
To determine the raw performance of OCF, we use a single-threaded program that repeatedly encrypts and decrypts a fixed amount of data with various symmetric-key algorithms, using the /dev/crypto interface. We run the test against all the hardware accelerators listed in the previous section, as well as using the kernel-resident software implementation of the algorithms. We vary the amount of data to be processed per request across experiments. To measure the overhead of OCF without the cryptographic algorithms, we added to the kernel a null algorithm that simply returns the data to the caller without performing any processing. The results can be seen in Figure 1.
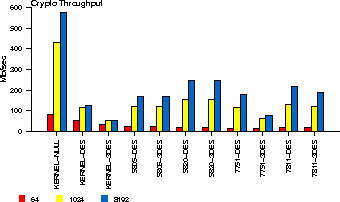 |
We can make several observations on this graph. First, even when no actual crypto is done, the ceiling of the throughput is surprisingly low for small-size operations (64 bytes). In this case, the measured cost consists of the overhead of system call invocation, argument validation, and crypto-thread scheduling. As larger buffers are passed to the kernel, the throughput increases dramatically, despite the increasing cost of memory-copying larger buffers in and out of the kernel. When we use 1024-byte buffers, performance in the no-encryption case jumps to 420 Mbps; for 8192-byte buffers, the framework peaks at about 600 Mbps.
Notice however that this peak corresponds to a single process issuing crypto requests. This process is blocked after each request, the scheduler context-switches to the crypto thread (which was blocked waiting for requests), the null algorithm executes and the completed request is passed back to the /dev/crypto driver, which wakes up the blocked user-level process. If many processes are issuing requests, the crypto thread's request queue will contain multiple requests. When we run multiple processes, each will queue a request (and be blocked by /dev/crypto); the crypto thread will process all these requests in a flurry of activity, and cause all processes to wake up in synchrony. The crypto thread will then go back to sleep, while each of the processes will issue another request. This cycle repeats for the duration of the experiment. As a result, more processes using the OCF result in increased aggregate throughput, simultaneously increasing the average processing latency.
These buffer sizes are close to the typical sizes of requests issued by some of the most-commonly used applications:
When we use real cryptographic algorithms, we notice that the performance of DES done in software is close to that of no encryption for small packet sizes; even 3DES performance is just half of the no-encryption case. If we use larger buffer sizes, the performance of software crypto done in the kernel (the KERNEL-* labeled bars) degrades rapidly. When we use hardware accelerators, we notice two different trends. For small buffers, the performance degrades with respect to the software case. This indicates that the additive costs of system call invocation, OCF processing, and the 2 PCI transactions (to/from the crypto cards) dominate the cost of doing crypto. However, as we move to larger buffer sizes, performance quickly improves as these overheads are amortized over larger buffers, despite the fact that more data has to be copied in and out of the kernel and over the PCI bus. Thus, to improve the performance of the system when applications issue large numbers of small requests, either request-batching should be done, a faster processor should be used, or the number of user/kernel crossings should be minimized. When larger buffers are being processed, it pays off to use some cryptographic accelerators, although not all such cards are equal in terms of performance.
Notice that the performance of DES and 3DES is the same in each of the 5805 and 5820 cards; these cards really implement only 3DES in Encrypt-Decrypt-Encrypt (EDE) mode, and emulate DES by loading the same key in one of the Encrypt and the Decrypt engines (effectively canceling each other out). In contrast, the 7751 seems to implement two separate crypto engines for DES and 3DES, or uses a shortcut in its 3DES engine. The 7811 seems to implement different engines as well, but the performance difference between the two is not as pronounced.
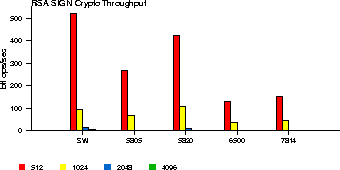 |
Similarly, we measure the performance of OCF for public-key operations. In this case, there are no kernel-resident software public-key algorithms. We count the number of RSA signature generations and verifications per second, for different accelerators and key sizes (512 to 4096 bits, as supported by the each cards). The results are shown in Figures 2 and 3.
The Hifn 6500 and 7814 are geared more towards slower, embedded applications, so the fact that their performance is considerably worse than software is not surprising. The number of verifications is much larger than the number of signature generations in unit time. This is because, as with most crypto libraries, OpenSSL opts for small values for the public part of the RSA key (typically, 216+1) and correspondingly large values for the private key. This causes the public-key operations (encryption and verification) to be much faster than the private-key operations, even though they are in principle the same operation (modular exponentiation).
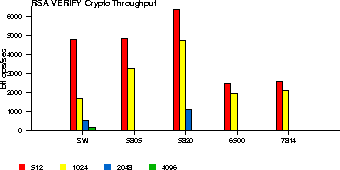 |
Another interesting observation is that the RSA sign throughput is higher in the software case (see Figure 2). This happens because the CPU on the crypto-card is slower than the host CPU and optimized for bit operations, which is as useful for public key cryptography. So the ``anomaly'' in Figure 2 is actually expected. However, as we mentioned in Section 5.1, Broadcom claims that the 5820 can perform 800 RSA signature operations per second with 1024-bit keys. In our case, we only see slightly over 100. There are two explanations for this. First, we are under-utilizing the 5820: there is only one thread issuing RSA sign operations, which is blocked waiting termination of each request. Once the card computes the signature, it has to wait for the crypto framework to wake up the blocked process, then the scheduler to context-switch to it, the process to issue an ioctl() call to get the results, and then another ioctl() call to issue the next request, which is placed on the crypto thread's queue. Finally, the scheduler has to context-switch to the crypto thread. During all this time, the accelerator is idle, since there is no other process using it. The second reason for the higher vendor-stated performance is that the tests they performed used the CRT parameters for the RSA operations, which make RSA processing considerably faster. However, for implementation reasons, our OpenSSL engine does not use CRT parameters yet.