
There are some apparent and also some less apparent advantages to doing race detection on the Java bytecodes instead of on the underlying hardware instructions.
First of all, we have the granularity argument. Since Java bytecodes are quite high level, many machine instructions can be necessary to perform one bytecode instruction. If we try to detect data races at the machine level, we will have to observe every hardware read/write instruction for every thread. If however we observe at the bytecode level, many machine instructions can safely be ignored, assuming a correct JVM.
Secondly, Java, by construction, makes a large number of instructions data race free. Every thread has its own private stack on which it allocates local variables and parameters for each member function call. This data can only be modified by the owning thread. As a consequence, all instructions that solely manipulate stack data cannot cause a data race. There are 181 guaranteed data race free instructions and 20 `dangerous' instructions. The latter set can be split into 2 categories. The first category consist of the {a,b,c,d,f,i,l,s}aload and {a,b,c,d,f,i,l,s}astore bytecodes. These instructions read and write the contents of arrays on the heap. Since objects on the heap can be reached from multiple threads, these instructions need to be checked for data races. The second category consists of getfield, getstatic, putfield and putstatic. These are instructions that read or write the fields of objects or classes on the heap.
Finally, and this will prove essential to our technique, Java enforces a very strict object model, even on the bytecode level. Machine instructions can modify practically any location in the address space of a program. Java, on the other hand, only allows modification of an object's data through the reference to that object.
As can be seen in Figure 5, an object is created by invoking the bytecodes new, newarray, anewarray or multianewarray (1 in the figure). These instructions all put a reference to the newly allocated object on the stack of the invoking thread. At this point, these objects are only reachable through this one reference and this reference is only accessible to one thread. We call this situation a `local object'. No races are possible. An object that is reachable, through some path, by several threads, is called a `global object'. It has the potential to be involved in a race. Since we construct information about the reachability of objects from several threads in order to detect potential race problems, we call this method `topological race detection', TRaDe for short.
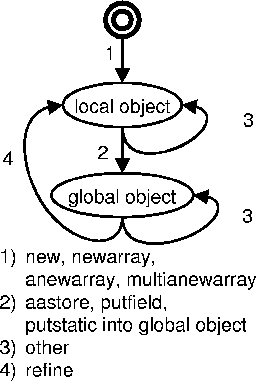
Figure 5: The life cycle of an object
Initially an object is created locally. The only references to it exist on its creating thread's stack (1 in Figure 5). One way to change the status of an object from local to global is by storing its reference into a second object. If this second object is reachable by another thread, our object also becomes reachable by this other thread (2 in Figure 5). At this point, the object could potentially be involved in a race. When an object becomes global all the objects reachable from this new global object also become global. If, on the other hand, the second object is solely reachable by our own thread, it remains local.
There are only a small number of bytecodes that can change the topology of the object interconnection graph: aastore, putfield and putstatic. They all have in common that they store references in an object's field.
There are a few exceptions to the outline given above. Every object of type Class is global right from the start. The reason for this is that every thread needs to be able to access every class to construct objects of this class. Inside a class, there are static variables that can be read and written to. So these are, by definition of the Java language, immediately global to all threads.
A second way in which an object can become global is when it is involved in the startup of a new thread. In Java, threads are started by creating an object containing a run method. When this object's start method is called, a new thread is created and starts executing the code in the run method. At this very point, this object is reachable by both the new thread and the original thread that started the new thread. It must therefore immediately be made global together with all objects reachable from this object.
This last observation is crucial and is the reason why a refinement of our global objects is necessary (5 in Figure 5). Consider for example the Java program in Figure 6. It creates 10 separate threads (besides the main thread). Each of these threads creates a linked list of 10000 local objects.![]() No races are present in the program. Note that the main thread does not maintain a link to the started threads (g = null).
No races are present in the program. Note that the main thread does not maintain a link to the started threads (g = null).
This program was artificially made to be very suitable for our approach to race detection; it is very simple and contains large data structures which are clearly not shared between the threads. Almost all calculations are performed on these local data structures so fairly little overhead should be incurred by doing race detection. Still, without the refinement step, TRaDe would perform very badly.
When the new threads are started (at line 29) by invoking start on the object g of the class Separate, g must be made global. If it were not for the refinement, these objects would remain global for the remainder of the program's execution. When the threads would start to construct their linked lists, these linked list would also become global. Not much can be gained from such an approach. To do the refinement step, we turned to the garbage collector (GC).
Whatever the underlying algorithm of the GC is, somehow it must determine whether an object is no longer reachable by any thread in the program. If this is the case, the object can be removed from the heap. This is very similar to what TRaDe is trying to do. TRaDe tries to determine whether an object is reachable by more than one thread in the program.
We exploited this observation as follows. Each time the GC performs its job, it is followed by our `refiner'. For every thread, we generate a set, ![]() , of all the objects that are reachable from that thread. Then we combine these sets into a set of objects reachable from multiple threads as follows.
, of all the objects that are reachable from that thread. Then we combine these sets into a set of objects reachable from multiple threads as follows.
![]()
We use ![]() to refine the general TRaDe mechanism after garbage collection. If an object is not present in
to refine the general TRaDe mechanism after garbage collection. If an object is not present in ![]() , it is only reachable from one thread and therefore local. The large data structures that are necessary to enable data race detection are removed and the object is marked as being reachable only by this one thread.
, it is only reachable from one thread and therefore local. The large data structures that are necessary to enable data race detection are removed and the object is marked as being reachable only by this one thread.
A minor, yet crucial, modification to our refiner proved necessary. A reference to each Thread (and derived classes) is always present in at least one ThreadGroup and every Thread can obtain the ThreadGroup of which it is a member. This has the annoying consequence that every Thread can be reached from every other Thread through its ThreadGroup. If we instruct our refiner to only collect the objects reachable from one thread, it will inevitably start collecting a large portion of the other thread's data structures through these hidden references. The solution was not to follow links leaving ThreadGroup. Should a program use these references in ThreadGroup, it will circumvent our technique. We believe this will occur only rarely. If this is a problem, we could adapt the JVM further so as to flag such behavior.
Figure 7 compares the approach without a refinement phase (top graph) with the approach with a refinement phase (bottom graph). The figures are constructed by analyzing the heap each time a garbage collection has occurred. We see the total number of handles allocated (a handle points to an object). These handles are subdivided into unused handles which are preallocated each time the heap is expanded, local handles which point to objects that are detected as being local to a thread and global handles which point to objects which were detected as being reachable by more than one thread.
The top graph shows that practically all used handles point to global objects. This means that we would have to observe accesses to most objects for potential data races. The number of local objects is so small that they are not noticeable on the graph.
The bottom graph, using the refiner, shows the expected result. We see that almost all used handles point to local objects. The number of global objects is very small. Clearly, the large linked lists are being detected as local so we will not need to observe these to detect data races.
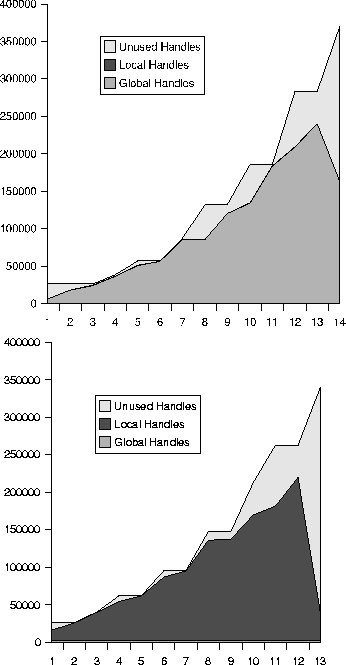
Figure 7: Total number of handles in use measured after each garbage collection phase. The top graph was measured without using the refiner. The bottom graph was measured while using the refiner.
