We now present results from our prototype to demonstrate the scalability of the cluster when presented with real, trace-based workloads.
The workloads were obtained from logs of a Rice University Web site and from the www.ibm.com server, IBM's main Web site. The data set for the Rice trace consists of 31,000 targets covering 1.015 GB of space. This trace needs 526/619/745 MB of cache memory to cover 97/98/99% of all requests, respectively. The data set for the IBM trace consists of 38,500 targets covering 0.984 GB of space. However, this trace has a much smaller working set and needs only 43/69/165 MB of cache memory to cover 97/98/99% of all requests, respectively.
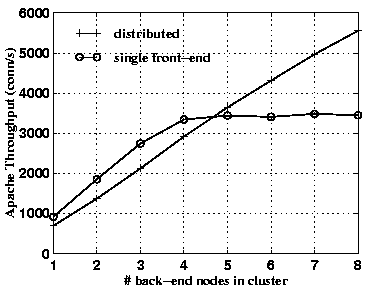
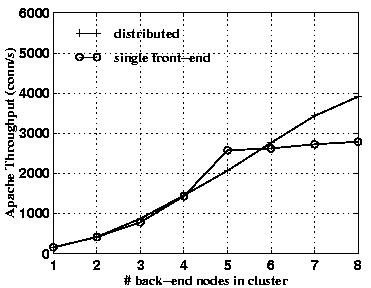
The results presented in Figures 12 and 13 clearly show that our proposed cluster architecture for content-aware request distribution scales far better than the state-of-the-art approach based on handoff at a single front-end node, on real workloads.
Note that for cluster sizes below five on the IBM trace, the performance with a single front-end node exceeds that of our distributed approach. The reason is the same as that noted earlier: with the former approach, the front-end offloads the cluster nodes by performing the request distribution task, leaving more resources on the back-end nodes for request processing. However, this very fact causes the front-end to bottleneck at a cluster size of five and above, while the distributed approach scales with the number of back-end nodes.
This effect is less pronounced in the Rice trace, owing to the much larger working set size in this trace, which renders disk bandwidth the limiting resource. For the same reason, the absolute throughput numbers are significantly lower with this workload.
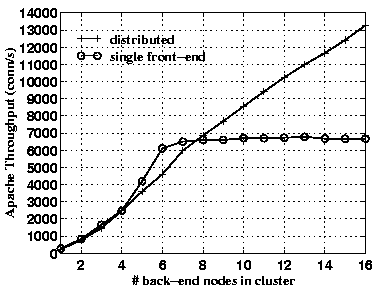
Finally, Figure 14 shows results obtained with the Rice trace on a new, larger cluster. The hardware used for this experiment consists of a cluster of 800MHz AMD Athlon based PCs with 256MB of main memory each. The cluster nodes, the node running the dispatcher, and the client machines are connected by a single 24 port Gigabit Ethernet switch. All machines run FreeBSD 2.2.6.
The results show that the performance of the cluster scales to a size of 16 nodes with no signs of slowing, despite the higher individual performance (faster CPU and disk, larger main memory) of the cluster nodes. The throughput obtained with 16 nodes exceeds 13,000 conn/s on this platform, while the single (800MHz) front-end based approach is limited to under 7,000 conn/s. Limited hardware resources (i.e., lack of a Gigabit Ethernet switch with more than 24 ports) still prevent us from demonstrating the scalability limits of our approach, but the measured utilization of the dispatcher node is consistent with our prediction that the approach should scale to at least 50,000 conn/s.