This section analyzes the performance gain that can be expected from an aggressive bytecode compiler. We compare execution of Harissa compiled programs with several industrial JIT compilers, the J2C and Toba bytecode compilers, and the JDK 1.0.2 interpreter.
Performance of JIT compilers is by nature sensitive to the target architecture since they compile into native code. To get more representative results, we have run the benchmarks on two different platforms: a Dell 100Mhz Pentium PC and a Sun 85 Mhz Sparcstation 5 (SS5). On the Pentium, Harissa is compared with the JIT compilers embedded in Netscape 3.0 and Microsoft Internet Explorer 3.0. On the Sparc, Harissa is compared with the Guava JIT compiler from Softway [6].
Three different kinds of benchmarks are presented: micro-benchmarks, which are used to evaluate the efficiency of JIT and off-line compilers for pure computations (without I/O); large benchmarks, which are used to compare JIT and off-line compilers for real applications that include I/O; and finally, benchmarks to evaluate the effectiveness of the CHA for Java applications.
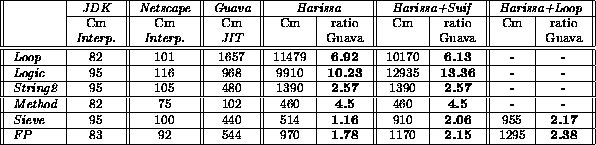
Figure 4 summarizes our results. The micro-benchmark tests are made using Caffeine 2.5 [10]. Each Caffeine micro-benchmark tests one feature of the Java machine. On these tests, Harissa generated code is on average 50 times faster than JDK, 5 times faster than Softway Guava JIT [6] and 50% faster than Microsoft JIT.
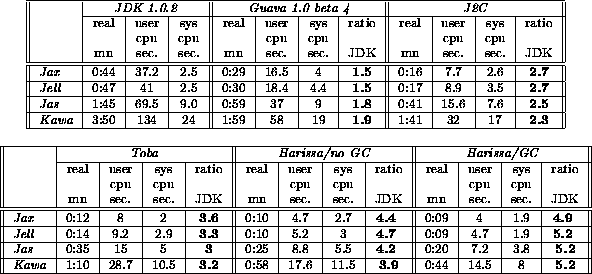
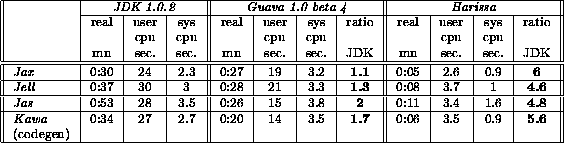
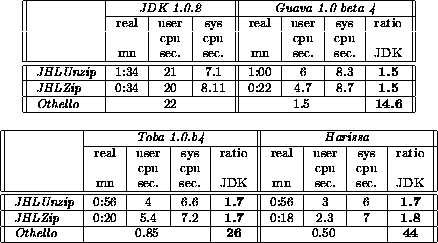
On real application benchmarks, results depend mainly on how much pure computation the program does. On applications dominated by I/O, such as JHLZip and JHLUnzip, there is not much difference between off-line and JIT compilers; JDK is only 1.5 slower that Harissa. On applications such as Javac and Javadoc which rely on a mixed set of computation and I/O, Harissa is 5 times faster than JDK, 3 times faster than Softway Guava JIT and 30% faster than the Toba [9] bytecode compiler. On pure computation programs, such as an Othello game [28], Harissa is 2.6 times faster than Guava, 1.7 faster than Toba and 44 times faster than JDK. Toba results are missing when it was not possible to run it successfully, for reasons described below.
Harissa has been configured so that during compilation, only methods with a size smaller than 100 instructions are inlined. The C code generated by Harissa and J2C has been compiled using gcc with the ``-O2'' option. The gcc version used is 2.7.2 on the Sun and 2.7.0 on the PC/Linux. Toba-generated C code has been compiled using Sun's commercial C compiler with the ``-xO4'' option.
The Caffeine micro-benchmarks produce numbers, in CaffeineMarks (higher is faster), that allow one to compare heterogeneous architectures and Java implementations directly. Among them, we consider those that are related to the compilation scheme and that do not rely on graphic computations or the garbage collector:
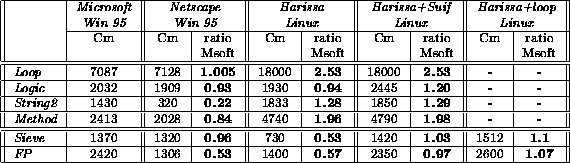
The results of our evaluation are presented in Table 1 for the SS5 and in Table 2 for the PC. The two rightmost columns present Harissa's results with some further optimizations that are described below. In general, the PC is faster than the Sun. On the SS5, JDK and the interpreter embedded in Netscape achieve similar results, while the code generated by Harissa is 5 to 140 times faster than the JDK interpreter. On the PC, Microsoft's JIT compiler seems to be slightly faster than the Netscape's one, except for the tests String2 and FP, which are twice as fast under Microsoft.
Table 1: Comparison between JIT and Harissa on a 85Mhz SS5 (in CaffeineMarks, Cm)
The relevance of the micro-benchmarks when comparing JIT compilers and Harissa is to measure the efficiency of the compilation scheme. Since the tests loop on the same code, JIT compilers do not loose time during execution waiting for the compilation of a method. Furthermore, with the exception of the Method test, no method calls are made. Harissa's inter-procedural optimizations such as CHA and method inlining thus have very little influence on the results. Therefore, these tests permit to evaluate precisely the quality of the code that is produced by JIT compilers.
Our measurements show that the code generated by Harissa'compiler is basically always faster than JIT compilers. Nevertheless, the results are architecture dependent. On the SS5, Harissa is 1.5 (for Sieve) to 13 (for logic) times faster than the JIT Guava. On the PC, results are more balanced and the difference in performance between Harissa and Microsoft is smaller than between Harissa and Guava, with a maximum of 2.5 times faster. For two tests, Sieve and FP, Harissa is actually twice as slow.
Table 2: Comparison between JIT and Harissa on a 100Mhz PC-Pentium (in CaffeineMarks, Cm)
To understand the reasons for the inefficiency of the code generated by Harissa for the tests Sieve and FP, we have analyzed the assembly code generated by gcc. For the Sieve test, it appears that the critical loop is about 20 instructions long. That does not leave much room for possible optimizations.
We have identified two reasons for inefficiency, which are in fact due to limitations of the gcc optimizer. As expected, transient stack variables are eliminated by gcc. But further optimizations resulting from variable and constant propagation are not triggered. For instance, in the Sieve test, stack variable elimination transforms a ``divide by i'' into a ``divide by 2'' that could then be efficiently transformed into a shift instruction. To evaluate the impact of this problem, we have used the Suif C optimizer [16] to systematically eliminate these variables using a combination of the ``constant/variable propagation'' and ``dead code elimination'' passes. The effect on the PC is dramatic for the FP and Sieve tests, nearly doubling the performance improvement. On the other tests there is little or no influence, which shows that this situation is not so frequent. On the Sparc, the influence of stack variable elimination is lower than on the PC. This is because the relative cost of processor instructions differs significantly between the Sparc and the Pentium.
A second source of inefficiency is the fact that loops are compiled into bytecode goto instructions. Therefore, gcc does not have all the necessary information to make the best choice regarding caching of temporary results in registers. To determine the consequences of this problem, we have reconstructed loops by hand for the Sieve and FP benchmarks. On both the Sparc and the PC, there is a performance increase between 5% to 10%. Finally, it should be noted that after performing the optimizations, Harissa's compiled code is about 10% faster than Microsoft's JIT.
These benchmarks are used to estimate the efficiency of Harissa in a real environment. To do so, we have evaluated the execution time of a set of programs that either do pure computations, substantial I/O, or a mixture of both. Pure computation programs are represented by an Othello game [28]. File handling applications (e.g., I/O) are represented by JHLZip and JHLUnzip, which insert and extract file from an archive without compression. Mixed computation-I/O programs are represented by two Sun's JDK tools, the Javac compiler and the javadoc documentation generator, and by Kawa, a scheme interpreter [29].
The benchmarks were made in a single-user environment to avoid external interferences. It was not possible to run benchmarks for JIT compilers embedded in the Web browsers for security protection reasons. Performance of tools such Javac and javadoc depends significantly on their input. To get representative results, we ran them on a set of large Java programs that are available on the net:
Comparisons are performed on real execution time, which includes waiting for the end of I/O, since this corresponds to what the user observes. For completeness, we have also detailed user and system CPU time spent during the execution to measure the efficiency of pure computations.
Table 3: Compilation time of several Java programs
Detailed timing of Javac execution are presented in Table 3. In comparison with JDK, Harissa achieves the highest speedup which is greater than 5. Toba is on average 3.3 times faster than JDK, J2C is about 2.5 times faster, and Guava is 1.5 times faster. These results clearly show the benefits of the various optimizations performed in Harissa.
We have also compared Harissa's GC version with the non-GC one. The GC version version is 20% faster than the non-GC one. This due to the fact that never reclaiming objects leads to an increase in swapping, I/O, and in the amount of address space that has to be allocated by the system to the process.
Javadoc is representative of tools that rely on the dynamic capabilities provided by Java to load bytecode during execution. Therefore, it is not possible to execute it with a pure bytecode to C compiler such as Toba or J2C. Although dynamically loaded classes are interpreted, most of the execution time is spent in the compiled code. Thus, Harissa's generated code is on average 5 times faster than JDK and 3 times faster than Guava.
Table 4: Javadoc execution time
JHLZip and JHLUnzip tools [31] insert and extract files from an archive. The tested version of these tools does not include compression and therefore, execution is dominated by I/Os. Our tests have been done using the JDK 1.0.2 classes.zip file as input. As it could be expected, compilers (off-line and JIT) achieve the same level of performance. Finally, JDK is only 1.5 slower than the compilers.
The tested implementation of Othello game [28] allocates a finite time to the computer player to solve one move. The depth of the search depends on the speed of the generated code. We give the time spent to solve up to depth 5 on the first move.
Table 5: Other Benchmarks
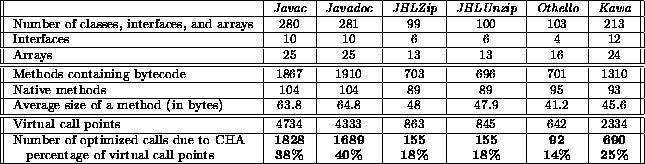
Table 6: Detailed analysis of method and classes
The impact of the class hierarchy analysis has been studied for many object-oriented languages, including Java. It has been shown that this analysis can improve program performance between 23% to 89% [11]. Table 6 presents the impact of CHA for the programs we have benchmarked. It shows that our CHA implementation allows between 14% to 40% of the virtual call points to be transformed into procedure calls.