
The operating system kernel and class libraries run on the ParaDiGM architecture [8]. The basic configuration consists of 4-processor Motorola 68040-based multiprocessors running with 25 MHz clocks. The 68040 processor has a DCAS instruction, namely CAS2. This software also runs with no change except for a software implementation of DCAS, on a uniprocessor 66 MHz PowerPC 603. We have not implemented it on a multiprocessor PowerPC-based system to date.
Kernel synchronization uses DCAS in 27% of the critical sections and otherwise CAS. However, the DCAS uses are performance-critical, e.g. insert and deletion for key queues such as the ready queue and delay queue. The only case of blocking synchronization is on machine startup, to allow Processor 0 to complete initialization before the other processors start execution.
The overhead for non-blocking synchronization is minimal in extra instructions. For example, deletion from a priority queue imposes a synchronization overhead of 4 instructions compared to no synchronization whatsoever, including instructions to access the version number, test for DCAS success and retry the operation if necessary. This instruction overhead is comparable to that required for locked synchronization, given that lock access can fail thus requiring test for success and retry.
The Motorola 68040's CAS2 [26] is slow,
apparently because of inefficient handling of the on-chip cache
so synchronization takes about 3.5 microseconds in processor time.
In comparison, spin locks take on average 2.1 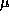 secs
and queuelocks take about 3.4
secs
and queuelocks take about 3.4 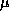 secs.
In contrast,
the extended instructions we propose in Section 6
would provide performance comparable to any locking implementation.
In particular, it requires 16 extra instructions
(including the required no-ops) plus an implicit SYNC
in an R4000-like processor.
A careful implementation would allow all instructions
other than the SYNC to execute at normal memory speed.
The performance would then be comparable to
the roughly 24 instruction times
required by the R4000 lock/unlock sequence.
Figure 4 compares the overhead
in terms of instruction times.
secs.
In contrast,
the extended instructions we propose in Section 6
would provide performance comparable to any locking implementation.
In particular, it requires 16 extra instructions
(including the required no-ops) plus an implicit SYNC
in an R4000-like processor.
A careful implementation would allow all instructions
other than the SYNC to execute at normal memory speed.
The performance would then be comparable to
the roughly 24 instruction times
required by the R4000 lock/unlock sequence.
Figure 4 compares the overhead
in terms of instruction times.
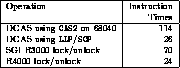
Figure 4: Approximate instruction times of extra overhead to
synchronize deletion from a priority queue.
This overhead does not include the backoff computation.