In this section of the paper, we discuss two applications that demonstrate the validity of our guiding principles and the efficacy of our MultiSpace implementation. The first application, the Ninja Jukebox, abstracts the many independent compact-disc players and local filesystems in the Berkeley Network of Workstations (NOW) cluster into a single pool of available music. The second, Keiretsu, is a three-tiered application that provides instant messaging across heterogeneous devices.
The original goal of the Ninja jukebox was to harness all of the audio CD players in the Berkeley NOW (a 100+ node cluster of Sun UltraSparc workstations) to provide a single, giant virtual music jukebox to the Berkeley CS graduate students. The most interesting features of the Ninja Jukebox arise from its implementation on top of iSpace: new nodes can be dynamically harnessed by pushing appropriate CD track ``ripper'' services onto them, and the features of the Ninja Jukebox are simple to evolve and customize, as evidenced by the seamless transformation of the service to the batch conversion of audio CDs to MP3 format, and the authenticated transmission of these MP3s over the network.
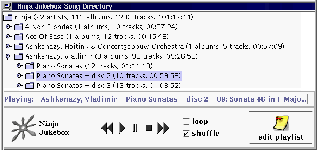
Figure 4: The Ninja Jukebox GUI: users are presented with a single
Jukebox interface, even though songs in the Jukebox are scattered across
multiple workstations, and may be either MP3 files on a local filesystem,
or audio CDs in CD-ROM drives.
The Ninja Jukebox service is decomposed into three components: a master directory, a CD ``ripper'' and indexer, and a gateway to the online CDDB service [22] that provides artist and track title information given a CD serial number. The ability to push code around the cluster to grow the service proved to be exceptionally useful, since we didn't have to decide a priori which nodes in the cluster would house CDs--we could dynamically push the ripper/indexer component towards the CDs as the CDs were inserted into nodes in the cluster. When a new CD is added to a node in the NOW cluster, the master directory service pushes an instance of the ripper service into the iSpace resident on that node. The ripper scans the CD to determine what music is on it. It then contacts a local instance of the CDDB service to gather detailed information about the CD's artist and track titles; this information is put into a playlist which is periodically sent to the master directory service. The master directory incorporates playlists from all of the rippers running across the cluster into a single, global directory of music, and makes this directory available over both RMI (for song browsing and selection) and HTTP (for simple audio streaming).
After the Ninja Jukebox had been running for a while, our users expressed
the desire to add MP3 audio files to the Jukebox.
To add this new behavior, we only had to subclass the CD ripper/indexer to
recognize MP3 audio files on the local filesystem, and create new Jukebox
components that batch converted between audio CDs and MP3 files. Also, to
protect the copyright of the music in the system we added access control
lists to the MP3 repositories, with the policy that users could only listen
to music that they had added to the Jukebox. We then began pushing this new subclass to nodes in
the system, and our system evolved while it was running.
We then began pushing this new subclass to nodes in
the system, and our system evolved while it was running.
The performance of the Ninja Jukebox is completely dominated by the overhead of authentication and the network bandwidth consumed by streaming MP3 files. The first factor (authentication overhead) is currently benchmarked at a crippling 10 seconds per certificate exchange, entirely due to a pure Java implementation of a public key cryptosystem. The second factor (network consumption) is not quite as crippling, but still significant: each MP3 consumes at least 128 Kb/s, and since the MP3 files are streamed over HTTP, each transmission is characterized by a large burst as the MP3 is pushed over the network as quickly as possible. Both limitations can be remedied with significant engineering, but this would be beyond the scope of our research.
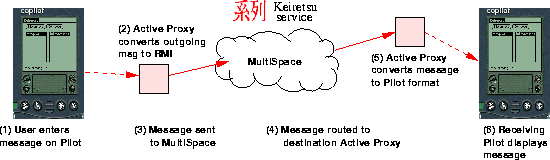
Figure 5: The Keiretsu Service
Keiretsu is a
MultiSpace service that provides instant messaging between
heterogeneous devices: Web browsers, one- or two-way pagers, and
PDAs such as the Palm Pilot (see Figure 5). Users are able
to view a list of other users connected to the Keiretsu service, and can
send short text messages to other users. The service component
of Keiretsu exploits the MultiSpace features: Keiretsu service
instances use the soft-state registry of peer nodes in order to exchange
client routing information across the cluster, and automatically generated
Redirector Stubs are handed out to clients for use in communicating with
Keiretsu nodes.
Keiretsu is a three-tired application: simple client devices (such as pagers or Palm Pilots) that cannot run a JVM connect to an Active Proxy, which can be thought of as a simplified iSpace node meant to run soft-state mobile code. The Active Proxy converts simple text messages from devices into NinjaRMI calls into the Keiretsu MultiSpace service. The Active Proxies are assumed to have enough sophistication to run Java-based mobile code (the protocol conversion routines) and speak NinjaRMI, while rudimentary client devices need only speak a simple text-based protocol.
As described in section 2.3, Redirector Stubs are used to access the back-end service components within a MultiSpace by pushing load-balancing and failover logic towards the client--in the case of simple clients, Redirector Stubs execute in the Active Proxy. For each protocol message received by an Active Proxy from a user device (such as ``send message M to user U''), the Redirector Stub is invoked to call into the MultiSpace.
Because the Keiretsu proxy is itself a mobile Java component that runs on an iSpace, the Keiretsu proxy service can be pushed into appropriate locations on demand, making it easy to bootstrap such an Active Proxy as needed. State management inside the Active Proxy is much simpler than state management inside a Base--the only state that Active Proxies maintain is the session state for connected clients. This session state is soft-state, and it does not need to be carefully guarded, as it can be regenerated given sufficient intelligence in the Base, or by having users manually recover their sessions.
Rudimentary devices are not the only allowable members of a Keiretsu. More complex clients that can run a JVM speak directly to the Keiretsu, instead of going through an Active Proxy. An example of such a client is our e-mail agent, which attaches itself to the Keiretsu and acts as a gateway, relaying Keiretsu messages to users over Internet e-mail.

Figure 6: The Keiretsu service API
The MultiSpace service that performs message routing is surprisingly simple. Figure 6 shows the API exported by the service to clients. Through the identifySelf method, a client periodically announces its presence to the Keiretsu, and hands the Keiretsu an RMI stub which the service will use to send it messages. If a client stops calling this method, the Keiretsu assumes the client has disconnected; in this way, participation in the Keiretsu is treated as a lease. Alternately, a client can invalidate its binding immediately by calling the disconnectSelf method. Messages are sent by calling the injectMessage method, and clients can obtain a list of other connected clients by calling the getClientList method.
Inside the Keiretsu, all nodes maintain a soft-state table of other nodes by listening to MultiSpace beacons, as discussed in section 3.3. When a client connects to a Keiretsu node, that node sends the client's RMI stub to all other nodes; all Keiretsu nodes maintain individual tables of these client bindings. This means that in steady state, each node can route messages to any client.
Because clients access the Keiretsu service through Redirector Stubs, and because Keiretsu nodes replicate service state, individual nodes in the Keiretsu can fail and service will continue uninterrupted, at the cost of capacity and perhaps performance. In an experiment on a 4-node cluster, we demonstrated that the service continued uninterrupted even when 3 of the 4 nodes went down. The Keiretsu source code consists of 5 pages of Java code; however, most of the code deals with managing the soft-state tables of the other Keiretsu nodes in the cluster and the client RMI stub bindings. The actual business of routing messages to clients consists of only half a page of Java code--the rest of the service functionality (namely, building and advertising Redirector Stubs, tracking service implementations across the cluster, and load balancing and failover across nodes) is hidden inside the MultiSpace layer. We believe that the MultiSpace implementation is quite successful in shielding service authors from a significant amount of complexity.
We ran an experiment to measure the performance and scalability of our MultiSpace implementation and the Keiretsu service. We used a cluster of 400 MHz Pentium II machines, each with 128 MB of physical memory, connected by a 100 Mb/s switched Ethernet. We implemented two Keiretsu clients: the ``speedometer'', which open up a parameterizable number of identities in the Keiretsu and then waits to receive messages, and the ``driver'', which grabs a parameterizable number of Redirector Stubs to the Keiretsu, downloads a list of clients in the Keiretsu, and then blasts 75 byte messages to randomly selected clients as fast as it can.
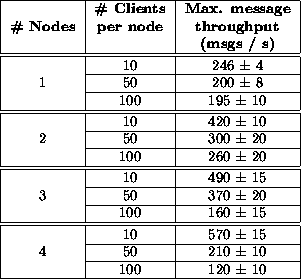
Table 2:
Keiretsu performance: These benchmarks were run on
400Mhz Pentium II machines, each with 128MB of physical memory,
connected by a 100 Mb/s switched Ethernet, using Sun's JDK 1.1.6v2 with the
TYA just-in-time compiler on Linux 2.2.1, and sending 75 byte Keiretsu
messages.
We started our Keiretsu service on a single node, and incrementally grew the cluster to 4 nodes, measuring the maximum message throughput obtained for 10x, 50x, and 100x ``speedometer'' receivers, where x is the number of nodes in the cluster. To achieve maximum throughput, we added incrementally more ``driver'' connections until message delivery saturated. The drivers and speedometers were located on many dedicated machines, connected to the Keiretsu cluster by the same 100 Mb/s switched Ethernet. Table 2 shows our results.
For a small number of receivers (10 per node), we observed linear scaling in the message throughput. This is because each node in the Keiretsu is essentially independent: only a small amount of state is shared (the client stubs for the 10 receivers per node). In this case, the CPU was the bottleneck, likely due to Java overhead in message processing and argument marshalling and unmarshalling.
For larger number of receivers, we observed a breakdown in scaling when the
total number of receivers reached roughly 200 (i.e. 3-4 nodes at 50
receivers per node, or 2 nodes at 100 receivers per node). The CPU was
still the bottleneck in these cases, but most of the CPU time was spent
processing the client stubs exchanged between Keiretsu nodes, rather than
processing the clients' messages. This is due to poor design of the
Keiretsu service; we did not need to exhange client stubs as frequently as
we did, and we should have simply exchanged timestamps for previously
distributed stubs rather than repeatedly sending the same stub. This
limitation could be also removed by modifying the Keiretsu service to
inject client stubs in a distributed hash table, and rely on service
instances to pull the stubs out of the table as needed. However, a similar
![]() state exchange happens at the MultiSpace layer with the multicast
exchange of service instance stubs; this could potentially become another
scaling bottleneck for large clusters.
state exchange happens at the MultiSpace layer with the multicast
exchange of service instance stubs; this could potentially become another
scaling bottleneck for large clusters.