This section defines Scout's security architecture. It begins with an overview of Scout, and then describes how we have extended Scout to support both fine-grain accounting and protection domains. It concludes with a brief discussion of how the resulting system---which we call Escort---facilitates the enforcement of different security policies.
Modules are the unit of program development and configurability in Scout. Each Scout module provides a well-defined and independent function. Well-defined means that there is usually either a standard interface specification, or some existing practice that defines the exact function of a module. Independent means that each single module provides a useful, self-contained service. That is, the module should not depend on there being other specific modules connected to it. Typical examples are modules that implement networking protocols, such as HTTP, IP, UDP, or TCP; modules that implement storage system components, such as VFS, UFS, or SCSI; and modules that implement drivers for the various device types in the system.
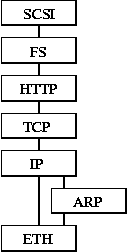
To form a complete system, individual modules are connected into a module graph: the nodes of the graph correspond to the modules included in the system, and the edges denote the dependencies between these modules. Two modules can be connected by an edge if they support a common service interface. These interfaces are typed and enforced by Scout. By configuring Scout with different collections of modules, we can configure kernels for different purposes, including network-attached devices, web and file servers, firewalls and routers, and multimedia displays. For example, Figure 1 shows an extract of the module graph for a Scout kernel that implements a web server. The configuration includes device drivers for the network and disk devices (ETH and SCSI), four conventional network protocols (ARP, IP, TCP and HTTP), and a simple file system (FS). Such a configuration is specified at build time, and a set of configuration tools assemble the corresponding modules into an executable kernel.
Scout adds a communication-oriented abstraction---the path---to the configurable system just described. Intuitively, a path can be viewed as a logical channel through a modular system over which I/O data flows. In other words, the path abstraction defines a channel over which data moves through the system, for example, from input device to output device. Each path is an object that encapsulates two important elements: (1) it defines the sequence of code modules that are applied to the data as it moves through the system, and (2) it represents the entity that is scheduled for execution.

Although the module graph is defined at system build time, paths are created and destroyed at run time as I/O connections are opened and closed. Figure 2 schematically depicts a path that traverses the module graph shown in Figure 1; it has source queues and sink queues, and is labeled with the sequence of software modules that define how the path ``transforms'' the data it carries. This particular path processes incoming HTTP requests by fetching web pages from disk.
The path-specific local state of each module is stored in a data structure called a stage. Stages from a sequence of modules are combined to form the path. In addition to this path-specific state, when executing code within a certain module, paths also have access to the state of the module. For example, a path executing code of the IP module has access to the routing tables stored in the IP module.
Each path goes through three phases during its lifetime. The first phase is path creation, during which the topology of the path---i.e., the sequence of modules it traverses---is determined, and the state of the path is initialized. Path creation is triggered by a pathCreate call to the kernel; the kernel limits path creation according to an access control list (ACL) specified by the system designer.
Specifically, the pathCreate operation takes six arguments: a set of attributes, the starting module, a subject, a subject class, the calling protection domain, and the calling owner. The first four arguments are explicitly given, while the last two are implicitly known from the calling thread. The attribute set defines invariants for the path, such as the port number and IP address for the peer. The kernel uses these invariants, plus the starting module, to determine the path's topology---the sequence of modules that the path traverses. Because only a certain small number of path topologies are useful in a given configuration, it is accurate to think of this process as determining the path's type (e.g., an ``HTTP path''). Next, the kernel consults the ACL to determine if the entity trying to create the path is allowed to create a path of this type, and if so, what resource limits might be imposed on it. The entity creating the path is identified by the last four arguments to pathCreate: the subject (think of this as a user or a role), a subject class (this defines the availability level [16]), the calling protection domain (see Section 2.3), and the calling owner (see Section 2.4). At this point, the path exists and its resource limits are known.
Then the path enters its second phase, during which data is sent and received over it. Both send and receive work in the obvious way: data is enqueued at one end of the path and a thread is scheduled to execute the path. There is one complication, however. When data arrives on a device---e.g., a network packet arrives on the Ethernet---the kernel must determine to which path it belongs. This is done in a way that is analogous to path creation: the kernel identifies the path incrementally by invoking a demux operation on a sequence of modules. Each module's demux function has three choices: (1) it can determine that a unique path has not yet been identified and call the demux function of some adjacent module; (2) it can reject the request and drop the data; or (3) it can return a unique path. The demux function is side-effect free.
The last phase of a path is invoked by a pathDestroy or pathKill call to the kernel. In case of pathDestroy the kernel invokes a destroy function associated with each module along the path in the same order in which they were initialized before it frees all resources used by the path. pathKill frees all the path's resources, but does not invoke the destroy functions.
Escort extends the basic Scout architecture by isolating the modules that have been configured into the system into separate protection domains. The kernel---which implements the path operations described above, as well as other objects described in the next section---runs in a privileged protection domain. The protection domain that each module is to run in is specified at configuration time. Trusted modules can be placed in the privileged domain. Modules can also be multiply instantiated, both across different protection domains, and in the same protection domain.
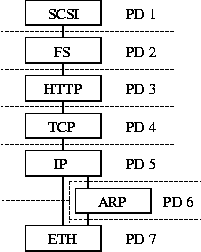
Figure 3 shows the module graph for our example web server partitioned into separate protection domains; one module per domain in this example. (The device drivers also have access to the memory regions used to access their devices.) This configuration represents the maximum possible separation. A less restrictive configuration might, for example, combine TCP, IP and ARP within one protection domain.
In addition to the kernel and the set of modules configured into the system, Escort also supports libraries that implement commonly used functions. Library code is trusted by their users, and so is mapped executable into all protection domains. Escort currently supplies libraries to manage messages, hash tables, participant addresses, attributes, queues, heaps, and time. It also includes a standard C library.
The current version of Escort runs in a single 64-bit address space and implements protection domains using hardware mechanisms available on the Alpha microprocessor. Modules not linked into the privileged domain invoke kernel services using a hardware trap. However, software fault isolation [24], type safe languages like Java, and proof carrying code [15] could be used instead.
Since the code for each module and library might be used by multiple protection domains, the calling environment for a given invocation of a library or module function must be specified. Furthermore, since modules can also be multiply instantiated within one protection domain, it is not sufficient to have one data segment per protection domain. Therefore, Escort explicitly passes the calling environment as the first argument to any procedure, optimizing for stateless libraries and libraries that access only protection domain state. This is similar to the approach described in [19].
Each module supports a well-known initialization function. When an Escort system boots, the kernel initializes every module by switching to the appropriate protection domain and calling the init function on each module in that domain. The modules initialize their global state and create an initial set of paths.
Finally, we return to the issue of demultiplexing incoming network packets, but this time in light of multiple protection domains. The base demux mechanism in Scout trusts the demux functions contributed by each module. Although not yet implemented in Escort, alternative mechanisms---e.g., pattern-based demultiplexers like PathFinder [3] and the current system augmented with Proof Carrying Code [15]---would be more appropriate since they do not trust the demultiplexing code to be correct and to not leak information via the demultiplexing decision.
A key goal of Escort is to account for all resource usage. Towards this end, all resources are charged to an owner, which can be either a path or a protection domain. Paths are the preferred choice since they most naturally correspond to the actual user of the resources. However, there are certain resources that cannot be accounted to a particular path. For example, an IP routing table cannot be directly associated with (charged to) any individual IP flow; the memory used by the routing table is associated with the protection domain that runs the IP module.
There are only a few differences between protection domains and paths in terms of ownership. One is that protection domains have a heap and paths do not. The reason for this is that the kernel allows memory allocation at the page level only. For paths this is extremely inefficient since it would require a path to allocate at least one page for each protection domain it crosses. To keep the accounting mechanism accurate, the protection domain can charge paths that cross it with memory usage. The memory charged toward a path is then deducted from the memory charged to the protection domain. In other words, the kernel gives memory pages to protection domains, which in turn implement a heap and hand out smaller memory objects to paths that traverse them.
To allow the automatic reclamation of this memory---and other resources like the reservation of a TCP port---all modules can register destructor functions with a path. This function is called in the module's protection domain when a path is destroyed or killed, and results in charge for the memory being transfered back to the protection domain. The destructor function usually frees all memory charged toward the path. However, the domain is ultimately responsible for the freeing of the memory, that is, returning the page back to the kernel.
Another difference is that paths can be destroyed without destroying the modules or protection domains they cross. However, if a protection domain is destroyed, all paths crossing that protection domain are also destroyed. This is necessary since paths can access the global state of all modules they cross and this state will be removed if the protection domain is destroyed. For example after destroying the protection domain containing the IP module, IP's routing table will no longer be accessible by paths anymore.
struct Owner {
OwnerType type; /* PATH or PD */
/* Accounting */
u_long kmem;
u_long pages;
u_long IoBuffer,
u_long threads;
u_long stacks;
u_long cycle;
u_long events;
u_long semaphores;
/* Tracking */
PageList pages;
ThreadList threads;
IoBufferLockList iobufferlock;
EventList event;
SemaphoreList semaphore;
/* Scheduling */
Scheduler scheduler;
/* Resource Monitoring */
Resource limits;
};
Figure 4 shows the Owner data structure; this structure is the first element of both the path and protection domain data structures. The Owner structure is divided into three parts. The first part keeps a count of the resources---kernel memory, memory pages, IOBuffer, threads, stacks, CPU cycles, events, and semaphores---used by this owner. The fields in this part are used to decide if the resource part of the security policy has been violated. Note that the kmem field counts the amount of memory used to store the kernel objects referenced in the second part of the data structure.
The second part contains doubly linked lists of the actual kernel objects associated with this owner; these objects are described in Section 3. These lists support the fast removal of the corresponding objects in event that the owner must be destroyed. The Scheduler object contains the information necessary to schedule threads belonging to this owner. The exact contents of this data structure depends on the scheduler used. The last part contains the resource limits of the owner. This object is more fully described in Section 2.5.
Whenever a new resource is requested, the owner is explicitly passed as an argument to the kernel allocator. Although not mandated by the architecture, many policies require that this argument must match the owner of the current thread.
Owners are charged for resources they use, with any limits placed on this usage specified at system configuration time (for protection domains), and at path creation time (for paths). The resource limits for a particular owner are given by the Resource object of the Owner data structure. The action to be taken when a given limit is exceeded is specified in the Limit object; possible actions include destroying the path, denying the request, or preventing further demultiplexing of incoming data to the path. Figure 5 shows both the Resource and Limit data structures.
struct Limit {
int val;
Action action
};
struct Resource {
Id subject;
Id subject_class;
Limit kmem;
Limit pages;
Limit IoBuffer;
Limit threads;
Limit stacks;
Limit cycle;
Limit events;
Limit semaphores;
Limit yield;
Limit attribute[attr_count];
};
The Resource object defines limits for the very same resources as accounted for in the Owner object: kernel memory, pages, IOBuffers, threads, stacks, cycle, events, semaphores and attributes. In addition, the yield field limits the maximum number of cycles a thread can run without yielding the processor, attr_count is a system constant limiting the number of attributes which can be associated with a path and the attribute field limits the values of those attributes. The Resource object also contains identifiers for subjects, which correspond to users or roles and subject classes which represent availability levels in multi level availability systems. These identifiers are used to aggregate resource usage over multiple paths.
All resource limits, except for the yield and cycle restrictions, are enforced by a resource monitor. This monitor is called whenever resources are allocated or freed, or when attributes change. The resource monitor is also responsible for monitoring aggregated resource utilization for subjects and subject classes according to a given policy. To support multiple policies, Escort allows the appliance designer to configure different resource monitors into the system. Currently, Escort uses a simple resource monitor that compares the resources used against the stated limit, and performs the appropriate action when the limit is exceeded. It does not support aggregation of resources.
The yield and cycle restrictions are enforced directly by the kernel at clock interrupt time, and if a violation of policy occurs, the only action allowed is to destroy the associated owner.
Although we have been focusing on how Escort accounts for resource usage, it is useful to place Escort's security mechanisms in a larger context. Specifically, Escort allows the system designer to enforce a security policy on four different levels.