The performance of RCU is critically dependent on an efficient implementation of the call_rcu() primitive. The more efficient the implementation, the greater the number of situations that RCU may profitably be applied to.
However, grace-period latency is also an important measure of performance - while CPU overhead negates the performance benefits of RCU, excessively long grace-period latencies can result in all available memory queued up waiting for a grace period to end. However, the conditions that cause excessively long grace-period latencies have other bad effects, even in absence of RCU, such as grossly degraded response times.
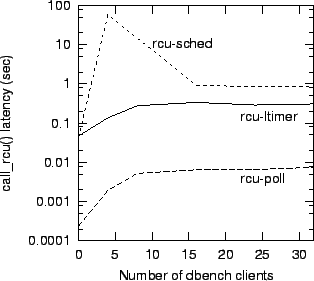
A detailed description of these algorithms has been presented elsewhere [McK02a], but a brief description of each follows. The rcu_poll algorithm uses IPIs to force each CPU to quickly enter a quiescent state, which results in grace periods of much less than a millisecond on idle systems. However, the resulting increased scheduler overhead can outweigh the performance benefits of RCU. The rcu_ltimer algorithm instruments the scheduler_tick() function that is called with HZ frequency on each CPU, resulting in extremely low overhead, but with grace periods in excess of 100 milliseconds. The rcu_sched algorithm uses a token-passing scheme that holds the promise of extremely low overheads (which are currently masked by the cache thrashing of a global counter), but can have grace periods of almost one minute in duration. It is likely that the rcu_sched() algorithm can be reworked to eliminate these disadvantages, which may result in it being the best overall algorithm. However, the rcu_ltimer is the best match for current RCU uses in the Linux kernel, so this algorithm is implemented in the 2.5 Linux kernel.
The best grace-period latencies were obtained using rcu-poll, which invokes resched_task() on each CPU to force context switches, resulting in latencies more than an order of magnitude shorter than those of rcu-ltimer and rcu-sched, as shown in Figure 7. This benchmark was run on an 8-CPU 700MHz Intel Xeon system with 1MB L2 caches and 6GB of memory using the dcache-rcu patch [LSE].
However, rcu-poll's single global callback list results in cache thrashing and high overhead, and it obtains the short grace-period latencies by frequently invoking the scheduler, the combination of which at times overwhelms the performance benefits of RCU. The cache thrashing is caused by: (1) enqueuing onto this single list from multiple CPUs and (2) callbacks running on a CPU other than the one that registered them. This latter effect causes data structures processed by the callback to be pulled from the registering CPU to the CPU running the callback.
A modified rcu-poll algorithm was constructed having per-CPU lists of callbacks. This eliminates both sources of cache thrashing: each CPU manipulates only its own list and callbacks always run on the CPU that registered them. The frequent scheduler invocation remains, as this is required to obtain the excellent call_rcu() latencies.
Table 3 compares the performance of rcu-ltimer (in Linux 2.5 kernel), rcu-sched, and the parallelized version of rcu-poll. These results show that rcu-ltimer completes each iteration slightly (but statistically significantly) more quickly than does rcu-poll, and with 8.6% less CPU utilization. They also show rcu-sched completes each iteration as fast as does rcu-ltimer, but with 5.7% more CPU utilization. This benchmark was run on a 4-CPU PIII Intel Xeon with 1MB L2 cache and 1GB of memory. Profile results show that rcu-poll is incurring significant overhead in the scheduler and in its force_cpu_reschedule() function, indicating that although its cache-thrashing behavior has been addressed, rcu-poll is buying its excellent grace-period latency with significantly increased overhead. The rcu-sched implementation is unchanged; future work includes optimizing it to eliminate cache thrashing and atomic instructions in order to reduce its overhead.
| |||||||||||||||||||||||||
Therefore, unless grace-period latency is of paramount concern, the rcu-ltimer implementation of RCU should be used. Should latency become a critical issue in the future, we will investigate modifications to improve the latency of rcu-ltimer.
An optimized rcu-sched might beat rcu-ltimer's overhead. If this is the case, reduction of grace-period latency would become a considerably more urgent matter.