We implemented our new API by modifying Digital UNIX V4.0D. We started with our improved select() implementation [4], reusing some data structures and support functions from that effort. This also allows us to measure our new API against the best known select() implementation without varying anything else. Our current implementation works only for sockets, but could be extended to other descriptor types. (References below to the ``protocol stack'' would then include file system and device driver code.)
For the new API, we added about 650 lines of code. The get_next_event() call required about 320 lines, declare_interest() required 150, and the remainder covers changes to protocol code and support functions. In contrast, our previous modifications to select() added about 1200 lines, of which we reused about 100 lines in implementing the new API.
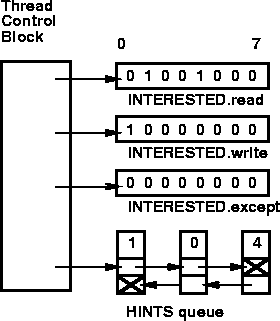
For each application thread, our code maintains four data structures. These include INTERESTED.read, INTERESTED.write, and INTERESTED.except, the sets of descriptors designated via declare_interest() as ``interesting'' for reading, writing, and exceptions, respectively. The other is HINTS, a FIFO queue of events posted by the protocol stack for the thread.
A thread's first call to declare_interest() causes creation of its INTERESTED sets; the sets are resized as necessary when descriptors are added. The HINTS queue is created upon thread creation. All four sets are destroyed when the thread exits. When a descriptor is closed, it is automatically removed from all relevant INTERESTED sets.
Figure 4 shows the kernel data structures for an example in which a thread has declared read interest in descriptors 1 and 4, and write interest in descriptor 0. The three INTERESTED sets are shown here as one-byte bitmaps, because the thread has not declared interest in any higher-numbered descriptors. In this example, the HINTS queue for the thread records three pending events, one each for descriptors 1, 0, and 4.
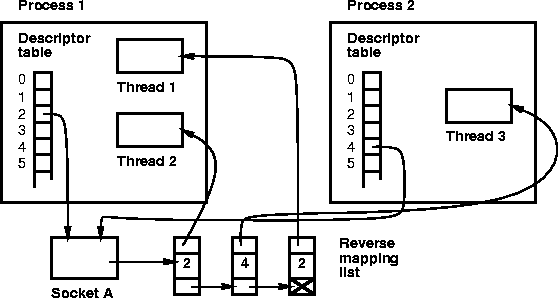
A call to declare_interest() also adds an element to the corresponding socket's ``reverse-mapping'' list; this element includes both a pointer to the thread and the descriptor's index number. Figure 5 shows the kernel data structures for an example in which Process 1 and Process 2 hold references to Socket A via file descriptors 2 and 4, respectively. Two threads of Process 1 and one thread of Process 2 are interested in Socket A, so the reverse-mapping list associated with the socket has pointers to all three threads.
When the protocol code processes an event (such as data arrival) for a socket, it checks the reverse-mapping list. For each thread on the list, if the index number is found in the thread's relevant INTERESTED set, then a notification element is added to the thread's HINTS queue.
To avoid the overhead of adding and deleting the reverse-mapping lists too often, we never remove a reverse-mapping item until the descriptor is closed. This means that the list is updated at most once per descriptor lifetime. It does add some slight per-event overhead for a socket while a thread has revoked its interest in that descriptor; we believe this is negligible.
We attempt to coalesce multiple event notifications for a single descriptor. We use another per-thread bitmap, indexed by file descriptor number, to note that the HINTS queue contains a pending element for the descriptor. The protocol code tests and sets these bitmap entries; they are cleared once get_next_event() has delivered the corresponding notification. Thus, N events on a socket between calls to get_next_event() lead to just one notification.
Each call to get_next_event(), unless it times out, dequeues one or more notification elements from the HINTS queue in FIFO order. However, the HINTS queue has a size limit; if it overflows, we discard it and deliver events in descriptor order, using a linear search of the INTERESTED sets - we would rather deliver things in the wrong order than block progress. This policy could lead to starvation, if the array_max parameter to get_next_event() is less than the number of descriptors, and may need revision.
We note that there are other possible implementations for the new API. For example, one of the anonymous reviewers suggested using a linked list for the per-thread queue of pending events, reserving space for one list element in each socket data structure. This approach seems to have several advantages when the SO_WAKEUP_ONE option is set, but might not be feasible when each event is delivered to multiple threads.