
The role classification algorithms are implemented as part of a system designed to detect and respond to security violations in large enterprise networks. Such networks commonly consist of tens of thousands of computers, spread over different geographic locations. The security system consists of probes and a central aggregator. The probes analyze packets on the link or links they are attached to, and send relevant information (including IP address/port tuples) to the aggregator.
The aggregator is a scalable system that consists of one or more CPUs. It periodically runs several analysis algorithms on the data it has received from the probes. It uses the role classification algorithms to refine its analyses and to allow the administrators to describe group-based policies.
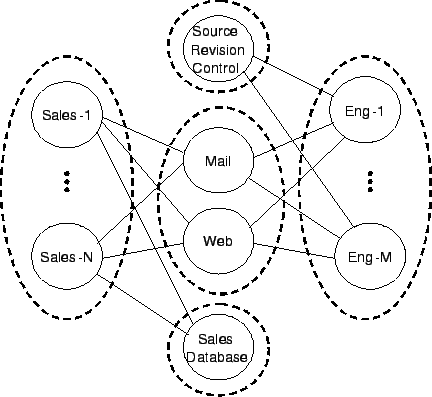 |
Figure 1 presents a simple enterprise network and a partitioning of computers into groups that the aggregator might produce based on the communication patterns observed by the probes. The communication patterns might indicate that hosts Sales-1 to Sales-N communicate with three servers: Mail server, Web server, and SalesDatabase server. Similarly, the patterns might indicate that hosts Eng-1 to Eng-M communicate mostly with Mail server, Web server, and SourceRevisionControl server.
Based on this information the grouping algorithm can logically divide all machines into five groups: (i) the sales group consisting of hosts Sales-1 to Sales-N, (ii) the engineering group consisting of hosts Eng-1 to Eng-M, (iii) the common server group consisting of Mail and Web, (iv) the sales server group consisting of SalesDatabase and (v) the engineering server group consisting of SourceRevisionControl.
The results of the grouping algorithm are currently being used in two major ways:
The system allows a network manager to label each identified group with descriptive roles and set policies per group. The system continuously monitors the communication patterns, adjusts groups as computers come and go, flags policy violations, and raises alerts about potential security violations. Because all this information is presented on the level of groups (instead of individual hosts), a network manager is able to understand and process the changes and alerts more easily. The algorithms also provide network administrators with flexibility to control the grouping process to achieve results that highly reflect their intuitive notion of the network structure.
The algorithms presented in this paper are solely based on the connection patterns of hosts such as the set of neighboring hosts. However, the algorithms can easily be extended to use other information such as protocols and port numbers used and bytes transferred to achieve desired results. For instance, some network administrators may desire that Mail and Web servers be put in different groups. In this case, the protocol information can be used to keep the role classification algorithm from grouping together hosts that use different sets of protocols. We are currently exploring ways to expand the capability of the grouping and correlation algorithms by providing network administrators with more flexibility to achieve desired results.
The algorithms assume that the connection patterns of hosts highly reflect the logical roles that they play. For some networks where this is not true, the algorithms will not do a good job. However, we believe that hosts in a typical enterprise network that share the same logical role will demonstrate similar connection patterns.