
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Security '03 Paper
[Security '03 Technical Program]
Denial of Service via Algorithmic Complexity Attacks
Abstract:
We present a new class of low-bandwidth denial of service attacks that
exploit algorithmic deficiencies in many common applications' data
structures. Frequently used data structures have ``average-case''
expected running time that's far more efficient than the worst case.
For example, both binary trees and hash tables can degenerate to
linked lists with carefully chosen input. We show how an attacker can
effectively compute such input, and we demonstrate attacks against the
hash table implementations in two versions of Perl, the Squid web
proxy, and the Bro intrusion detection system. Using bandwidth less
than a typical dialup modem, we can bring a dedicated Bro server to
its knees; after six minutes of carefully chosen packets, our Bro
server was dropping as much as 71% of its traffic and consuming all
of its CPU. We show how modern universal hashing techniques can yield
performance comparable to commonplace hash functions while being
provably secure against these attacks.
Introduction
When analyzing the running time of algorithms, a common technique is
to differentiate best-case, common-case, and worst-cast performance.
For example, an unbalanced binary tree will be expected to consume
While balanced tree algorithms, such as red-black trees [11], AVL trees [1], and treaps [17] can avoid predictable input which causes worst-case behavior, and universal hash functions [5] can be used to make hash functions that are not predictable by an attacker, many common applications use simpler algorithms. If an attacker can control and predict the inputs being used by these algorithms, then the attacker may be able to induce the worst-case execution time, effectively causing a denial-of-service (DoS) attack. Such algorithmic DoS attacks have much in common with other low-bandwidth DoS attacks, such as stack smashing [2] or the ping-of-death 1, wherein a relatively short message causes an Internet server to crash or misbehave. While a variety of techniques can be used to address these DoS attacks, common industrial practice still allows bugs like these to appear in commercial products. However, unlike stack smashing, attacks that target poorly chosen algorithms can function even against code written in safe languages. One early example was discovered by Garfinkel [10], who described nested HTML tables that induced the browser to perform super-linear work to derive the table's on-screen layout. More recently, Stubblefield and Dean [8] described attacks against SSL servers, where a malicious web client can coerce a web server into performing expensive RSA decryption operations. They suggested the use of crypto puzzles [9] to force clients to perform more work before the server does its work. Provably requiring the client to consume CPU time may make sense for fundamentally expensive operations like RSA decryption, but it seems out of place when the expensive operation (e.g., HTML table layout) is only expensive because a poor algorithm was used in the system. Another recent paper [16] is a toolkit that allows programmers to inject sensors and actuators into a program. When a resource abuse is detected an appropriate action is taken. This paper focuses on DoS attacks that may be mounted from across a network, targeting servers with the data that they might observe and store in a hash table as part of their normal operation. Section 2 details how hash tables work and how they can be vulnerable to malicious attacks. Section 3 describes vulnerabilities in the Squid web cache, the DJB DNS server, and Perl's built-in hash tables. Section 4 describes vulnerabilities in the Bro intrusion detection system. Section 5 presents some possible solutions to our attack. Finally, Section 6 gives our conclusions and discusses future work.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Bro [15] is a general-purpose network intrusion detection system (IDS) that can be configured to scan for a wide variety of possible attacks. Bro is open-source and is used in production at a number of commercial and academic sites. This makes it an attractive target, particularly because we can directly study its source code. Also, given that Bro's job is to scan and record network packets, correlating events in real time to detect attacks, we imagine it has numerous large hash tables with which it tracks these events. If we could peg Bro's CPU usage, we potentially knock the IDS off the air, clearing the way for other attacks to go undetected.
In order to keep up with traffic, Bro uses packet filters [13] to select and capture desired packets, as a function of its configuration. Following this, Bro implements an event-based architecture. New packets raise events to be processed. Synthetic events can also be timed to occur in the future, for example, to track the various time-outs that occur in the TCP/IP protocol. A number of Bro modules exist to process specific protocols, such as FTP, DNS, SMTP, Finger, HTTP, and NTP.
Bro contains approximately 67,000 lines of C++ code that implement low-level mechanisms to observe network traffic and generate events. Bro also provides a wide selection of scripts, comprising approximately 9000 lines of code in its own interpreted language that use the low-level mechanisms to observe network behavior and react appropriately. While we have not exhaustively studied the source code to Bro, we did observe that Bro uses a simple hash table whose hash function simply XORs together its inputs. This makes collisions exceptionally straightforward to derive. The remaining issue for an attack any is to determine how and when incoming network packets are manipulated before hash table entries are generated.
We decided to focus our efforts on Bro's port scanning detector,
primarily due to its simplicity. For each source IP address, Bro
needs to track how many distinct destination ports have been
contacted. It uses a hash table to track, for each tuple of ![]() source
IP address, destination port
source
IP address, destination port![]() , whether any internal machine has been
probed on a given port from that particular source address. To attack
this hash table, we observe that the attacker has 48-bits of freedom:
a 32-bit source IP address and a 16-bit destination port number.
(We're now assuming the attacker has the freedom to forge arbitrary
source IP addresses.) If our goal is to compute 32-bit hash
collisions (i.e., before the modulo operation to determine the hash
bucket), then for any good hash function, we would expect there to be
approximately
, whether any internal machine has been
probed on a given port from that particular source address. To attack
this hash table, we observe that the attacker has 48-bits of freedom:
a 32-bit source IP address and a 16-bit destination port number.
(We're now assuming the attacker has the freedom to forge arbitrary
source IP addresses.) If our goal is to compute 32-bit hash
collisions (i.e., before the modulo operation to determine the hash
bucket), then for any good hash function, we would expect there to be
approximately ![]() possible collisions we might be able to find
for any given 32-bit hash value. In a hypothetical IPv6 implementation
of Bro, there would be significantly more possible collisions, given
the larger space of source IP addresses.
possible collisions we might be able to find
for any given 32-bit hash value. In a hypothetical IPv6 implementation
of Bro, there would be significantly more possible collisions, given
the larger space of source IP addresses.
Deriving these collisions with Bro's XOR-based hash function requires
understanding the precise way that Bro implements its hash function.
In this case, the hash function is the source IP address, in network
byte order, XORed with the destination port number, in host order.
This means that on a little-endian computer, such as an x86
architecture CPU, the high-order 16 bits of the hash value are taken
straight from the last two octets of the IP address, while the
low-order 16 bits of the hash value result from the first two octets
of the IP address and the port number. Hash collisions can be derived
by flipping bits in the first two octets of the IP address in concert
with the matching bits of the port number. This allows us, for every
32-bit target hash value, to derive precisely ![]() input packets
that will hash to the same value.
input packets
that will hash to the same value.
We could also have attempted to derive bucket collisions directly,
which would allow us to derive more than ![]() collisions in a
single hash bucket. While we could guess the bucket count, or even
generate parallel streams designed to collide in a number of different
bucket counts as discussed in Section 2.1.1, this
would require sending a significant amount of additional traffic to
the Bro server. If the
collisions in a
single hash bucket. While we could guess the bucket count, or even
generate parallel streams designed to collide in a number of different
bucket counts as discussed in Section 2.1.1, this
would require sending a significant amount of additional traffic to
the Bro server. If the ![]() hash collisions are sufficient to
cause an noticable quadratic explosion inside Bro, then this would be
the preferable attack.
hash collisions are sufficient to
cause an noticable quadratic explosion inside Bro, then this would be
the preferable attack.
We have designed attack traffic that can make Bro saturate the CPU and begin to drop traffic within 30 seconds during a 160kb/s, 500 packets/second flood, and within 7 minutes with a 16kb/s flood.
Our experiments were run over an idle Ethernet, with a laptop computer transmitting the packets to a Bro server, version 0.8a20, running on a dual-CPU Pentium-2 machine, running at 450MHz, with 768MB of RAM, and running the Linux 2.4.18 kernel. Bro only uses a single thread, allowing other processes to use the second CPU. For our experiments, we configured Bro exclusively to track port scanning activity. In a production Bro server, where it might be tracking many different forms of network misbehavior, the memory and CPU consumption would be strictly higher than we observed in our experiments.
We first present the performance of Bro, operating in an off-line mode, consuming packets only as fast as it can process them. We then present the latency and drop-rate of Bro, operating online, digesting packets at a variety of different bandwidths.
|
Normally, on this hardware, Bro can digest about 1200 SYN packets per second. We note that this is only 400kb/s, so Bro would already be vulnerable to a simple flood of arbitrary SYN packets. We also note that Bro appears to use about 500 bytes of memory per packet when subject to random SYN packets. At a rate of 400kb/s, our Bro system, even if it had 4GB of RAM, would run out of memory within two hours.
We have measured the offline running time for Bro to consume 64k randomly chosen SYN packets. We then measured the time for Bro to consume the same 64k randomly chosen packets, to warm up the hash table, followed by 64k attack packets. This minimizes rehashing activity during the attack packets and more closely simulates the load that Bro might observe had it been running for a long time and experienced a sudden burst of attack packets. The CPU times given in Table 2 present the results of benchmarking Bro under this attack. The results show that the attack packets introduce two orders of magnitude of overhead to Bro, overall, and three orders of magnitude of overhead specifically in Bro's hash table code. Under this attack, Bro can only process 24 packets per second instead of its normal rate of 1200 packets per second.
In the event that Bro was used to process an extended amount of data, perhaps captured for later offline analysis, then an hour of very low bandwidth attack traffic (16kb/s, 144k packets, 5.8Mbytes of traffic) would take Bro 1.6 hours to analyze instead of 3 minutes. An hour of T1-level traffic (1.5Mb/s) would take a week instead of 5 hours, assuming that Bro didn't first run out of memory.
| ||||||||||||||||||||
As described above, our attack packets cannot be processed by Bro in
real-time, even with very modest transmission rates. For offline
analysis, this simply means that Bro will take a while to execute.
For online analysis, it means that Bro will fall behind. The kernel's
packet queues will fill because Bro isn't reading the data, and
eventually the kernel will start dropping the packets. To measure
this, we constructed several different attack scenarios. In all
cases, we warmed up Bro's hash table with approximately 130k random
SYN packets. We then transmitted the attack packets at any one of
three different bandwidths (16kb/s, 64kb/s, and 160kb/s). We
constructed attacks that transmitted all ![]() attack packets
sequentially, multiple times. We also constructed a ``clever'' attack
scenario, where we first sent
attack packets
sequentially, multiple times. We also constructed a ``clever'' attack
scenario, where we first sent ![]() of our attack packets and then
repeated the remaining
of our attack packets and then
repeated the remaining ![]() of the packets. The clever attack forces
more of the chain to be scanned before the hash table discovered the
new value is already present in the hash chain.
of the packets. The clever attack forces
more of the chain to be scanned before the hash table discovered the
new value is already present in the hash chain.
Table 3 shows the approximate drop rates for four attack scenarios. We observe that an attacker with even a fraction of a modem's bandwidth, transmitting for less than an hour, can cause Bro to drop, on average, 71% of its incoming traffic. This would make an excellent precursor to another network attack that the perpetrator did not wish to be detected.
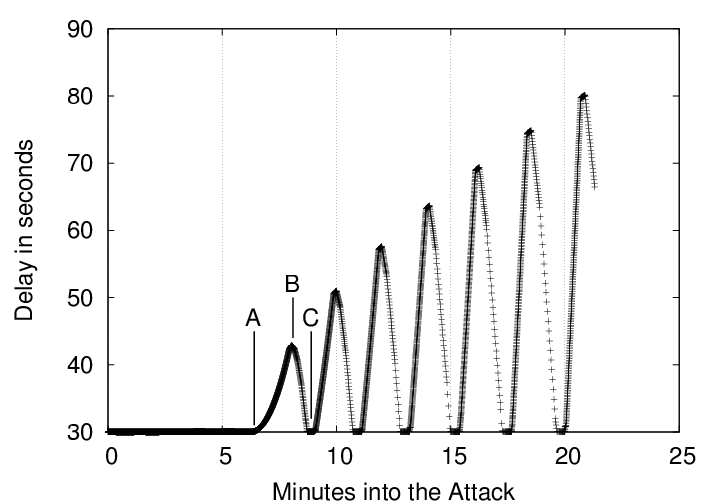
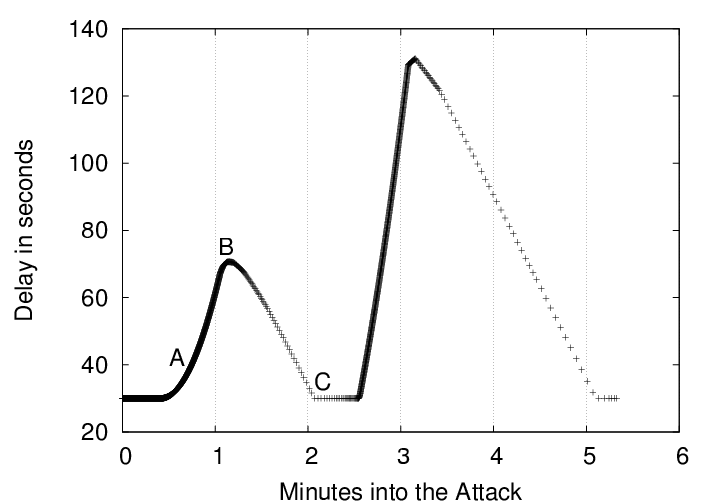
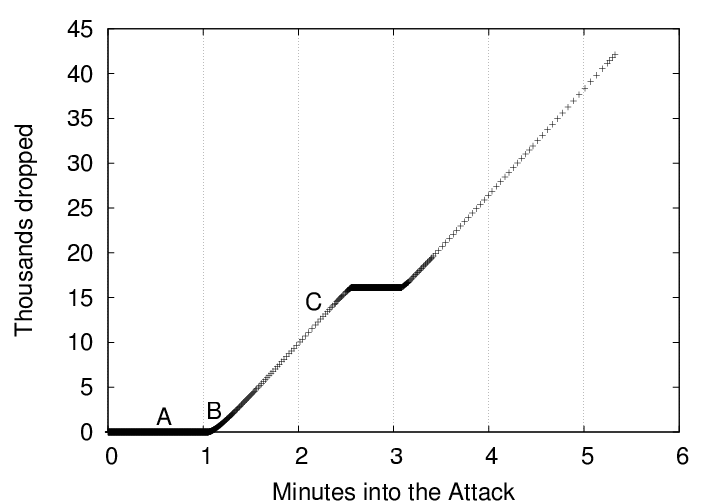
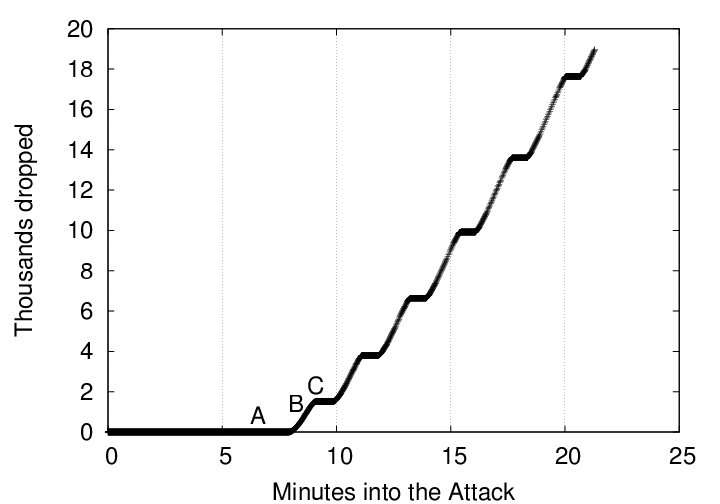
Bro's drop rate is not constant. In fact, Bro manifests interesting oscillations in its drop rate, which are visible in Figures 3 through 6. These graphs present Bro's packet processing latency and cumulative packet drop rate for attack packets being transmitted at 16 kb/sec and 64 kb/sec.
At time ![]() , the latency (time between packet arrival and
packet processing) starts increasing as total processing cost per packet
begins to exceed the packet inter-arrival time.
, the latency (time between packet arrival and
packet processing) starts increasing as total processing cost per packet
begins to exceed the packet inter-arrival time.
At time ![]() , Bro is sufficiently back-logged that the kernel has begun
to drop packets. As a result, Bro starts catching up on its
backlogged packets. During this phase, the Bro server is dropping
virtually all of its incoming traffic.
, Bro is sufficiently back-logged that the kernel has begun
to drop packets. As a result, Bro starts catching up on its
backlogged packets. During this phase, the Bro server is dropping
virtually all of its incoming traffic.
At time ![]() , Bro has caught up on its backlog, and the kernel is no
longer dropping packets. The cycle can now start again. However,
the hash chain under attack is now larger then it was at time
, Bro has caught up on its backlog, and the kernel is no
longer dropping packets. The cycle can now start again. However,
the hash chain under attack is now larger then it was at time ![]() .
This will cause subsequent latencies to rise even higher than they
were at time
.
This will cause subsequent latencies to rise even higher than they
were at time ![]() .
.
This cyclic behavior occurs because Bro only adds entries to this hash table after it has determined there will be no response to the SYN packet. Bro normally uses a five minute timeout. We reduced this to 30 seconds to reduce our testing time and make it easier to illustrate our attacks. We anticipate that, if we were to run with the default 5-minute timeout, the latency swings would have a longer period and a greater amplitude, do to the ten times larger queues of unprocessed events which would be accumulated.
Our attack on Bro has focused on its port scanning detector. Bro and
other IDS systems almost certainly have other hash tables which may
grow large enough to be vulnerable to algorithmic complexity attacks.
For example, Bro has a module to detect network scans, determining how
many destination hosts have been sent packets by a given source host.
This module gives ![]() bits of freedom, where
bits of freedom, where ![]() is the number of
host bits in the destination network monitored by the IDS.
is the number of
host bits in the destination network monitored by the IDS. ![]() is unlikely
to be greater than 16 except for a handful of sites. However, in an
IPv6 network, the sky is the limit. For that matter, IPv6 gives the
attacker a huge amount of freedom for any attack where IP addresses
are part of the values being hashed.
is unlikely
to be greater than 16 except for a handful of sites. However, in an
IPv6 network, the sky is the limit. For that matter, IPv6 gives the
attacker a huge amount of freedom for any attack where IP addresses
are part of the values being hashed.
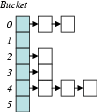
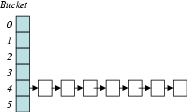
Part of any hash table design is the need to expand the bucket count
when the table occupancy exceeds some threshold. When the hash table
has a large number of objects which hash to the same bucket after the
rehashing operation, then the rehashing operation could be as bad as
![]() , if the hash table were using its normal insertion operation
that checks for duplicates. As it turns out, Bro does exactly this.
In our regular experimental runs, we ``warmed up'' the hash tables to
prevent any rehashing during the experiment. Before we changed
our experimental setup to do this, we saw large spikes in our latency
measurements that indicated rehashing was occurring. When rehashing,
Bro takes 4 minutes to process a table with 32k attack entries. Bro
takes 20 minutes to process a table with 64k attack entries. Without
IPv6 or using bucket collisions, we cannot create more collisions than
this, although making the IDS server unresponsive for 20 minutes is
certainly an effective attack.
, if the hash table were using its normal insertion operation
that checks for duplicates. As it turns out, Bro does exactly this.
In our regular experimental runs, we ``warmed up'' the hash tables to
prevent any rehashing during the experiment. Before we changed
our experimental setup to do this, we saw large spikes in our latency
measurements that indicated rehashing was occurring. When rehashing,
Bro takes 4 minutes to process a table with 32k attack entries. Bro
takes 20 minutes to process a table with 64k attack entries. Without
IPv6 or using bucket collisions, we cannot create more collisions than
this, although making the IDS server unresponsive for 20 minutes is
certainly an effective attack.
Although rehashing attacks are extremely potent, they are not necessarily easy to use; attackers cannot exploit this window of opportunity unless they know exactly when it is occurring. Furthermore, Bro's hash table will rehash itself at most 12 times as it grows from 32k entries to 64M entries.
When analyzing algorithmic complexity attacks, we must assume the attacker has access to the source code of the application, so security through obscurity is not acceptable. Instead, either the application must use algorithms that do not have predictable worst-case inputs, or the application must be able to detect when it is experiencing worst-case behavior and take corrective action.
A complete survey of algorithms used in common systems is beyond the scope of this paper. We focus our attention on binary trees and on hash tables.
While binary trees are trivial for an attacker to generate worst-case input, many many other data structures like red-black trees [11] and splay trees [18] have runtime bounds that are guaranteed, regardless of their input. A weaker but sufficient condition is to use an algorithm that does not have predictable worst-case inputs. For example, treaps [17] are trees where all nodes are assigned a randomly chosen number upon creation. The tree nodes are rotated such that a tree property is preserved on the input data, as would be expected of any tree, but a heap property is also maintained on the random numbers, yielding a tree that is probabilistically balanced. So long as the program is designed to prevent the attacker from predicting the random numbers (i.e., the pseudo-random number generator is ``secure'' and is properly initialized), the attacker cannot determine what inputs would cause the treap to exhibit worst-case behavior.
When attacking hash tables, an attacker's goal is to efficiently compute second pre-images to the hash function, i.e., if ![]() hashes to
hashes to ![]() and
and ![]() , it should be infeasible for the attacker to derive
, it should be infeasible for the attacker to derive ![]() such that
such that ![]() . Cryptographically strong hash functions like MD5
and SHA-1 are resistant, in general, to such attacks. However, when
used in hash tables, the 128 or 160 bits of output from MD5 or SHA-1
must eventually be reduced to the bucket count, making it
feasible for an attacker to mount a brute force search on the hash
function to find bucket collisions. Some simple benchmarking on a
450MHz Pentium-2 allowed us to compute approximately five such
collisions per second in a hash table with 512k buckets. This
weakness can be addressed by using keyed versions of MD5 or SHA-1
(e.g., HMAC [12]). The key, chosen randomly when the
program is initialized, will not be predictable by an attacker; as a
result, the attacker will not be able to predict the hash values used
when the program is actually running. When keyed, MD5 and SHA-1
become pseudo-random functions, which, like treaps, become
unpredictable for the attacker. When unkeyed, MD5 and SHA-1 are
deterministic functions and subject to bucket collisions.
. Cryptographically strong hash functions like MD5
and SHA-1 are resistant, in general, to such attacks. However, when
used in hash tables, the 128 or 160 bits of output from MD5 or SHA-1
must eventually be reduced to the bucket count, making it
feasible for an attacker to mount a brute force search on the hash
function to find bucket collisions. Some simple benchmarking on a
450MHz Pentium-2 allowed us to compute approximately five such
collisions per second in a hash table with 512k buckets. This
weakness can be addressed by using keyed versions of MD5 or SHA-1
(e.g., HMAC [12]). The key, chosen randomly when the
program is initialized, will not be predictable by an attacker; as a
result, the attacker will not be able to predict the hash values used
when the program is actually running. When keyed, MD5 and SHA-1
become pseudo-random functions, which, like treaps, become
unpredictable for the attacker. When unkeyed, MD5 and SHA-1 are
deterministic functions and subject to bucket collisions.
Replacing deterministic hash functions with pseudo-random functions gives probabilistic guarantees of security. However, a stronger solution, which can also execute more efficiently, is available. Universal hash functions were introduced in 1979 [5] and are cited by common algorithm textbooks (e.g., Cormen, Leiserson, and Rivest [6]) as a solution suitable for adversarial environments. It has not been standard practice to follow this advice, but it should be.
Where MD5 and SHA-1 are designed to be resistant to the computation of
second pre-images, universal hash functions are families of functions
(with the specific function specified by a key) with the property
that, for any two arbitrary messages ![]() and
and ![]() , the odds of
, the odds of ![]() are less than some small value
are less than some small value ![]() . This property is
sufficient for our needs, because an attacker who does not know the
specific hash function has guaranteed low odds of computing hash
collisions.
. This property is
sufficient for our needs, because an attacker who does not know the
specific hash function has guaranteed low odds of computing hash
collisions.
Carter and Wegman's original construction of a universal hash function computes the sum of a fixed chosen constant with the dot product of a fixed chosen vector with the input, modulo a large prime number. The fixed chosen constant and vectors are chosen, randomly, at the beginning, typically pre-computed using a keyed pseudo-random function, and reused for every string being hashed. The only performance issue is that this vector must either be pre-computed up to the maximum expected input length, or it must be recomputed when it is used, causing a noticeable performance penalty. More recent constructions, including UMAC [4] and hash127 [3] use a fixed space despite supporting arbitrary-length arguments. UMAC, in particular, is carefully engineered to run fast on modern processors, using adds, multiplies, and SIMD multimedia instructions for increased performance.
Some software designers are unwilling to use universal hashing, afraid that it will introduce unacceptable performance overheads in critical regions of their code. Other software designers simply need a fast, easy-to-integrate library to solve their hashing needs. Borrowing code from UMAC and adding variants hand-optimized for small, fixed-length inputs, we have implemented a portable C library suitable for virtually any program's needs.
Our library includes two different universal hash functions: the UHASH function, submitted as part of the (currently expired) UMAC Internet draft standard [4], and the Carter-Wegman dot-product construction. We also include a hand-tuned variant of the Carter-Wegman construction, optimized to support fixed-length, short inputs, as well as an additionally tuned version that only yields a 20 bit result, rather than the usual 32 bits. This may be appropriate for smaller hash tables, such as used in Squid (see Section 3.1).
Our Carter-Wegman construction processes the value to be hashed one
byte at a time. These bytes are multiplied by 32 bits from the fixed
vector, yielding 40 bit intermediate values that are accumulated in a
64 bit counter. One 64-by-32 bit modulo operation is used at the end
to yield the 32 bit hash value. This construction supports inputs of
length up to ![]() bytes. (A maximum length is declared by the
programmer when a hashing context is allocated, causing the fixed
vector to be initialized by AES in counter mode, keyed from
/dev/random. Hash inputs longer than this are rejected.)
bytes. (A maximum length is declared by the
programmer when a hashing context is allocated, causing the fixed
vector to be initialized by AES in counter mode, keyed from
/dev/random. Hash inputs longer than this are rejected.)
Our initial tests showed that UHASH significantly outperformed the
Carter-Wegman construction for long inputs, but Carter-Wegman worked
well for short inputs. Since many software applications of hash
functions know, apriori, that their inputs are small and of fixed
length (e.g., in-kernel network stacks that hash portions of IP
headers), we wished to provide carefully tuned functions to make such
hashing faster. By fixing the length of the input, we could fully
unroll the internal loop and avoid any function calls. GCC inlines
our hand-tuned function. Furthermore, the Carter-Wegman construction
can be implemented with a smaller accumulator. Without changing the
mathematics of Carter-Wegman, we can multiply 8 bit values with 20 bit
entries in the fixed vector and use a 32 bit accumulator. For inputs
less than ![]() -bytes, the accumulator will not overflow, and we get
a 20 bit hash value as a result. The inputs are passed as separate
formal arguments, rather than in an array. This gives the compiler
ample opportunity for inlining and specializing the function.
-bytes, the accumulator will not overflow, and we get
a 20 bit hash value as a result. The inputs are passed as separate
formal arguments, rather than in an array. This gives the compiler
ample opportunity for inlining and specializing the function.
We performed our microbenchmarking on a Pentium 2, 450MHz computer. Because hash tables tend to use a large amount of data, but only read it once, working set size and its resultant impact on cache miss rates cannot be ignored. Our microbenchmark is designed to let us measure the effects of hitting or missing in the cache. We pick an array size, then fill it with random data. We then hash a random sub-range of it. Depending on the array size chosen and whether it fits in the L1 cache, L2 cache, or not, the performance can vary significantly.
In our tests, the we microbenchmarked two conventional algorithms, four universal hashing algorithms, and one cryptographic hash algorithm:
| Perl | Perl 5.8.0 hash function |
| MD5 | cryptographic hash function |
| UHASH | UMAC universal hash function |
| CW | Carter-Wegman, one byte processing, variable-length input, 64 bit accumulator, 32 bit output |
| CW12 | Carter-Wegman, two byte processing, 12-byte fixed input, 64 bit accumulator, 32 bit output |
| CW12-20 | Carter-Wegman, one byte processing, 12-byte fixed input, 32 bit accumulator, 20 bit output |
| XOR12 | four byte processing, 12-byte fixed input, 32 bit output |
In addition to Perl, MD5, UHASH, and three variants of the Carter-Wegman construction, we also include a specialized function that simply XORs its input together, four bytes at a time. This simulates the sort of hash function used by many performance-paranoid systems.
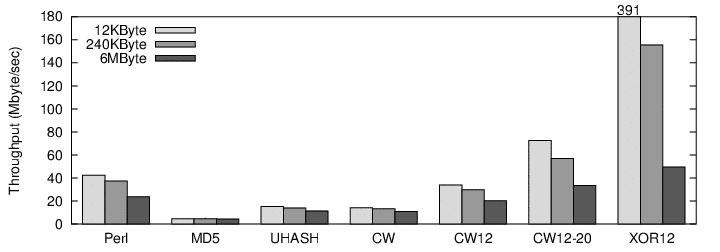
Figure 7 shows the effects of changing the working set size on hash performance. All the hash functions are shown hashing 12-byte inputs, chosen from an array whose sizes have been chosen to fit within the L1 cache, within the L2 cache, and to miss both caches. The largest size simulates the effect that will be seen when the data being hashed is freshly read from a network buffer or has otherwise not yet been processed. We believe this most accurately represents the caching throughput that will be observed in practice, as hash values are typically only computed once, and then written into an object's internal field, somewhere, for later comparison.
As one would expect, the simplistic XOR12 hash function radically outperforms its rivals, but the ratio shrinks as the working set size increases. With a 6MB working set, XOR12's throughput is 50 MB/sec, whereas CW12-20 is 33 MB/sec. This relatively modest difference says that universal hashing, with its strong security guarantees, can approach the performance of even the weakest hash functions. We can also see that universal hashing is competitive with Perl's hash function and radically outperforms MD5.
As the cache hit rate increases with a smaller working set, XOR12 radically outperforms its competition. We argue that this case is unlikely to occur in practice, as the data being hashed is likely to incur cache misses while it's being read from the network hardware into main memory and then the CPU. Secondly, we are microbenchmarking hash function performance, a hash function is only a percentage of overall hash table runtime which is only a percentage of application runtime. Of course, individual application designers will need to try universal hashing out to see how it impacts their own systems.
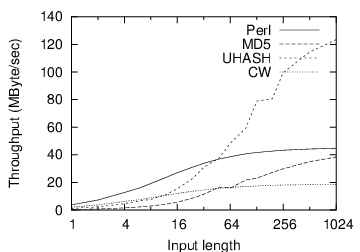
Some applications hash longer strings and require general-purpose hash functions. Figure 8 uses the 6MB working set and varies the length of the input to be hashed. We can no longer use the specialized 12-byte functions, but the other functions are shown. (We did not implement a generalization of our XOR12 hash function, although such a function would be expected to beat the other hash functions in the graph.) With short strings, we see the Perl hash function outperforms its peers. However, with strings longer than around 44-bytes, UHASH dominates all the other hash functions, due in no small part to its extensive performance tuning and hand-coded assembly routines.
We have some preliminary benchmarks with integrating universal hashing into Perl. We benchmarked the change with two perl scripts, both of which do little other than hash table operations. The first script is a histogramming program, the second just inserts text into a hash table. Our results indicate that the application performance difference between UHASH and Perl's default hash function is plus or minus 10%.
We conclude that our customized Carter-Wegman construction, for short fixed-length strings, and UHASH, for arbitrary strings, are sufficiently high performance that there is no excuse for them not to be used, or at least benchmarked, in production systems. Our code is available online with a BSD-style license2.
We have presented algorithmic complexity attacks, a new class of low-bandwidth denial of service attacks. Where traditional DoS attacks focus on small implementation bugs, such as buffer overflows, these attacks focus on inefficiencies in the worst-case performance of algorithms used in many mainstream applications. We have analyzed a variety of common applications, finding weaknesses which vary from increasing an applications workload by a small constant factor to causing the application to completely collapse under the load cause by its algorithm's unexpectedly bad behavior.
Algorithmic complexity attacks against hash table, in particular, count on the attacker having sufficient freedom over the space of possible inputs to find a sufficient number of hash collisions to induce worst-case behavior in an application's hash table. When the targeted system is processing network packets, the limited address space of IPv4 offers some limited protection against these attacks, but future IPv6 systems will greatly expand an attacker's ability to find collisions. As such, we strongly recommend that network packet processing code be audited for these vulnerabilities.
Common applications often choose algorithms based on their common-case behavior, expecting the worst-case to never occur in practice. This paper shows that such design choices introduce vulnerabilities that can and should be patched by using more robust algorithms. We showed how universal hashing demonstrates impressive performance, suitable for use in virtually any application.
While this paper has focused on a handful of software systems, an interesting area for future research will be to study the algorithms used by embedded systems, such as routers, firewalls, and other networking devices. For example, many ``stateful'' firewalls likely use simple data structures to store this state. Anyone who can learn the firewall's algorithms may be able to mount DoS attacks against those systems.
This work is supported by NSF Grant CCR-9985332 and Texas ATP grant #03604-0053-2001 and by gifts from Microsoft and Schlumberger.
This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.48)
|
This paper was originally published in the
Proceedings of the 12th USENIX Security Symposium,
August 4–8, 2003,
Washington, DC, USA
Last changed: 27 Aug. 2003 aw |
|
{kind=link}