An application must often manage large numbers of file descriptors, representing network connections, disk files, and other devices. Inherent in the use of a file descriptor is the possibility of delay. A thread that invokes a blocking I/O call on one file descriptor, such as the UNIX read() or write() systems calls, risks ignoring all of its other descriptors while it is blocked waiting for data (or for output buffer space).
UNIX supports non-blocking operation for read() and write(), but a naive use of this mechanism, in which the application polls each file descriptor to see if it might be usable, leads to excessive overheads.
Alternatively, one might allocate a single thread to each activity, allowing one activity to block on I/O without affecting the progress of others. Experience with UNIX and similar systems has shown that this scales badly as the number of threads increases, because of the costs of thread scheduling, context-switching, and thread-state storage space[6,9]. The use of a single process per connection is even more costly.
The most efficient approach is therefore to allocate a moderate number of threads, corresponding to the amount of available parallelism (for example, one per CPU), and to use non-blocking I/O in conjunction with an efficient mechanism for deciding which descriptors are ready for processing[17]. We focus on the design of this mechanism, and in particular on its efficiency as the number of file descriptors grows very large.
Early computer applications seldom managed many file descriptors. UNIX, for example, originally supported at most 15 descriptors per process[14]. However, the growth of large client-server applications such as database servers, and especially Internet servers, has led to much larger descriptor sets.
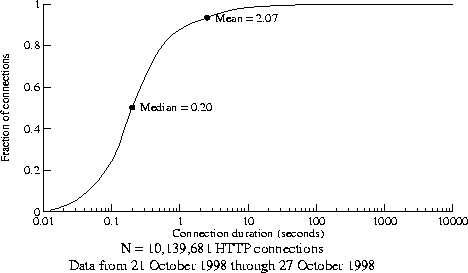
Consider, for example, a Web server on the Internet. Typical HTTP mean connection durations have been measured in the range of 2-4 seconds[8,13]; Figure 1 shows the distribution of HTTP connection durations measured at one of Compaq's firewall proxy servers. Internet connections last so long because of long round-trip times (RTTs), frequent packet loss, and often because of slow (modem-speed) links used for downloading large images or binaries. On the other hand, modern single-CPU servers can handle about 3000 HTTP requests per second[19], and multiprocessors considerably more (albeit in carefully controlled environments). Queueing theory shows that an Internet Web server handling 3000 connections per second, with a mean duration of 2 seconds, will have about 6000 open connections to manage at once (assuming constant interarrival time).
In a previous paper[4], we showed that the BSD UNIX event-notification mechanism, the select() system call, scales poorly with increasing connection count. We showed that large connection counts do indeed occur in actual servers, and that the traditional implementation of select() could be improved significantly. However, we also found that even our improved select() implementation accounts for an unacceptably large share of the overall CPU time. This implies that, no matter how carefully it is implemented, select() scales poorly. (Some UNIX systems use a different system call, poll(), but we believe that this call has scaling properties at least as bad as those of select(), if not worse.)
The key problem with the select() interface is that it requires the application to inform the kernel, on each call, of the entire set of ``interesting'' file descriptors: i.e., those for which the application wants to check readiness. For each event, this causes effort and data motion proportional to the number of interesting file descriptors. Since the number of file descriptors is normally proportional to the event rate, the total cost of select() activity scales roughly with the square of the event rate.
In this paper, we explain the distinction between state-based mechanisms, such as select(), which check the current status of numerous descriptors, and event-based mechanisms, which deliver explicit event notifications. We present a new UNIX event-based API (application programming interface) that an application may use, instead of select(), to wait for events on file descriptors. The API allows an application to register its interest in a file descriptor once (rather than every time it waits for events). When an event occurs on one of these interesting file descriptors, the kernel places a notification on a queue, and the API allows the application to efficiently dequeue event notifications.
We will show that this new interface is simple, easily implemented, and performs independently of the number of file descriptors. For example, with 2000 connections, our API improves maximum throughput by 28%.