
Having observed significant heterogeneity across nodes, we now examine how that heterogeneity combines with the resource requirements of real applications to dictate the potential usefulness of informed application placement. In order to do this, we first must develop models of these applications' resource demands. In particular, we study resource usage by three long-running PlanetLab services.
We chose these services because they are continuously-running, utilize a large number of PlanetLab nodes, and serve individuals outside the computer science research community. They are therefore representative of ``production'' services that aim to maximize user-perceived performance while coexisting with other applications in a shared distributed infrastructure. They are also, to our knowledge, the longest-running non-trivial PlanetLab services. Note that during the time period of our measurement trace, these applications underwent code changes that affect their resource consumption. We do not distinguish changes in resource consumption due to code upgrades from changes in resource consumption due to workload changes or other factors, as the reason for a change in application resource demand is not important in addressing the questions we are investigating, only the effect of the change on application resource demand.
We study these applications' resource utilization over time and across nodes to develop a loose model of the applications' resource needs. We can then combine that model with node-level resource data to evaluate the quality of different mappings of slivers (application instances) to nodes. Such an evaluation is essential to judging the potential benefit of service placement and migration.
Figures 6, 7, and 8 show CPU demand and outgoing network bandwidth for these applications over time, using a log-scale Y-axis. Due to space constraints we show only a subset of the six possible graphs, but all graphs displayed similar characteristics. Each graph shows three curves, corresponding to the 5th percentile, median, and 95th percentile resource demand across all slivers in the slice at each timestep. (For example, the sliver whose resource demand is the 95th percentile at time t may or may not be the same sliver whose resource demand is the 95th percentile at time t+n.)
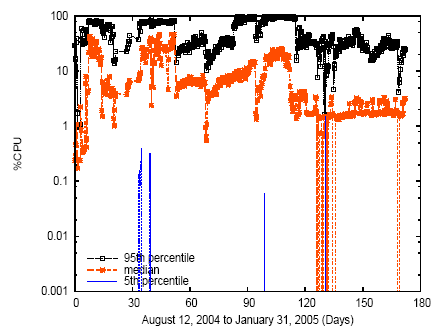
Figure 6: CPU resource demand for OpenDHT, using a log-scale Y-axis.
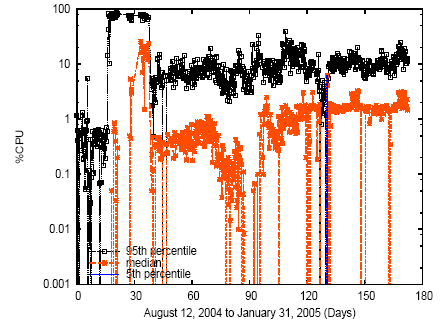
Figure 7: CPU resource demand for Coral, using a log-scale Y-axis.
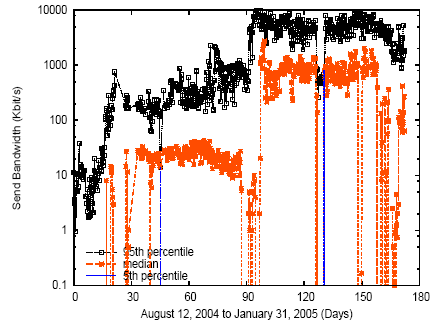
Figure 8: Transmit bandwidth demand for Coral, using a log-scale Y-axis.
We see that a service's resource demands vary significantly across slivers at any given point in time. For example, all three graphs show resource demand varying by at least an order of magnitude from the median sliver to the 95th percentile sliver. These results suggest that not only available host resources, but also variable per-sliver resource demand, must be considered when making placement decisions.
One interpretation of widely varying per-sliver demands is that applications are performing internal load balancing, i.e., assigning more work to slivers running on nodes with ample free resources. However, these three applications principally use a hash of a request's contents to map requests to nodes, suggesting that variability in per-node demands is primarily attributable to the application's external workload and overall structure, not internal load balancing. For instance, OpenDHT performs no internal load balancing; Coral's Distributed Sloppy Hash Table balances requests to the same key ID but this balancing does not take into account available node resources; and CoDeeN explicitly takes node load and reliability into account when choosing a reverse proxy from a set of candidate proxies.
Given this understanding of the resource demands of three large-scale applications, we can now consider the potential benefits of informed service placement. To answer this question, we simulate deploying a new instance of one of our three modeled applications across PlanetLab. We assume that the new instance's slivers will have resource demands identical to those of the original instance. We further assume that that the new instance will use the same set of nodes as the original, to allow for the possibility that the application deployer intentionally avoided certain nodes for policy reasons or because of known availability problems. Within these constraints, we allow for any possible one-to-one mapping of slivers to nodes. Thus, our goal is to determine how well a particular service placement algorithm will meet the requirements of an application, knowing both the application's resource demands and available resources of the target infrastructure.
We simulate two allocation algorithms. The random algorithm maps slivers to nodes randomly. The load-sensitive algorithm deploys heavily CPU-consuming slivers onto lightly loaded nodes and vice-versa. In both cases, each sliver's resource consumption is taken from the sliver resource consumption measurements at the corresponding timestep in the trace, and each node's amount of free resources is calculated by applying the formulas discussed in Section 2 to the node's load and bandwidth usage indicated at that timestep in the trace. We then calculate, for each timestep, the fraction of slivers whose assigned nodes have ``sufficient'' free CPU and network resources for the sliver, as defined in Section 2. If our load-sensitive informed service placement policy is useful, then it will increase, relative to random placement, the fraction of slivers whose resource needs are met by the nodes onto which they are deployed. Of course, if a node does not meet a sliver's resource requirements, that sliver will still function from a practical standpoint, but its performance will be impaired.
Figures 9 and 10 show the fraction of nodes that meet application CPU and network resource needs, treating each timestep in the trace as a separate deployment. As Figures 2 and 3 imply, CPU was a more significant bottleneck than node access link bandwidth. We see that the load-sensitive placement scheme outperforms the random placement scheme, increasing the number of slivers running on nodes that meet their resource requirements by as much as 95% in the case of OpenDHT and as much as 55% in the case of Coral (and CoDeeN, the graph of which is omitted due to space constraints). This data argues that there is potentially significant performance improvement to be gained by using informed service placement based on matching sliver resource demand to nodes with sufficient available resources, as compared to a random assignment. A comprehensive investigation of what application characteristics make informed node selection more beneficial or less beneficial for one application compared to another is left to future work.
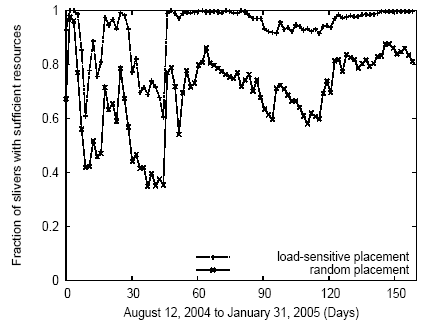
Figure 9: Fraction of OpenDHT slivers whose resource requirements are met by the node onto which they are deployed, vs. deployment time.

Figure 10: Fraction of Coral slivers whose resource requirements are met by the node onto which they are deployed, vs. deployment time. We note that Coral's relatively low per-sliver CPU resource demands result in a larger fraction of its slivers' resource demands being met relative to OpenDHT.
David Oppenheimer 2006-04-14