We present results for the OO1 traversal operations corresponding to
different address translation granularities for the data structures
used during the traversals. In particular, we are interested in three
different address translation granularities, namely coarse-grained, mixed-granularity and fine-grained
strategies. The following table describes the types of pointers used
for each granularity and the corresponding key in the results.
| Granularity | Type(s) of pointers | Key |
| coarse | all language-supported | all-raw |
| mixed | smart for index | smart-index |
| fine | all smart | all-smart |
We use CPU time20 instead of absolute real time because the difference in performance is primarily due to differences in faulting and swizzling, and allocating address space for reserved pages. Unfortunately, CPU-time timers on most operating systems have a coarse granularity (typically in several milliseconds), and it would be impossible to measure any reasonable differences in the performance due to a change in the address translation granularity because our overheads are very small. Thus, we use an older SPARCstation ELC, which is slow enough to offset the coarse granularity of the timers, while providing reasonable results.
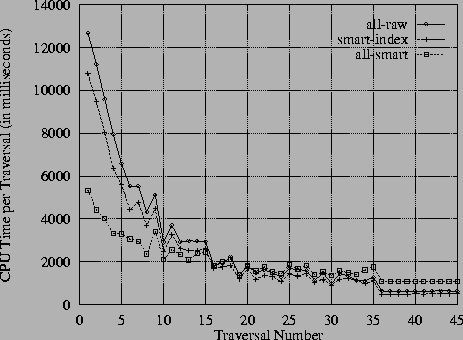
Figure 3 presents the CPU time for all traversals in an entire traversal set run on a large database. As expected, the cost for ``all-raw'' case (coarse-grained address translation) is the highest for the first 15 or so traversals. This is not unusual because the coarse-grained address translation scheme swizzles all pointers in the faulted-on pages and reserves many pages that may never be used by the application. This is exacerbated by the poor locality of reference in the benchmark traversals as many pages of the database are accessed during the initial traversals, causing a large number of pages to be reserved. The number of new pages swizzled decreases as the cache warms up, and we see the corresponding reduction in the CPU time.
Note that the cost for the ``all-smart'' case (fine-grained address translation) is the lowest for the first 15 traversals. Again, this is expected because the address translation scheme does not swizzle any pointers in a page when it is faulted in because they are all smart pointers that must be translated at every use. Finally, the CPU time for the ``smart-index'' case (mixed-granularity address translation) falls between the other two cases for the first 15 traversals. This is also reasonable because only the index structure contains smart pointers, and each traversal uses this index only once (to select the root part for the traversal). This cost is only slightly less than the ``all-raw'' case because our B+ tree implementation generated a tree that was only three levels deep, reducing the number of smart pointers that had to be translated for each traversal.
Now consider the hot traversals (36 through 45). The first thing to note is that the CPU time for the ``all-smart'' case is higher than that for the other two cases. This is because smart pointers impose a continual overhead for each pointer dereference, and this cost is incurred even if the target object is resident. In contrast, the ``all-raw'' case has zero overhead for hot traversals.21
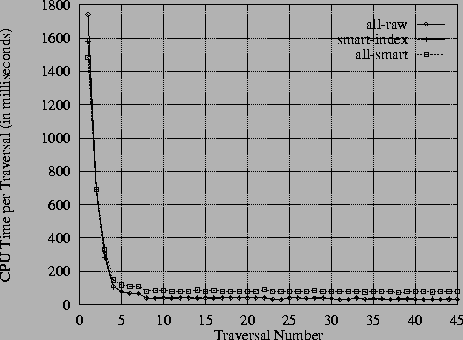
Figure 4 shows the corresponding results for the small database, where only the first 3 or 4 traversals contain faulting and swizzling.22 Once again, a phenomenon similar to the one in large database results can be seen in the current results, but only for the initial traversals. In particular, the CPU time is highest for the ``all-raw'' case and lowest for the ``all-smart'' case. Also as before, the two granularities swap their positions for the hot traversals; the ``all-smart'' case is more expensive because of the continual translation overhead at every use. Finally, as expected, the ``all-raw'' and ``smart-index'' results are identical for hot traversals because no index pointers are dereferenced.