| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Security '04 Paper
[Security '04 Technical Program]
TIED, LibsafePlus: Tools for Runtime Buffer Overflow ProtectionKumar Avijit Prateek Gupta Deepak Gupta Department of Computer Science and Engineering Abstract:
Buffer overflow exploits make use of the treatment of strings in C as
character arrays rather than as
first-class objects. Manipulation of arrays as pointers and primitive
pointer arithmetic make it possible for a program to access memory
locations which it is not supposed to access. There have been many efforts
in the past to overcome this vulnerability by performing array bounds
checking in C. Most of these solutions are either inadequate, inefficient
or incompatible with legacy code. In this paper, we present an efficient
and transparent runtime approach for protection against all known forms of
buffer overflow attacks. Our solution consists of two tools: TIED (Type
Information Extractor and Depositor) and LibsafePlus. TIED extracts size
information of all global and automatic buffers defined in the program from
the debugging information produced by the compiler and inserts it back in
the program binary as a data structure available at runtime. LibsafePlus is
a dynamic library which provides wrapper functions for unsafe C library
functions such as strcpy. These wrapper functions check the source
and target buffer sizes using the information made available by TIED and
perform the requested operation only when it is safe to do so. For
dynamically allocated buffers, the sizes and starting addresses are
recorded at runtime. With our simple design we are able to protect most
applications with a performance overhead of less than 10%.
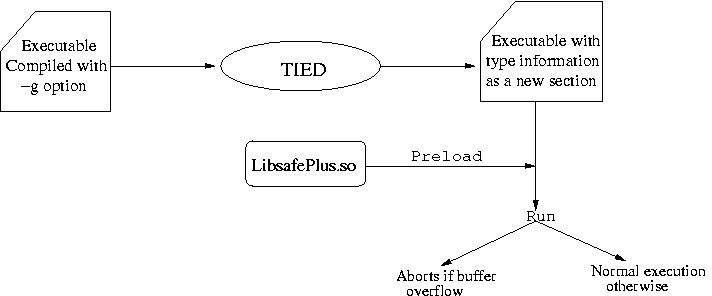
IntroductionBuffer overflows constitute a major threat to the security of computer systems today. A buffer overflow exploit is both common and powerful, and is capable of rendering a computer system totally vulnerable to the attacker. As reported by CERT, 11 out of 20 most widely exploited attacks have been found to be buffer overflow attacks [1]. More than 50% of CERT advisories [2] for the year 2003 reported buffer overflow vulnerabilities. It is thus a major concern of the computing community to provide a practical and efficient solution to the problem of buffer overflows. In a buffer overflow attack, the attacker's aim is to gain access to a system by changing the control flow of a program so that the program executes code that has been carefully crafted by the attacker. The code can be inserted in the address space of the program using any legitimate form of input. The attacker then corrupts a code pointer in the address space by overflowing a buffer and makes it point to the injected code. When the program later dereferences this code pointer, it jumps to the attacker's code. Such buffer overflows occur mainly due to the lack of bounds checking in C library functions and carelessness on the programmer's part. For example, the use of strcpy() in a program without ensuring that the destination buffer is at least as large as the source string is apparently a common practice among many C programmers. Buffer overflow exploits come in various flavours. The simplest and also the most widely exploited form of attack changes the control flow of the program by overflowing some buffer on the stack so that the return address or the saved frame pointer is modified. This is commonly called the ``stack smashing attack'' [3]. Other more complex forms of attacks may not change the return address but attempt to change the program control flow by corrupting some other code pointers (such as function pointers, GOT entries, longjmp buffers, etc.) by overflowing a buffer that may be local, global or dynamically allocated. Many common forms of buffer overflow attacks are described in [4]. Due to the huge amount of legacy C code existing today, which lacks bounds checking, an efficient runtime solution is needed to protect the code from buffer overflows. Other solutions which have developed over the years such as manual/automatic auditing of the code, static analysis of programs, etc., are mostly incomplete as they do not prevent all attacks. A runtime solution is required because certain type of information is not available statically. For example, information about dynamically allocated buffers is available only at runtime. However, most current runtime solutions are unacceptable because they either do not protect against all forms of buffer overflow attacks, break existing code, or impose too high an overhead to be successfully used with common applications. An acceptable solution must tackle all of these problems. In this paper, we present a simple yet robust solution to guard against all known forms of buffer overflow attacks. The solution is a transparent runtime approach to prevent such attacks and consists of two tools: TIED and LibsafePlus. LibsafePlus is a dynamically loadable library and is an extension to Libsafe [5]. LibsafePlus contains wrapper functions for unsafe C library functions such as strcpy. A wrapper function determines the source and target buffer sizes and performs the required operation only if it would not result in an overflow. To enable runtime size checking we need to have additional type information about all buffers in the program. This is done by compiling the target program with the -g debugging option. TIED (Type Information Extractor and Depositor) is a tool that extracts the debugging information from a program binary and then augments the binary with an additional data structure containing the size information for all buffers in the program. This information is utilized by LibsafePlus to range check buffers at runtime. For keeping track of the sizes of dynamically allocated buffers, LibsafePlus intercepts calls to the malloc family of functions. Our tools thus neither require access to the source code (if it was compiled with the -g option) nor any modifications to the compiler, and are completely compatible with legacy C code. The tools have been found to be effective against all forms of attacks and impose a low runtime performance overhead of less than 10% for most applications. The rest of the paper is organized as follows. We present an overview of our approach in Section 2. Section 3 describes the implementation of TIED and LibsafePlus. This is followed by a description of performance experiments and results, in Section 4. Section 5 briefly discusses the related work done in the area of buffer overflow protection. Section 6 concludes the paper.
|
struct my_struct1{
char a[10];
void *b;
char c[10];
};
struct my_struct2{
void *a;
char b[16];
};
union my_union{
struct my_struct1 s1;
struct my_struct2 s2;
} x;
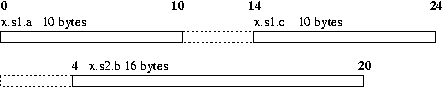 |
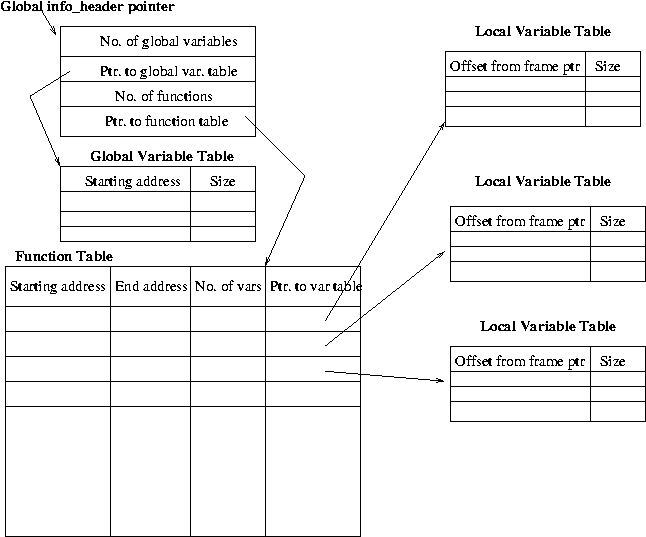
The type information available at runtime is organized in the form of several tables that are linked with each other through pointers, as shown in Figure 4. The top level structure is a type information header that contains pointers to, and sizes of a global variable table, and a function table. The global variable table contains the starting addresses and sizes of all global buffers. The function table contains an entry for each function that has one or more character buffers as local variables or arguments.1 Each entry in the function table contains the starting and ending code addresses for the function, and the size of and a pointer to the local variable table for the function. The local variable table for a function contains sizes and offsets from the frame pointer for each local variable of the function or argument to the function that is a character array. The global variable table, the function table, and the local variable tables are all sorted on the addresses or offsets to facilitate fast lookup.
After constructing these tables in its own address space, TIED finds a suitable virtual address in the target executable for dumping these data structures. The data structure is then ``serialized'' to a byte array, and the pointers are relocated according to the address at which the data structure will be placed in the target binary.
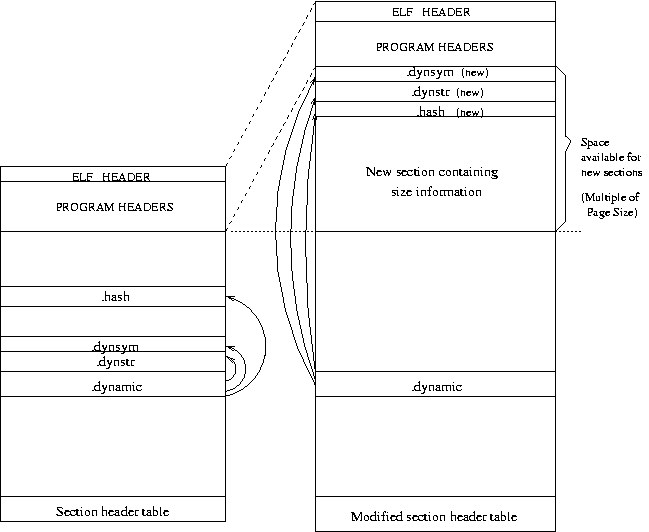
To ensure that addresses of existing code and data elements in the target binary do not change, the target binary is extended towards lower addresses by a size that is large enough to hold the type information data structures and is a multiple of the page size. The new data structure is dumped in this space. A pointer to the new section is made available as the value of a special symbol in the dynamic symbol table of the binary. Since this requires changes to the .dynstr, .dynsym, and .hash sections, and these sections cannot be enlarged without changing addresses of existing objects, TIED places the extended versions of these sections in the new space created, and changes their addresses in the existing .dynamic section. Figure 5 illustrates the changes made to the target binary.
char *buf = (char *)calloc( 5, 10 ); strcpy(buf, "A long string");
A red-black tree [9] is used to maintain the size information about dynamically allocated buffers. The tree contains a node for each buffer allocated using malloc, calloc or realloc. On freeing a memory area using free, the corresponding node is removed. Memory allocation for nodes in the red-black tree is done by a fast, custom memory allocator that directly uses mmap to allocate memory.
To determine the size of the destination buffer, it is first checked whether the destination buffer is on the stack, simply by checking if its address is greater than the current stack pointer. If found on stack, the stack frame encapsulating the buffer is found by tracing the frame pointers. The function corresponding to the stack frame is searched in the function table present in the new section, using the return address from the stack frame above. Finally, the size of the buffer is found by searching in the local variable table corresponding to the function.
If the buffer is not on stack, it is checked whether it is on the heap by comparing its address with the minimum heap address. The minimum heap address is recorded by the malloc and calloc wrappers and is the address of the chunk allocated by the first call to malloc or calloc. The buffer is assumed to be on the heap if its address is greater than the minimum heap address. In this case, its size is determined by searching in the red-black tree.
Finally, if the buffer is neither on stack, nor on heap, it is searched for in the global variable table. If none of the above checks yields the size of buffer, the intended operation of the wrapper is performed. If the size of destination buffer is available, size of the contents of source buffer is determined. The contents are copied only if destination buffer is large enough to hold all the contents. The program is killed otherwise.
We have tested LibsafePlus for its ability to detect buffer overflows as well as for the overhead incurred by loading LibsafePlus with applications. To test the protection ability of LibsafePlus, we used the test suite developed by Wilander and Kamkar [6]. This test suite implements 20 techniques to overflow a buffer located on stack, .data or .bss sections. The test suite executable was first modified using TIED. TIED detected all the global and local buffers declared in the test suite program. LibsafePlus was then preloaded while running the binary. All tests were successfully terminated by LibsafePlus when an overflow was attempted.
For testing performance overhead incurred due to LibsafePlus, we first measured overhead at a function call level. Next, the overall performance of 12 representative applications was measured. In the following subsections, we describe these tests and their results.
We present here the performance results for two most commonly used string
handling functions: memcpy and strcpy. To measure the overhead
of finding sizes of global and local buffers using the new section in the
executable, we performed the following experiment. The test program
contained 100 global buffers and 100 functions. Each function had 3 local
buffers. The time required by a single memcpy() into global and local
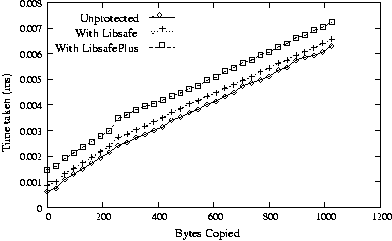
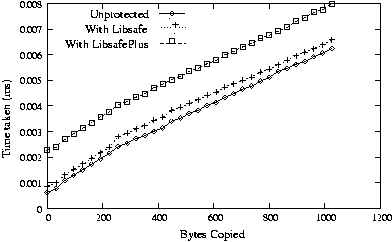
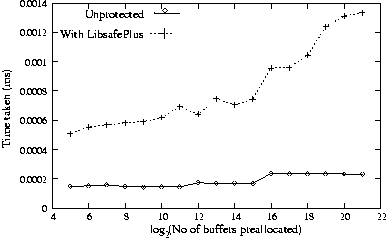
buffers was measured for varying number of bytes copied. As shown in Figure
6, we found a constant overhead of 0.8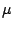 s for memcpy()
to global buffers. This translates to a 100% overhead for memcpy()
upto 64 bytes and decreases to a 12% overhead for memcpy()
involving about 1024 bytes. For local buffers, the overhead due to
LibsafePlus is 2.2s per call to memcpy() as shown in
Figure 7. This includes the 0.9s overhead due to
Libsafe for locating the stack frame corresponding to the buffer.
s for memcpy()
to global buffers. This translates to a 100% overhead for memcpy()
upto 64 bytes and decreases to a 12% overhead for memcpy()
involving about 1024 bytes. For local buffers, the overhead due to
LibsafePlus is 2.2s per call to memcpy() as shown in
Figure 7. This includes the 0.9s overhead due to
Libsafe for locating the stack frame corresponding to the buffer.
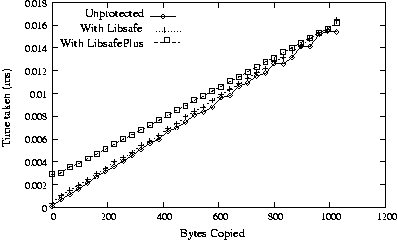
To measure the overhead of finding size of a heap variable from the
red-black tree, the test program first allocated 1000 heap buffers. It then
allocated another heap buffer and measured the time taken by one memcpy()
to it. This represents the worst case performance as the buffer
being copied to is the right most child in the red-black tree. As shown in
Figure 8, the overhead due to LibsafePlus is 1.6s per
call to memcpy().
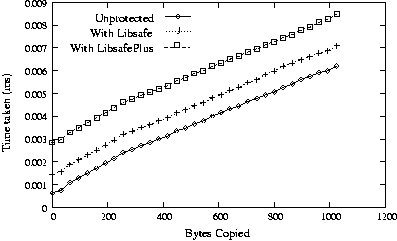
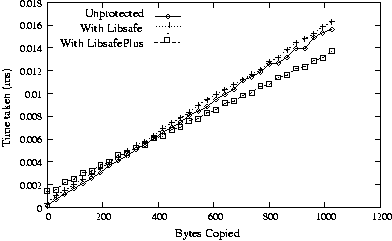
We also measured the performance of LibsafePlus for calls to strcpy(). The testbed was similar to the one described earlier for memcpy(). Figure 9 shows the time taken by one strcpy() to a global buffer. The overhead drops from 0.8s for buffers
of size 1 byte to 0 for buffers of about 400 bytes. This is because the
wrapper function for strcpy() in LibsafePlus uses memcpy() for
copying, which is 6 to 8 times faster than strcpy() for large buffer
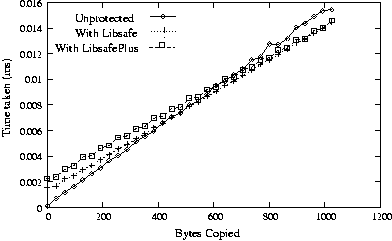
sizes. Figures 10 and 11 show similar
results for strcpy() to local and heap buffers respectively.
Next, we measured the overhead due to LibsafePlus in dynamic memory
allocation. The insertion and deletion of nodes in the red-black tree is
the primary constituent of this overhead. We measured the time required by
a pair of malloc() and free() calls. The number of buffers
already present in the red-black tree at the time of allocating the buffer
was varied from 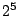 to
to 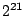 . As shown in Figure 12, the
time taken by LibsafePlus for malloc(), free() pair grows
almost logarithmically with the number of buffers already present in the
red-black tree. This is expected because of the
. As shown in Figure 12, the
time taken by LibsafePlus for malloc(), free() pair grows
almost logarithmically with the number of buffers already present in the
red-black tree. This is expected because of the  time
operations of insertion and deletion of nodes in a red-black tree.
time
operations of insertion and deletion of nodes in a red-black tree.
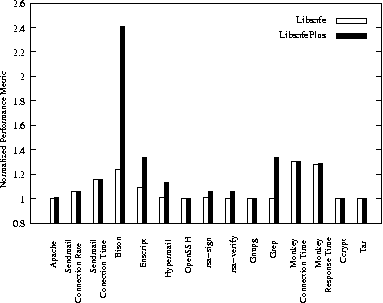
Next, we measured the performance overhead due to LibsafePlus using a number of applications that involve substantial dynamic memory allocation and operations like strcpy() to buffers. In all, a total of 12 applications were used to evaluate the overhead of LibsafePlus and Libsafe. Table 1 describes the performance metric used in each case. The performance overheads are shown in Figure 13. The graph shows normalized metric values with respect to the case when no library was preloaded. The overhead due to LibsafePlus was found to be less than 34% for all cases except for Bison. In 8 out of 12 applications, the overhead of LibsafePlus was within 5% of that of Libsafe. In case of Enscript, Grep and Bison, the slowdown observed is due to a huge number of dynamic memory allocations and string operations on heap buffers.
We now present a comparison of performance overhead of our tool with that of CRED [10] (strings only mode). As shown in Table 2, for 9 out of the 11 applications which have been used to measure the performance overhead of both the tools, LibsafePlus performs better than CRED. The slowdown observed for CRED, as compared to LibsafePlus, is significant for Apache, Enscript, Hypermail, Gnupg and Monkey.
In this section, we review the related work in the area of protection against buffer overflow attacks.
PaX [13] is another kernel patch which aims to protect the heap as well as the stack. The idea behind PaX is to mark the data pages non-executable by overloading supervisor/user bit on pages and enabling the page fault handler to distinguish the page faults due to attempts to execute data pages. PaX also imposes a significant performance overhead due to additional work done by the page fault handler for each page fault. Although protecting the heap offers some additional protection but still it does not guarantee complete protection from all forms of attacks. For example, return-into-libc attacks are still possible.
Wagner et al. formulated the detection of buffer overruns as an integer range analysis problem [14]. The approach models C strings as a pair of integer ranges (allocated size and length) and vulnerable C library functions are modeled in terms of their operations on the integer ranges. Thus, the problem reduces to an integer range tracking problem. The described tool checks, for each string buffer, whether its inferred length is at least as large as the allocated length. The tool is impractical to use since it produces a large number of false positives, due to lack of precision, as well as some false negatives.
The annotation based static code checker based on LCLint [15] by Larochelle and Evans [16] exploits the information provided in programs in the form of semantic comments. The approach extends the LCLint static checker by introducing new annotations which allow the declaration of a set of preconditions and postconditions for functions. The tool does not detect all buffer overflow vulnerabilities and often generates spurious warnings.
CSSV [17] is another tool for statically detecting string manipulation errors. The tool handles large programs by analyzing each procedure separately and requires procedure contracts to be defined by the programmer. A procedure contract defines a set of preconditions, postconditions and side-effects of the procedure. The tool is impractical to use for existing large programs since it requires the declaration of procedure contracts by the programmer. As for other static techniques, the tool can produce false alarms.
StackGuard [18] is an extension to the GNU C compiler that protects against stack smashing attacks. StackGuard enhances the code produced by the compiler so that it detects changes to the return address by placing a canary word on the stack above the return address and checking the value of the canary before the function returns. The canary is a sequence of bytes which could be fixed or random. The approach assumes that the return address is unaltered if and only if the canary word is unaltered. StackGuard imposes a significant runtime overhead and requires access to the source code. Techniques to bypass StackGuard protection are described by Richarte [19].
StackShield [20] is also implemented as a compiler extension that protects the return address. The basic idea here is to save return addresses in an alternate non-overflowable memory space. The resulting effect is that return addresses on the stack are not used, instead the saved return addresses are used to return from functions. As with StackGuard, the source code needs to be recompiled for protection. A detailed description of StackShield protection and techniques to bypass it were presented by Richarte [19].
Propolice [21] is another compiler extension which modifies the syntax tree or intermediate language code for the protected program. SSP (Propolice) aims to protect the saved frame pointer and the return address by placing a random canary on the stack above the saved frame pointer. In addition, SSP protects local variables and function arguments by creating a local copy of arguments and rearranging the local variables on the stack so that all local buffers are stored at a higher address than local variables and pointers. As for StackGuard and StackShield, it requires the recompilation of the source code. Although SSP protects against stack smashing attacks, it is vulnerable to other forms of attacks.
The memory access error detection technique by Austin et al. [22] extends the notion of pointers in C to hold additional attributes such as the location, size and scope of the pointer. This extended pointer representation is called the safe pointer representation. The additional attributes are used to perform range access checking when dereferencing a pointer or while doing pointer arithmetic. The approach fails to work with legacy C code as it changes the underlying pointer representation.
The backwards compatible bounds checking technique by Jones and Kelly [23] is a compiler extension that employs the notion of referent objects. The referent object for a pointer is the object to which it points. The approach works by maintaining a global table of all referent objects which maintains information about their size, location, etc. Furthermore, a separate data structure is maintained for heap buffers by modifying malloc() and free() functions. Range checking is done at the time of dereferencing a pointer or while performing pointer arithmetic. The technique breaks existing code and involves a high performance overhead for applications which are pointer and array intensive since every pointer or array access has to be checked at runtime.
The C Range Error Detector(CRED) [10] is an extension of Jones and Kelly's approach. CRED extends the idea of referent objects and allows the use of a previously stored out-of-bounds address to compute an in-bounds address. This is done by storing all the information about out-of-bounds addresses in an additional data structure on the heap. The approach fails if an out-of-bounds address is passed to an external library or if an out-of-bounds address is cast to an integer and subsequently cast back to a pointer. As for Jones and Kelly's technique, the tool involves a high performance overhead for pointer/array intensive programs since every access to a pointer has to be checked.
The type assisted dynamic array bounds checking technique by Lhee and Chapin [24] is also a compiler extension that works by augmenting the executable with additional information consisting of the address, size and type of local buffers, pointers passed as parameters to functions and static buffers. An additional data structure is maintained for heap buffers. Range checking is actually performed by modified C library functions which utilize this information to guarantee that overflows do not occur. As for other compiler based techniques, the solution is not portable and requires access to the source code of the program. It can be seen that our approach is very similar to Lhee and Chapin's approach. However, the main advantage of our approach is that it does not require compiler modifications and can work with the output of any compiler that can produce debugging information in the DWARF format.
PointGuard [25] is a pointer protection technique that encrypts pointers when they are stored in memory and decrypts them when they are loaded into CPU registers. PointGuard is implemented as a compiler extension that modifies the intermediate syntax tree to introduce code for encryption and decryption. Encryption provides for confidentiality only, hence PointGuard gives no integrity guarantees. Although, PointGuard imposes an almost zero performance overhead for most applications, it protects only code pointers (function pointers and longjmp buffers) and data pointers and offers no protection for other program objects. Also, protection of mixed-mode code using PointGuard requires programmer intervention.
One of the major drawbacks of all existing runtime techniques is that they require changes to the compiler. None of these techniques seem to have been adopted by any of the mainstream compilers so far. In contrast, our approach does not require any compiler modifications and can be used with any existing compiler. We feel that this may lead to widespread adoption of this technique in practice.
There are certain cases which our approach is unable to handle. LibsafePlus can only guard against buffer overflows due to injudicious use of unsafe C library functions and not those due to other kinds of errors in the program itself. However, in most programs buffer overflows occur due to improper use of C library functions rather than erroneous pointer arithmetic done by the programmer. Moreover, guarding against erroneous pointer arithmetic implies protecting every pointer instruction which would incur a high performance overhead (as in CRED).
Also, LibsafePlus cannot handle dynamic memory allocated using alloca. Alloca is used to dynamically create space in the current stack frame, and the space is automatically freed when the function returns. The difficulty in handling alloca in LibsafePlus is that while memory allocation can be tracked by intercepting calls to alloca, it is not possible to track when a buffer is freed, since the freeing happens automatically when the function that called alloca returns. Variable sized automatic arrays (supported by gcc) present a similar problem.
Since LibsafePlus uses mmap for allocating nodes for the red-black tree, programs that use mmap for requesting memory at specified virtual addresses may not work with LibsafePlus.
A limitation of the current implementation is that size information for local and global buffers declared within dynamically loaded libraries is not available at runtime. We are currently extending LibsafePlus and TIED to address this issue.
TIED and LibsafePlus are available in the public domain and can be downloaded from https://www.security.iitk.ac.in/projects/Tied-Libsafeplus.
|
This paper was originally published in the
Proceedings of the 13th USENIX Security Symposium,
August 9–13, 2004 San Diego, CA Last changed: 23 Nov. 2004 aw |
|
![\begin{figure}\begin{verbatim}struct s{
char a[10];
char b[5];
};
struct s foo[20];\end{verbatim}
\end{figure}](img1.png)