
The distributed node health monitoring system employed by CoDeeN, described in Section 2.2, provides data about the dynamics of the system and insight into the suitability of our choices regarding monitoring. One would expect that if the system is extremely stable and has few status changes, an active monitoring facility may not be very critical and probably just increases overhead. Conversely, if most failures are short, then avoidance is pointless since the health data is too stale to be useful. Also, the rate of status changes can guide the decisions regarding peer group size upper bounds, since larger groups will require more frequent monitoring to maintain tolerable staleness.
Our measurements confirm our earlier hypothesis about the importance
of taking a monitoring and avoidance approach. They show that our
system exhibits fairly dynamic
liveness behavior. Avoiding bad peers is essential and most failure
time is in long failures so avoidance is an effective strategy.
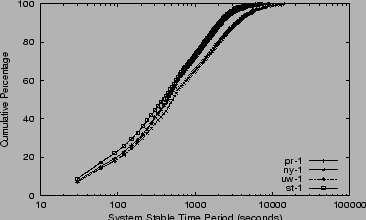
Figure 9 depicts the stability of the CoDeeN
system with 40 proxies from four of our CoDeeN redirectors' local
views. We consider the system to be stable if the status of all 40 nodes
is unchanged between two monitoring intervals. We exclude the cases
where the observer is partitioned and sees no other proxies alive. The
![]() -axis is the stable period length in seconds, and the
-axis is the stable period length in seconds, and the ![]() -axis is
the cumulative percentage of total time. As we can see, these 4
proxies have very similar views. For about 8% of the time, the
liveness status of all proxies changes every 30 seconds (our
measurement interval). In Table 1, we show the 50
-axis is
the cumulative percentage of total time. As we can see, these 4
proxies have very similar views. For about 8% of the time, the
liveness status of all proxies changes every 30 seconds (our
measurement interval). In Table 1, we show the 50![]() and
the 90
and
the 90![]() percentiles of the stable periods. For 50% of time, the liveness
status of the system changes at least once every 6-7 minutes. For 90%
of time, the longest stable period is about 20-30 minutes. It shows
that in general, the system is quite dynamic - more than what one
would expect from few joins/exits.
percentiles of the stable periods. For 50% of time, the liveness
status of the system changes at least once every 6-7 minutes. For 90%
of time, the longest stable period is about 20-30 minutes. It shows
that in general, the system is quite dynamic - more than what one
would expect from few joins/exits.
The tradeoff between peer group size and stability is an open area for
research, and our data suggests, quite naturally, that stability
increases as group size shrinks. The converse, that large groups
become less stable, implies that large-scale peer-to-peer systems will
need to sacrifice latency (via multiple hops) for stability. To measure
the stability of smaller groups, we divide the 40 proxies
into 2 groups of 20 and then 4 groups of 10 and measure
group-wide stability. The results are shown in
Figure 10 and also in Table 1. As we
can see, with smaller groups, the stability improves with longer
stable periods for both the 50![]() and 90
and 90![]() percentiles.
percentiles.
![\begin{figure}
\centering\subfigure[CDF by \char93 of Occurrences]
{\epsfig {fi...
...eps,width=1.5in,height=1.5in,clip=}}
\vspace{-.125in}\vspace{-.15in}\end{figure}](img17.gif) |
The effectiveness of monitoring-based avoidance depends on the node failure duration. To investigate this issue, we calculate node avoidance duration as seen by each node and as seen by the sum of all nodes. The distribution of these values is shown in Figure 11, where ``Individual'' represents the distribution as seen by each node, and ``System-Wide'' counts a node as failed if all nodes see it as failed. By examining the durations of individual failure intervals, shown in Figure 11a, we see that most failures are short, and last less than 100 seconds. Only about 10% of all failures last for 1000 seconds or more. Figure 11b shows the failures in terms of their contribution to the total amount of time spent in failures. Here, we see that these small failures are relatively insignificant - failures less than 100 seconds represent 2% of the total time, and even those less than 1000 seconds are only 30% of the total. These measurements suggest that node monitoring can successfully avoid the most problematic nodes.
![\begin{figure}
\centering\subfigure[Divided into 2 Groups]
{\epsfig {file=figs/l...
...eps,width=1.5in,height=1.5in,clip=}}
\vspace{-.125in}\vspace{-.15in}\end{figure}](img15.gif)