Harissa is a Java environment that includes a compiler from Java bytecode to C and a Java Virtual Machine integrated in a runtime library. While Harissa is aimed at applications that are statically configured, such as the Javac compiler, it is also designed to allow code to be dynamically loaded in an already compiled application. This novel feature is introduced by integrating a bytecode interpreter into the runtime library. Data structures between the Java compiled code and the interpreter are compatible and data allocated by the interpreter do not conflict with data allocated by the compiled code. Harissa is written in C and is designed with the primary goal of providing efficient and flexible execution of Java applications.
Because Harissa is written in C and its compiler generates C code, it is easily portable. In fact, current ports include SunOS, Solaris, Linux, and Dec Alpha. This allows us to compare the effects of optimizations on different architectures.
Because Harissa's compiler produces C programs, various compilers and optimizers can be used. As a result, contrary to JIT compilers, the generated C code does not have to be heavily optimized, since final optimizations are made by the C compiler. Harissa only concentrates on inefficiencies due to the architecture of the Java Virtual Machine: stack and method calls. To do so, several transformations are introduced. First, the stack is statically evaluated away. This analysis is described in section 3.3. Second, virtual method calls are transformed, when possible, into static (i.e., procedure) calls. For these virtual calls, type checks are also eliminated. This is described in section 3.4. Finally, Harissa implements several other optimizations for object-oriented languages such as method inlining, which are not presented.
The following sections describe the system in more detail.
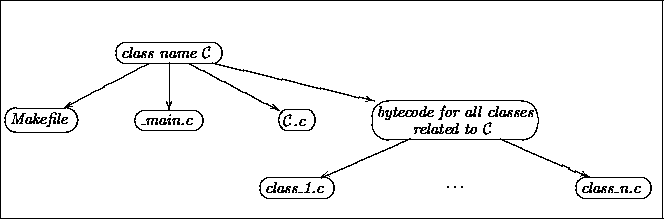
Figure 1: Set of generated C files given an initial class name ![]()
Harissa's compiler takes as input a class ![]() containing a
main method and generates as output a makefile, a
_main.c file, and a C source file for each class used in the
program(see Figure 1). To determine the set of
classes that depend on the initial class, an analysis is recursively
performed on the bytecode to search for all the classes referenced by
the main class. Because of the simplicity of this phase, it is omitted
in the paper.
containing a
main method and generates as output a makefile, a
_main.c file, and a C source file for each class used in the
program(see Figure 1). To determine the set of
classes that depend on the initial class, an analysis is recursively
performed on the bytecode to search for all the classes referenced by
the main class. Because of the simplicity of this phase, it is omitted
in the paper.
Compilation of a method's bytecode into C is organized as follows:
The following sections present our intermediate bytecode representation and the main algorithms that have an impact on performance. That is, the calculation of the stack pointer and the types of the stack instructions, and the transformation of virtual method calls into static procedure calls.
Our intermediate bytecode representation has a simpler and more regular syntax, and contains more detailed information than the original Java bytecode. The main difference is that, in the IBR, the types of the arguments of the instructions that handle the stack are made explicit. This information simplifies subsequent passes.
The data structures defining the IBR are shown in Figure 2. A method contains information about its body and the exceptions that it can raise. Associated with each exception is the program counter of its handler. The CodeInfo structure has all the information about each instruction. Fields in_sig and out_sig represent the instruction's input and output signature, respectively. This explicit representation of signature types eases the subsequent analyses. The analysis described in the next section infers the type of instructions whose type is not explicit in the Java bytecode.
Figure 2: Inferring instruction's type
This analysis statically evaluates the stack by calculating the value of the stack pointer and the types of all the bytecode instructions. Most Java bytecode instructions have their type already associated with them, except those that control the stack. Because of the constraints enforced by the Java bytecode verifier [20], at each program point a stack instruction can have only one type signature. For example, when the instruction DUP is used to duplicate an integer, it can not be used at the same program point to duplicate a double. Thus, we can straightforwardly infer the types of the stack operations.
The analysis of a method via CalculateSPandTypes abstractly interprets each instruction with respect to a Stack structure (see Figure 2), which contains the current stack pointer value and the type of its items. AnalyseCode and AnalyseExc interpret the method's body and the code fragments corresponding to the method's exception handlers, respectively. The stack is initially empty. Abstract interpretation of an instruction can modify the contents of the stack. If an instruction I branches to more than one program point, then each branch is interpreted with respect to the stack resulting from abstractly interpreting I. Note that for the specific case of the jump to subroutine instruction (JSR), used to implement exceptions, the stack is assumed to be empty before and after the execution of the instruction. The JSR and RET instructions are considered to have the same control flow as a test instruction and the RETURN instruction, respectively. This approximation is not correct in terms of control flow information but gives correct results for stack type information.
Interpretation of an instruction is as follows: if the type of the instruction is not explicit in the Java bytecode, then the analysis has to infer it. The input signature is inferred from the types on the stack (function infer_in_sig). The output signature is inferred by abstractly interpreting the instruction with respect to this input signature (function infer_out_sig). Once the signature is known, then the instruction is abstractly interpreted with respect to the stack and its signature, with functions pop_sig and push_sig. The former checks for type consistency between the input signature and the type of the items it pops off the stack and the latter pushes the instruction's output signature onto the stack.
Object-oriented programming encourages both code factoring and differential programming. This results in smaller procedures and more procedure calls. Procedure calls in an object-oriented language are dynamically dispatched. There are many analyses targeted at optimizing dynamically dispatched message sends. The most common are: intra-procedural static class analysis [11], class hierarchy analysis (CHA) [11], and profile-guided class receiver prediction [21]. In Harissa, we have opted to integrate a class hierarchy analysis to address this problem.
A class hierarchy analysis is a static analysis that determines a
program's complete class inheritance graph (CIG) and the set of
methods defined in each class. With the CIG, a specific set of
possible classes, given that the receiver is a subclass of the class
![]() , can be statically inferred and messages sent to the
method's receiver can be optimized. Further, if there are no
overriding methods in subclasses, a message sent to the method's
receiver can be replaced with a direct procedure call and possibly
inlined. Inlining of a method can trigger other opportunities for
converting dynamic method calls into static ones. Hence, these two
transformations are iterated.
, can be statically inferred and messages sent to the
method's receiver can be optimized. Further, if there are no
overriding methods in subclasses, a message sent to the method's
receiver can be replaced with a direct procedure call and possibly
inlined. Inlining of a method can trigger other opportunities for
converting dynamic method calls into static ones. Hence, these two
transformations are iterated.
The generation of the C code for a method is done in three phases. First, the goto labels and exception handlers are generated. Then, the local variables of a method are declared and, finally, each IBR instruction is translated to C.
Generation of goto labels and declaration of local variables are simple and are not discussed here. The treatment of exceptions needs some explanation. To ensure portability, Harissa handles exceptions in a stack-based manner. In the Java bytecode, each exception has a region associated to it. As described in the bytecode verifier documentation [20], different exception regions are either disjoint or nested, but cannot overlap. When translating the intermediate bytecode to C, entering of an exception region pushes the corresponding exception handler onto the stack, and exit of an exception region pops the exception handler off the stack. If a jump or goto instruction leaves an exception region or a set of nested exception regions, the corresponding exception handlers are popped off the stack prior to the jump or goto instruction.
The actual generation of the C code from the intermediate bytecode representation is straightforward. Figure 3-a shows some Java source code for a method computing a power function, Figure 3-b shows the corresponding Java bytecode. Figure 3-c shows the translated C code. In the C code, the stack has been statically evaluated: variable names prefixed with ``s'' are variables that handle the stack, while variable names prefixed with ``v'' are user-defined variables. An assignment to an s-variable corresponds to pushing a value on the stack. A use of an s-variable corresponds to popping a value off the stack. The s-variables can be eliminated either by a C compiler or by a C optimizer such as Suif [16]. Figure 3-d shows the optimized code generated by Suif.
Figure 3: Compilation of the power method
The implementation of a class includes a vector of function pointers that store the addresses of procedure implementing methods. Initialisation of this vector is performed when intantiating the class either at compile-time, by the compiler, or at run-time when dynamically loading byte-code. After initialisation, a pointer may refer either to a C procedure (i.e., method) of the compiled class, to a C procedure of an inherited compiled class, to a C native function of the run-time library, or to a stubc procedure. A stubc procedure interfaces compiled code with the interpreter: it allocates a stack for the interpreter, pushes arguments, calls the intrepreter's entry-point, and pops the result. Stubc procedures are generated by the compiler for each method that might be dynamically overloaded.
Interface calls are implemented using of a two dimensional sparse vector of function pointers for each class. The first dimension equals to the total number of interfaces referenced by the program, each interface being assigned an index at compile time. When a class is instantiated, if the class implements a given interface, the corresponding second dimension of the vector is allocated and is initialized with C procedures.
Harissa is provided in two versions, with and without garbage collection (GC). This allows us to estimate the influence of GC on its performance. The GC version is based on the Boehm-Demers-Weiser conservative garbage collector [22]. The non-GC version relies on malloc, which leads to an increase in swapping and I/O since objects are never deallocated.
At the current time, threads are not implemented. Nevertheless, the system is already conceived to include them and the generated C code contains the necessary calls to synchronization functions. Implementation of synchronization optimizes the single thread case. As long as no additional threads are created, synchronization calls point to a null procedure. Additional threads creation is detected by guards [23] that then plug-in the multi-thread synchronization function.
For efficiency, Harissa produces a target C that relies on some gcc extensions. This is not a major limitation since gcc is available on many platforms. We plan to eliminate this dependency, in order to be able to test vendor C compilers. Finally, there are some native libraries, such as the graphic library, that are not yet supported.