To quantify the potential benefits of encoding, we first
compute the overall average block inter-arrival time ![]() . We then
consider the last twenty blocks and calculate the cumulative overage
of the average block inter-arrival time over
. We then
consider the last twenty blocks and calculate the cumulative overage
of the average block inter-arrival time over ![]() . In this case
overage amounts to 8.38 seconds. We contrast this value to the
potential increase in the download time due to a fixed 4 percent
encoding overhead of 7.60 seconds, while optimistically assuming that
downloads using source encoding would not exhibit any deviation in the
download times of the last few blocks. We conclude that encoding at
the source in this scenario would not be of clear benefit
in improving the average download time. This finding can be explained
by the presence of a large number of nodes that will have a particular
block and will be available to send it to other
participants. Encoding at the source or within the network can be
useful when the source becomes unavailable soon after sending the file
once and with node churn [8].
. In this case
overage amounts to 8.38 seconds. We contrast this value to the
potential increase in the download time due to a fixed 4 percent
encoding overhead of 7.60 seconds, while optimistically assuming that
downloads using source encoding would not exhibit any deviation in the
download times of the last few blocks. We conclude that encoding at
the source in this scenario would not be of clear benefit
in improving the average download time. This finding can be explained
by the presence of a large number of nodes that will have a particular
block and will be available to send it to other
participants. Encoding at the source or within the network can be
useful when the source becomes unavailable soon after sending the file
once and with node churn [8].
 |
This section presents Shotgun, a set of extensions to the popular
rsync [27] tool to enable clients to synchronize their state with
a centralized server orders of magnitude more quickly than previously
possible. At a high-level, Shotgun works by wrapping appropriate
interfaces to Bullet![]() around
rsync. Shotgun is useful, for example, for a user who wants to
run an experiment on a set of PlanetLab[20]
nodes. Because each node only has local storage, the user must somehow
copy (using scp or
rsync) her program files to each node individually. Each
time she makes any change to her program, she must re-copy the updated
files to all the nodes she is using. If the experiment spans hundreds
of nodes, then copying the files requires opening hundreds of ssh
connections, all of which compete for bandwidth.
around
rsync. Shotgun is useful, for example, for a user who wants to
run an experiment on a set of PlanetLab[20]
nodes. Because each node only has local storage, the user must somehow
copy (using scp or
rsync) her program files to each node individually. Each
time she makes any change to her program, she must re-copy the updated
files to all the nodes she is using. If the experiment spans hundreds
of nodes, then copying the files requires opening hundreds of ssh
connections, all of which compete for bandwidth.
To use Shotgun, the user simply starts shotgund, the Shotgun multicast daemon, on each of his nodes. To distribute an update, the user runs shotgun_sync, providing as arguments a path to the new software image, a path to the current software image, and the host name of the source of the Shotgun multicast tree (this can be the local machine). Next, shotgun_sync runs rsync in batch mode between the two software image paths, generating a set of logs describing the differences and records the version numbers of the old and new files. shotgun_sync then archives the logs into a single tar file and sends it to the source, which then rapidly disseminates it to all the clients using the multicast overlay. Each client's shotgund will download the update, and then invoke shotgun_sync locally to apply the update if the update's version is greater than the node's current version.
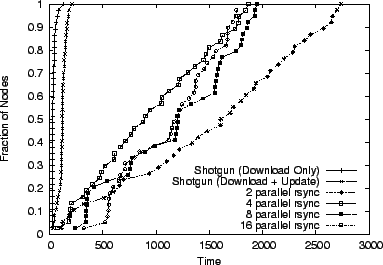 |
Running an rsync instance for each target node overloads the source node's CPU with a large number of rsync processes all competing for the disk, CPU, and bandwidth. Therefore, we have attempted to experimentally determine the number of simultaneous rsync processes that give the optimal overall performance using the staggered approach. Figure 15 shows that Shotgun outperforms rsync (1, 2, 4, 8, and 16 parallel instances) by two orders of magnitude. Another interesting result from this graph is that the constraining factor for PlanetLab nodes is the disk, not the network. On average, most nodes spent twice as much time replaying the rsync logs locally then they spent downloading the data.
Overcast [10] constructs a bandwidth-optimized overlay tree among dedicated infrastructure nodes. An incoming node joins at the source and probes for acceptable bandwidth under one if its siblings to descend down the tree. A node's bandwidth and reliability is determined by characteristics of the network between itself and its parent and is lower than the performance and reliability provided by an overlay mesh.
Narada [9] constructs a mesh based on a k-spanner graph, and uses bandwidth and latency probing to improve the quality of the mesh. It then employs standard routing algorithms to compute per-source forwarding trees, in which a node's performance is still defined by connectivity to its parent. In addition, the group membership protocol limits the scale of the system.
Snoeren et al. [26] use an overlay mesh to send
XML-encoded data. The mesh is structured by enforcing ![]() parents for
each participant. The emphasis of this primarily push-based system is
on reliability and timely delivery, so nodes flood the data over the
mesh.
parents for
each participant. The emphasis of this primarily push-based system is
on reliability and timely delivery, so nodes flood the data over the
mesh.
In FastReplica [6] file distribution system, the
source of a file divides the file into ![]() blocks, sends a different
block to each of the receivers, and then instructs the receivers to
retrieve the blocks from each other. Since the system treats every
node pair equally, overall performance is determined by the transfer
rate of the slowest end-to-end connection.
blocks, sends a different
block to each of the receivers, and then instructs the receivers to
retrieve the blocks from each other. Since the system treats every
node pair equally, overall performance is determined by the transfer
rate of the slowest end-to-end connection.
BitTorrent [3] is a system in wide use in the Internet for distribution of large files. Incoming nodes rely on the centralized tracker to provide a list of existing system participants and system-wide block distribution for random peering. BitTorrent enforces fairness via a tit-for-tat mechanism based on bandwidth. Our inspection of the BitTorrent code reveals hard coded constants for request strategies and peering strategies, potentially limiting the adaptability of the system to a variety of network conditions relative to our approach. In addition, tracker presents a single point of failure and limits the system scalability.
SplitStream [5] aims to construct an interior-node
disjoint forest of ![]() Scribe [24] trees on top of a
scalable peer-to-peer substrate [23]. The content is
split into
Scribe [24] trees on top of a
scalable peer-to-peer substrate [23]. The content is
split into ![]() stripes, each of which is pushed along one of the
trees. This system takes into account physical inbound and
outbound link bandwidth of a node when determining the number of
stripes a node can forward. It does not, however, consider the overall
end-to-end performance of an overlay path. Therefore, system throughput
might be decreased by congestion that does not occur on the access
links.
stripes, each of which is pushed along one of the
trees. This system takes into account physical inbound and
outbound link bandwidth of a node when determining the number of
stripes a node can forward. It does not, however, consider the overall
end-to-end performance of an overlay path. Therefore, system throughput
might be decreased by congestion that does not occur on the access
links.
In CoopNet [18], the source of the multimedia content computes locally random or node-disjoint forests of trees in a manner similar to SplitStream. The trees are primarily designed for resilience to node departures, with network efficiency as the second goal.
Slurpie [25] improves upon the performance of BitTorrent by using an adaptive downloading mechanism to scale the number of peers a node should have. However, it does not have a way of dynamically changing the number of outstanding blocks on a per-peer basis. In addition, although Slurpie has a random backoff algorithm that prevents too many nodes from going to the source simultaneously, nodes can connect to the webserver and request arbitrary blocks. This would increase the minimum amount of time it takes all blocks to be made available to the Slurpie network, hence leading to increased minimum download time.
Avalanche [8] is a file distribution system that uses network coding [1]. The authors demonstrate the usefulness of producing encoded blocks by all system participants under scenarios when the source departs soon after sending the file once, and on specific network topologies. There are no live evaluation results of the system, but it is likely Avalanche will benefit from the techniques outlined in this paper. For example, Avalanche participants will have to choose a number of sending peers that will fill their incoming pipes. In addition, receivers will have to negotiate carefully the transfers of encoded blocks produced at random to avoid bandwidth waste due to blocks that do not aid in file reconstruction, while keeping the incoming bandwidth high from each peer.
CoDeploy [19] builds upon CoDeeN, an existing HTTP Content
Distribution Network (CDN), to support dissemination of large
files.
In contrast, Bullet![]() operates without infrastructure
support and achieves bandwidth rates (7Mbps on average with a source
limited to 10Mbps) that exceed CoDeploy's published results.
operates without infrastructure
support and achieves bandwidth rates (7Mbps on average with a source
limited to 10Mbps) that exceed CoDeploy's published results.
Young et al. [29] construct an overlay mesh of ![]() edge-disjoint minimum cost spanning trees (MSTs). The algorithm for
distributed construction of trees uses overlay link metric
information such as latency, loss rate, or bandwidth that is
determined by potentially long and bandwidth consuming probing
stage.
The resulting trees might
start resembling a random mesh if the links have
to be excluded in an effort to reduce the probing overhead.
In contrast, Bullet
edge-disjoint minimum cost spanning trees (MSTs). The algorithm for
distributed construction of trees uses overlay link metric
information such as latency, loss rate, or bandwidth that is
determined by potentially long and bandwidth consuming probing
stage.
The resulting trees might
start resembling a random mesh if the links have
to be excluded in an effort to reduce the probing overhead.
In contrast, Bullet![]() builds a content-informed mesh and completely
eliminates the need for probing because it uses transfers of useful
information to adapt to the characteristics of the underlying
network.
builds a content-informed mesh and completely
eliminates the need for probing because it uses transfers of useful
information to adapt to the characteristics of the underlying
network.
We have presented Bullet![]() , a system for distributing large files
across multiple wide-area sites in a wide range dynamic of network
conditions. Through a careful evaluation of design space parameters,
we have designed Bullet
, a system for distributing large files
across multiple wide-area sites in a wide range dynamic of network
conditions. Through a careful evaluation of design space parameters,
we have designed Bullet![]() to keep its incoming pipe full of useful data
with a minimal amount of control overhead from a dynamic set of peers.
In the process, we have defined the important aspects of the general
data dissemination problem and explored several possibilities within
each aspect. Our results validate that each of these tenets of file
distribution is an important consideration in building file
distribution systems. Our experience also shows that strategies which
have tunable parameters might perform well in a certain range of
conditions, but that once outside that range they will break down and
perform worse than if they had been tuned differently. To combat this
problem, Bullet
to keep its incoming pipe full of useful data
with a minimal amount of control overhead from a dynamic set of peers.
In the process, we have defined the important aspects of the general
data dissemination problem and explored several possibilities within
each aspect. Our results validate that each of these tenets of file
distribution is an important consideration in building file
distribution systems. Our experience also shows that strategies which
have tunable parameters might perform well in a certain range of
conditions, but that once outside that range they will break down and
perform worse than if they had been tuned differently. To combat this
problem, Bullet![]() employs adaptive strategies which can adjust over
time to self-tune to conditions which will perform well in a much
wider range of conditions, and indeed in many scenarios of dynamically
changing conditions. Additionally, we have compared Bullet
employs adaptive strategies which can adjust over
time to self-tune to conditions which will perform well in a much
wider range of conditions, and indeed in many scenarios of dynamically
changing conditions. Additionally, we have compared Bullet![]() with
BitTorrent, Bullet and SplitStream. In all cases, Bullet
with
BitTorrent, Bullet and SplitStream. In all cases, Bullet![]() outperforms other systems.
outperforms other systems.
|
This paper was originally published in the
Proceedings of the 2005 USENIX Annual Technical Conference,
April 10–15, 2005, Anaheim, CA, USA Last changed: 2 Mar. 2005 aw |
|