Applying the same techniques used in devising the Improved Chen's
algorithm, we now try to improve the Double Buffer algorithm. Again, we
divide the reader tasks into fast and slow readers. The fast readers need
a minimum of N buffers to ensure temporal concurrency control, while the
M slow readers use the original Double Buffer scheme. The total message
buffer requirements will now be
![]() buffers, which is less than or equal
to the original algorithm's 2(P + 1) buffers, assuming correct
partitioning of the readers (see Section 3.4). As
before, the highest-frequency readers now use the very low overhead NBW
read mechanism, so execution times should be improved as well.
buffers, which is less than or equal
to the original algorithm's 2(P + 1) buffers, assuming correct
partitioning of the readers (see Section 3.4). As
before, the highest-frequency readers now use the very low overhead NBW
read mechanism, so execution times should be improved as well.
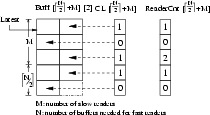
The data structures and algorithm for Improved Double Buffer are shown in
Figures 7 and 8,
respectively. The slow readers are unmodified from the original readers.
Fast readers simply read from the buffer indicated by Latest and
the corresponding row's Cl entry. The writer, too, is mostly
unmodified. To ensure temporal concurrency control for the fast readers,
the writer should not reuse any particular buffer until at least N - 1
subsequent writes have occurred. This is ensured by changing the buffer
selection loop to search starting at row (Latest+1) mod NRows. The
rows are used cyclically, and the buffers within a row alternate on
subsequent writes, so
![]() rows suffice to
ensure temporal concurrency control for the fast readers. Therefore, the
improved algorithm needs
rows suffice to
ensure temporal concurrency control for the fast readers. Therefore, the
improved algorithm needs
![]() buffers.
buffers.
To illustrate overhead improvements, let us consider a system with 20 reader tasks, of which 5 are classified as slow readers. Assume further that based on the NMax calculations (Section 2.2), the fast readers need 7 buffers to ensure temporal isolation from the writer. With Improved Double Buffer, we need 18 message buffer slots, while the original needs 42, a significant memory reduction. Moreover, the other control variables are proportional to the number of rows, so they, too, are reduced. With the new algorithm, the slow readers and the writer remain virtually unchanged, but the fast readers have less computation than the original readers, so the overall execution overheads will decrease as well. Generally, as the number of fast readers increases, the execution performance increases, but this is not necessarily the case for space requirements. In the following section, we will determine how to partition a reader set into fast and slow readers, optimizing for space.