
mybluergb0.8,0.85,1 shadowrgb0.8,0.8,0.8
Cristian Cadar, Daniel Dunbar, Dawson Engler
1
Stanford University
We also used KLEE as a bug finding tool, applying it to 452 applications (over 430K total lines of code), where it found 56 serious bugs, including three in COREUTILS that had been missed for over 15 years. Finally, we used KLEE to crosscheck purportedly identical BUSYBOX and COREUTILS utilities, finding functional correctness errors and a myriad of inconsistencies.
Many classes of errors, such as functional correctness bugs, are difficult to find without executing a piece of code. The importance of such testing -- combined with the difficulty and poor performance of random and manual approaches -- has led to much recent work in using symbolic execution to automatically generate test inputs [15,26,16,36,24,27,11,21,20,14,22]. At a high-level, these tools use variations on the following idea: Instead of running code on manually- or randomly-constructed input, they run it on symbolic input initially allowed to be ``anything.'' They substitute program inputs with symbolic values and replace corresponding concrete program operations with ones that manipulate symbolic values. When program execution branches based on a symbolic value, the system (conceptually) follows both branches, on each path maintaining a set of constraints called the path condition which must hold on execution of that path. When a path terminates or hits a bug, a test case can be generated by solving the current path condition for concrete values. Assuming deterministic code, feeding this concrete input to a raw, unmodified version of the checked code will make it follow the same path and hit the same bug.
Results are promising. However, while researchers have shown such tools can sometimes get good coverage and find bugs on a small number of programs, it has been an open question whether the approach has any hope of consistently achieving high coverage on real applications. Two common concerns are (1) the exponential number of paths through code and (2) the challenges in handling code that interacts with its surrounding environment, such as the operating system, the network, or the user (colloquially: ``the environment problem''). Neither concern has been much helped by the fact that most past work, including ours, has usually reported results on a limited set of hand-picked benchmarks and typically has not included any coverage numbers.
This paper makes two contributions. First, we present a new symbolic execution tool, KLEE, which we designed for robust, deep checking of a broad range of applications, leveraging several years of lessons from our previous tool, EXE [16]. KLEE employs a variety of constraint solving optimizations, represents program states compactly, and uses search heuristics to get high code coverage. Additionally, it uses a simple and straightforward approach to dealing with the external environment. These features improve KLEE's performance by over an order of magnitude and let it check a broad range of system-intensive programs ``out of the box.''
Second, we show that KLEE's automatically-generated tests get high coverage on a diverse set of real, complicated, and environmentally-intensive programs. Our most in-depth evaluation applies KLEE to all 89 programs 2 in the latest stable version of GNU COREUTILS (version 6.10), which contains roughly 80,000 lines of library code and 61,000 lines in the actual utilities [2]. These programs interact extensively with their environment to provide a variety of functions, including managing the file system (e.g., ls, dd, chmod), displaying and configuring system properties (e.g., logname, printenv, hostname), controlling command invocation (e.g., nohup, nice, env), processing text files (e.g., sort, od, patch), and so on. They form the core user-level environment installed on many Unix systems. They are used daily by millions of people, bug fixes are handled promptly, and new releases are pushed regularly. Moreover, their extensive interaction with the environment stress-tests symbolic execution where it has historically been weakest.
Further, finding bugs in COREUTILS is hard. They are arguably the single most well-tested suite of open-source applications available (e.g., is there a program the reader has used more under Unix than ``ls''?). In 1995, random testing of a subset of COREUTILS utilities found markedly fewer failures as compared to seven commercial Unix systems [35]. The last COREUTILS vulnerability reported on the SecurityFocus or US National Vulnerability databases was three years ago [5,7].
In addition, we checked two other UNIX utility suites: BUSYBOX, a widely-used distribution for embedded systems [1], and the latest release for MINIX [4]. Finally, we checked the HISTAR operating system kernel as a contrast to application code [39].
Our experiments fall into three categories: (1) those where we do intensive runs to both find bugs and get high coverage (COREUTILS, HISTAR, and 75 BUSYBOX utilities), (2) those where we quickly run over many applications to find bugs (an additional 204 BUSYBOX utilities and 77 MINIX utilities), and (3) those where we crosscheck equivalent programs to find deeper correctness bugs (67 BUSYBOX utilities vs. the equivalent 67 in COREUTILS).
In total, we ran KLEE on more than 452 programs, containing over 430K total lines of code. To the best of our knowledge, this represents an order of magnitude more code and distinct programs than checked by prior symbolic test generation work. Our experiments show:
The next section gives an overview of our approach. Section 3 describes KLEE, focusing on its key optimizations. Section 4 discusses how to model the environment. The heart of the paper is Section 5, which presents our experimental results. Finally, Section 6 describes related work and Section 7 concludes.
The code illustrates two additional common features. First, it has bugs, which KLEE finds and generates test cases for. Second, KLEE quickly achieves good code coverage: in two minutes it generates 37 tests that cover all executable statements. 3
KLEE has two goals: (1) hit every line of executable code in the program and (2) detect at each dangerous operation (e.g., dereference, assertion) if any input value exists that could cause an error. KLEE does so by running programs symbolically: unlike normal execution, where operations produce concrete values from their operands, here they generate constraints that exactly describe the set of values possible on a given path. When KLEE detects an error or when a path reaches an exit call, KLEE solves the current path's constraints (called its path condition) to produce a test case that will follow the same path when rerun on an unmodified version of the checked program (e.g, compiled with gcc).
 |
KLEE is designed so that the paths followed by the unmodified program will always follow the same path KLEE took (i.e., there are no false positives). However, non-determinism in checked code and bugs in KLEE or its models have produced false positives in practice. The ability to rerun tests outside of KLEE, in conjunction with standard tools such as gdb and gcov is invaluable for diagnosing such errors and for validating our results.
We next show how to use KLEE, then give an overview of how it works.
A user can start checking many real programs with KLEE in seconds: KLEE typically requires no source modifications or manual work. Users first compile their code to bytecode using the publicly-available LLVM compiler [33] for GNU C. We compiled tr using:
llvm-gcc -emit-llvm -c tr.c -o tr.bc
Users then run KLEE on the generated bytecode, optionally stating the number, size, and type of symbolic inputs to test the code on. For tr we used the command:
klee -max-time 2 -sym-args 1 10 10 -sym-files 2 2000 -max-fail 1 tr.bc
The first option, -max-time, tells KLEE to check tr.bc for at most two minutes. The rest describe the symbolic inputs. The option -sym-args 1 10 10 says to use zero to three command line arguments, the first 1 character long, the others 10 characters long. 4The option -sym-files 2 2000 says to use standard input and one file, each holding 2000 bytes of symbolic data. The option -max-fail 1 says to fail at most one system call along each program path (see § 4.2).
When KLEE runs on tr, it finds a buffer overflow error at line 18 in Figure 1 and then produces a concrete test case (tr [ "" "") that hits it. Assuming the options of the previous subsection, KLEE runs tr as follows:
At any one time, KLEE may be executing a large number of states. The core of KLEE is an interpreter loop which selects a state to run and then symbolically executes a single instruction in the context of that state. This loop continues until there are no states remaining, or a user-defined timeout is reached.
Unlike a normal process, storage locations for a state -- registers, stack and heap objects -- refer to expressions (trees) instead of raw data values. The leaves of an expression are symbolic variables or constants, and the interior nodes come from LLVM assembly language operations (e.g., arithmetic operations, bitwise manipulation, comparisons, and memory accesses). Storage locations which hold a constant expression are said to be concrete.
Symbolic execution of the majority of instructions is straightforward. For example, to symbolically execute an LLVM add instruction:
KLEE retrieves the addends from the %src0 and %src1 registers and writes a new expression Add(%src0, %src1) to the %dst register. For efficiency, the code that builds expressions checks if all given operands are concrete (i.e., constants) and, if so, performs the operation natively, returning a constant expression.
Conditional branches take a boolean expression (branch condition) and alter the instruction pointer of the state based on whether the condition is true or false. KLEE queries the constraint solver to determine if the branch condition is either provably true or provably false along the current path; if so, the instruction pointer is updated to the appropriate location. Otherwise, both branches are possible: KLEE clones the state so that it can explore both paths, updating the instruction pointer and path condition on each path appropriately.
Potentially dangerous operations implicitly generate branches that check if any input value exists that could cause an error. For example, a division instruction generates a branch that checks for a zero divisor. Such branches work identically to normal branches. Thus, even when the check succeeds (i.e., an error is detected), execution continues on the false path, which adds the negation of the check as a constraint (e.g., making the divisor not zero). If an error is detected, KLEE generates a test case to trigger the error and terminates the state.
As with other dangerous operations, load and store instructions generate checks: in this case to check that the address is in-bounds of a valid memory object. However, load and store operations present an additional complication. The most straightforward representation of the memory used by checked code would be a flat byte array. In this case, loads and stores would simply map to array read and write expressions respectively. Unfortunately, our constraint solver STP would almost never be able to solve the resultant constraints (and neither would the other constraint solvers we know of). Thus, as in EXE, KLEE maps every memory object in the checked code to a distinct STP array (in a sense, mapping a flat address space to a segmented one). This representation dramatically improves performance since it lets STP ignore all arrays not referenced by a given expression.
Many operations (such as bound checks or object-level copy-on-write)
require object-specific information. If a pointer can refer to many
objects, these operations become difficult to perform. For simplicity,
KLEE sidesteps this problem as follows. When a dereferenced pointer
p can refer to ![]() objects, KLEE clones the current state
objects, KLEE clones the current state ![]() times. In each state it constrains p to be within bounds of its
respective object and then performs the appropriate read or write
operation. Although this method can be expensive for pointers with
large points-to sets, most programs we have tested only use symbolic
pointers that refer to a single object, and KLEE is well-optimized
for this case.
times. In each state it constrains p to be within bounds of its
respective object and then performs the appropriate read or write
operation. Although this method can be expensive for pointers with
large points-to sets, most programs we have tested only use symbolic
pointers that refer to a single object, and KLEE is well-optimized
for this case.
The number of states grows quite quickly in practice: often even small programs generate tens or even hundreds of thousands of concurrent states during the first few minutes of interpretation. When we ran COREUTILS with a 1GB memory cap, the maximum number of concurrent states recorded was 95,982 (for hostid), and the average of this maximum for each tool was 51,385. This explosion makes state size critical.
Since KLEE tracks all memory objects, it can implement copy-on-write at the object level (rather than page granularity), dramatically reducing per-state memory requirements. By implementing the heap as an immutable map, portions of the heap structure itself can also be shared amongst multiple states (similar to sharing portions of page tables across fork()). Additionally, this heap structure can be cloned in constant time, which is important given the frequency of this operation.
This approach is in marked contrast to EXE, which used one native OS process per state. Internalizing the state representation dramatically increased the number of states which can be concurrently explored, both by decreasing the per-state cost and allowing states to share memory at the object (rather than page) level. Additionally, this greatly simplified the implementation of caches and search heuristics which operate across all states.
Almost always, the cost of constraint solving dominates everything else -- unsurprising, given that KLEE generates complicated queries for an NP-complete logic. Thus, we spent a lot of effort on tricks to simplify expressions and ideally eliminate queries (no query is the fastest query) before they reach STP. Simplified queries make solving faster, reduce memory consumption, and increase the query cache's hit rate (see below). The main query optimizations are:
Expression Rewriting. The most basic optimizations mirror those
in a compiler: e.g., simple arithmetic simplifications (x + 0 =
0), strength reduction (x * 2![]() = x « n), linear
simplification (2*x - x = x).
= x « n), linear
simplification (2*x - x = x).
Constraint Set Simplification. Symbolic execution typically
involves the addition of a large number of constraints to the path
condition. The natural structure of programs means that constraints on
same variables tend to become more specific. For example, commonly an
inexact constraint such as ![]() gets added, followed some time
later by the constraint
gets added, followed some time
later by the constraint ![]() . KLEE actively simplifies the
constraint set by rewriting previous constraints when new equality
constraints are added to the constraint set. In this example,
substituting the value for
. KLEE actively simplifies the
constraint set by rewriting previous constraints when new equality
constraints are added to the constraint set. In this example,
substituting the value for ![]() into the first constraint simplifies
it to true, which KLEE eliminates.
into the first constraint simplifies
it to true, which KLEE eliminates.
Implied Value Concretization. When a constraint such as
![]() is added to the path condition, then the value of x has
effectively become concrete along that path. KLEE determines this
fact (in this case that
is added to the path condition, then the value of x has
effectively become concrete along that path. KLEE determines this
fact (in this case that ![]() ) and writes the concrete value
back to memory. This ensures that subsequent accesses of that memory location
can return a cheap constant expression.
) and writes the concrete value
back to memory. This ensures that subsequent accesses of that memory location
can return a cheap constant expression.
Constraint Independence. Many constraints do not overlap in
terms of the memory they reference. Constraint independence (taken
from EXE) divides
constraint sets into disjoint independent subsets based on the
symbolic variables they reference. By explicitly tracking these
subsets, KLEE can frequently eliminate irrelevant constraints prior
to sending a query to the constraint solver. For example, given the
constraint set
![]() , a query of whether
, a query of whether ![]() just requires the first two constraints.
just requires the first two constraints.
Counter-example Cache. Redundant queries are frequent, and a
simple cache is effective at eliminating a large number of
them. However, it is possible to build a more sophisticated cache due
to the particular structure of constraint sets. The counter-example
cache maps sets of constraints to counter-examples (i.e., variable
assignments), along with a special sentinel used when a set of
constraints has no solution. This mapping is stored in a custom data
structure -- derived from the UBTree structure of Hoffmann and
Hoehler [28] -- which allows efficient searching for
cache entries for both subsets and supersets of a constraint set. By
storing the cache in this fashion, the counter-example cache gains
three additional ways to eliminate queries. In the example below, we
assume that the counter-example cache currently has entries for
![]() (no solution) and
(no solution) and
![]() (satisfiable,
with variable assignments
(satisfiable,
with variable assignments
![]() ).
).
To demonstrate the effectiveness of these optimizations, we performed an experiment where COREUTILS applications were run for 5 minutes with both of these optimizations turned off. We then deterministically reran the exact same workload with constraint independence and the counter-example cache enabled separately and together for the same number of instructions. This experiment was done on a large sample of COREUTILS utilities. The results in Table 1 show the averaged results.
As expected, the independence optimization by itself does not eliminate any queries, but the simplifications it performs reduce the overall running time by almost half (45%). The counter-example cache reduces both the running time and the number of STP queries by 40%. However, the real win comes when both optimizations are enabled; in this case the hit rate for the counter-example cache greatly increases due to the queries first being simplified via independence. For the sample runs, the average number of STP queries are reduced to 5% of the original number and the average runtime decreases by more than an order of magnitude.
It is also worth noting the degree to which STP time (time spent solving queries) dominates runtime. For the original runs, STP accounts for 92% of overall execution time on average (the combined optimizations reduce this by almost 300%). With both optimizations enabled this percentage drops to 41%. Finally, Figure 2 shows the efficacy of KLEE's optimizations increases with time -- as the counter-example cache is filled and query sizes increase, the speed-up from the optimizations also increases.
![\includegraphics[width=3.1in]{figures/solver-opts-2.eps}](img25.png)
|
KLEE selects the state to run at each instruction by interleaving the following two search heuristics.
Random Path Selection maintains a binary tree recording the program path followed for all active states, i.e. the leaves of the tree are the current states and the internal nodes are places where execution forked. States are selected by traversing this tree from the root and randomly selecting the path to follow at branch points. Therefore, when a branch point is reached, the set of states in each subtree has equal probability of being selected, regardless of the size of their subtrees. This strategy has two important properties. First, it favors states high in the branch tree. These states have less constraints on their symbolic inputs and so have greater freedom to reach uncovered code. Second, and most importantly, this strategy avoids starvation when some part of the program is rapidly creating new states (``fork bombing'') as it happens when a tight loop contains a symbolic condition. Note that the simply selecting a state at random has neither property.
Coverage-Optimized Search tries to select states likely to cover new code in the immediate future. It uses heuristics to compute a weight for each state and then randomly selects a state according to these weights. Currently these heuristics take into account the minimum distance to an uncovered instruction, the call stack of the state, and whether the state recently covered new code.
KLEE uses each strategy in a round robin fashion. While this can increase the time for a particularly effective strategy to achieve high coverage, it protects against cases where an individual strategy gets stuck. Furthermore, since strategies pick from the same state pool, interleaving them can improve overall effectiveness.
The time to execute an individual instruction can vary widely between simple instructions (e.g., addition) and instructions which may use the constraint solver or fork execution (branches, memory accesses). KLEE ensures that a state which frequently executes expensive instructions will not dominate execution time by running each state for a ``time slice'' defined by both a maximum number of instructions and a maximum amount of time.
Mechanically, we handle the environment by redirecting calls that access it to models that understand the semantics of the desired action well enough to generate the required constraints. Crucially, these models are written in normal C code which the user can readily customize, extend, or even replace without having to understand the internals of KLEE. We have about 2,500 lines of code to define simple models for roughly 40 system calls (e.g., open, read, write, stat, lseek, ftruncate, ioctl).
For each file system operation we check if the action is for an actual concrete file on disk or a symbolic file. For concrete files, we simply invoke the corresponding system call in the running operating system. For symbolic files we emulate the operation's effect on a simple symbolic file system, private to each state.
Figure 3 gives a rough sketch of the model for read(), eliding details for dealing with linking, reads on standard input, and failures. The code maintains a set of file descriptors, created at file open(), and records for each whether the associated file is symbolic or concrete. If fd refers to a concrete file, we use the operating system to read its contents by calling pread() (lines 7-11). We use pread to multiplex access from KLEE's many states onto the one actual underlying file descriptor. 6If fd refers to a symbolic file, read() copies from the underlying symbolic buffer holding the file contents into the user supplied buffer (lines 13-19). This ensures that multiple read() calls that access the same file use consistent symbolic values.
Our symbolic file system is crude, containing only a single directory
with ![]() symbolic files in it. KLEE users specify both the number
symbolic files in it. KLEE users specify both the number ![]() and the size of these files. This symbolic file system coexists with the real
file system, so applications can use both symbolic and concrete files.
When the program calls open with a concrete name, we (attempt to)
open the actual file. Thus, the call:
and the size of these files. This symbolic file system coexists with the real
file system, so applications can use both symbolic and concrete files.
When the program calls open with a concrete name, we (attempt to)
open the actual file. Thus, the call:
int fd = open("/etc/fstab", O_RDNLY);
sets fd to point to the actual configuration file /etc/fstab.
On the other hand, calling open() with an unconstrained symbolic
name matches each of the ![]() symbolic files in turn, and will also
fail once. For example, given
symbolic files in turn, and will also
fail once. For example, given ![]() , calling open() with a symbolic
command-line argument argv[1]:
, calling open() with a symbolic
command-line argument argv[1]:
int fd = open(argv[1], O_RDNLY);
will result in two paths: one in which fd points to the single symbolic file in the environment, and one in which fd is set to -1 indicating an error.
Unsurprisingly, the choice of what interface to model has a big impact on model complexity. Rather than having our models at the system call level, we could have instead built them at the C standard library level (fopen, fread, etc.). Doing so has the potential performance advantage that, for concrete code, we could run these operations natively. The major downside, however, is that the standard library contains a huge number of functions -- writing models for each would be tedious and error-prone. By only modeling the much simpler, low-level system call API, we can get the richer functionality by just compiling one of the many implementations of the C standard library (we use uClibc [6]) and let it worry about correctness. As a side-effect, we simultaneously check the library for errors as well.
The real environment can fail in unexpected ways (e.g., write() fails because of a full disk). Such failures can often lead to unexpected and hard to diagnose bugs. Even when applications do try to handle them, this code is rarely fully exercised by the regression suite. To help catch such errors, KLEE will optionally simulate environmental failures by failing system calls in a controlled manner (similar to [38]). We made this mode optional since not all applications care about failures -- a simple application may ignore disk crashes, while a mail server expends a lot of code to handle them.
KLEE-generated test cases are rerun on the unmodified native binaries by supplying them to a replay driver we provide. The individual test cases describe an instance of the symbolic environment. The driver uses this description to create actual operating system objects (files, pipes, ttys, directories, links, etc.) containing the concrete values used in the test case. It then executes the unmodified program using the concrete command-line arguments from the test case. Our biggest challenge was making system calls fail outside of KLEE -- we built a simple utility that uses the ptrace debugging interface to skip the system calls that were supposed to fail and instead return an error.
![\includegraphics[width=3.1in]{figures/total-line-dist.eps}](img28.png)
|
This section describes our in-depth coverage experiments for COREUTILS (§ 5.2) and BUSYBOX (§ 5.3) as well as errors found during quick bug-finding runs (§ 5.4). We use KLEE to find deep correctness errors by crosschecking purportedly equivalent tool implementations (§ 5.5) and close with results for HISTAR (§5.6).
We use line coverage as a conservative measure of KLEE-produced test case effectiveness. We chose executable line coverage as reported by gcov, because it is widely-understood and uncontroversial. Of course, it grossly underestimates KLEE's thoroughness, since it ignores the fact that KLEE explores many different unique paths with all possible values. We expect a path-based metric would show even more dramatic wins.
We measure coverage by running KLEE-generated test cases on a stand-alone version of each utility and using gcov to measure coverage. Running tests independently of KLEE eliminates the effect of bugs in KLEE and verifies that the produced test case runs the code it claims.
Note, our coverage results only consider code in the tool itself. They do not count library code since doing so makes the results harder to interpret:
In our experiments KLEE minimizes the test cases it generates by only emitting tests cases for paths that hit a new statement or branch in the main utility code. A user that wants high library coverage can change this setting.
Figure 4 breaks down the tools by executable lines of code (ELOC), including library code the tool calls. While relatively small, the tools are not toys -- the smallest five have between 2K and 3K ELOC, over half (52) have between 3K and 4K, and ten have over 6K.
Previous work, ours included, has evaluated constraint-based execution on a small number of hand-selected benchmarks. Reporting results for the entire COREUTILS suite, the worst along with the best, prevents us from hand-picking results or unintentionally cheating through the use of fragile optimizations.
Almost all tools were tested using the same command (command arguments explained in § 2.1):
./run <tool-name> -max-time 60 -sym-args 10 2 2 -sym-files 2 8 [-max-fail 1]
As specified by the -max-time option, we ran each tool for about 60 minutes (some finished before this limit, a few up to three minutes after). For eight tools where the coverage results of these values were unsatisfactory, we consulted the man page and increased the number and size of arguments and files. We found this easy to do, so presumably a tool implementer or user would as well. After these runs completed, we improved them by failing system calls (see § 4.2).
The first two columns in Table 2 give aggregate line coverage results. On average our tests cover 90.9% of the lines in each tool (median: 94.7%), with an overall (aggregate) coverage across all tools of 84.5%. We get 100% line coverage on 16 tools, over 90% on 56 tools, and over 80% on 77 tools (86.5% of all tools). The minimum coverage achieved on any tool is 62.6%.
We believe such high coverage on a broad swath of applications ``out of the box'' convincingly shows the power of the approach, especially since it is across the entire tool suite rather than focusing on a few particular applications.
Importantly, KLEE generates high coverage with few test cases: for
our non-failing runs, it needs a total of 3,321 tests, with
a per-tool average of 37 (median: 33). The maximum
number needed was 129 (for the ``['' tool) and six
needed 5. As a crude measure of path complexity, we counted
the number of static branches run by each test case using gcov7(i.e., an executed branch counts once no matter how many times
the branch ran dynamically). The average path length was 76 (median: 53), the maximum was 512 and (to pick a random
number) 160 were at least 250 branches long.
Figure 5 shows the coverage KLEE achieved on each tool, with and without failing system call invocations. Hitting system call failure paths is useful for getting the last few lines of high-coverage tools, rather than significantly improving the overall results (which it improves from 79.9% to 84.5%). The one exception is pwd which requires system call failures to go from a dismal 21.2% to 72.6%. The second best improvement for a single tool is a more modest 13.1% extra coverage on the df tool.
Each utility in COREUTILS comes with an extensive manually-written test suite extended each time a new bug fix or extra feature is added. 8 As Table 2 shows, KLEE beats developer tests handily on all aggregate measures: overall total line coverage (84.5% versus 67.7%), average coverage per tool (90.9% versus 68.4%) and median coverage per tool (94.7% versus 72.5%). At a more detailed level, KLEE gets 100% coverage on 16 tools and over 90% coverage on 56 while the developer tests get 100% on a single utility (true) and reach over 90% on only 7. Finally, the developers tests get below 60% coverage on 24 tools while KLEE always achieves over 60%. In total, an 89 hour run of KLEE (about one hour per application) exceeds the coverage of a test suite built over a period of fifteen years by 16.8%!
![\includegraphics[width=3.1in]{figures/dev-delta-misc.eps}](img30.png)
|
Figure 6 gives a relative view of KLEE versus developer tests by subtracting the lines hit by manual testing from those hit by KLEE and dividing this by the total possible. A bar above zero indicates that KLEE beat the manual test (and by how much); a bar below shows the opposite. KLEE beats manual testing, often significantly, on the vast majority of the applications.
To guard against hidden bias in line coverage, we also compared the taken branch coverage (as reported by gcov) of the manual and KLEE test suites. While the absolute coverage for both test suites decreases, KLEE's relative improvement over the developers' tests remains: KLEE achieves 76.9% overall branch coverage, while the developers' tests get only 56.5%.
Finally, it is important to note that although KLEE's runs significantly beat the developers' tests in terms of coverage, KLEE only checks for low-level errors and violations of user-level asserts. In contrast, developer tests typically validate that the application output matches the expected one. We partially address this limitation by validating the output of these utilities against the output produces by a different implementation (see § 5.5).
KLEE found ten unique bugs in COREUTILS (usually memory error crashes). Figure 7 gives the command lines used to trigger them. The first three errors existed since at least 1992, so should theoretically crash any COREUTILS distribution up to 6.10. The others are more recent, and do not crash older COREUTILS distributions. While one bug (in seq) had been fixed in the developers' unreleased version, the other bugs were confirmed and fixed within two days of our report. In addition, versions of the KLEE-generated test cases for the new bugs were added to the official COREUTILS test suite.
 |
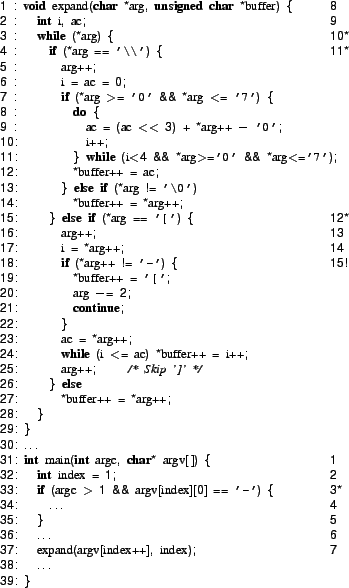
As an illustrative example, we discuss the bug in pr (used to
paginate files before printing) hit by the invocation ``pr -e
t2.txt'' in Figure 7. The code containing the
bug is shown in Figure 8. On the path that hits the bug,
both chars_per_input_tab and chars_per_c equal tab width (let's call it ![]() ). Line
2665 computes
). Line
2665 computes
![]() using the macro on line 602.
The root cause of the bug is the incorrect assumption that
using the macro on line 602.
The root cause of the bug is the incorrect assumption that
![]() , which only holds for positive integers. When input_position is positive, width will be less
than
, which only holds for positive integers. When input_position is positive, width will be less
than ![]() since
since
![]() .
However, in the presence of backspaces, input_position
can become negative, so
.
However, in the presence of backspaces, input_position
can become negative, so
![]() . Consequently, width can be as large as
. Consequently, width can be as large as
![]() .
.
 |
The bug arises when the code allocates a buffer clump_buff of size ![]() (line 1322) and then writes width characters into this buffer (lines 2669-2670) via the
pointer s (initially set to clump_buff). Because width can be as large as
(line 1322) and then writes width characters into this buffer (lines 2669-2670) via the
pointer s (initially set to clump_buff). Because width can be as large as
![]() , a memory overflow is possible.
, a memory overflow is possible.
This is a prime example of the power of symbolic execution in finding complex errors in code which is hard to reason about manually -- this bug has existed in pr since at least 1992, when COREUTILS was first added to a CVS repository.
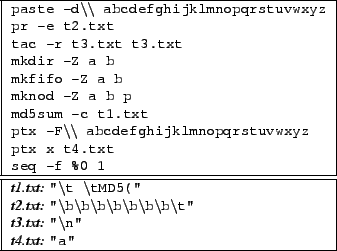
In our opinion, the COREUTILS manual tests are unusually comprehensive. However, we compare to random testing both to guard against deficiencies, and to get a feel for how constraint-based reasoning compares to blind random guessing. We tried to make the comparison apples-to-apples by building a tool that takes the same command line as KLEE, and generates random values for the specified type, number, and size range of inputs. It then runs the checked program on these values using the same replay infrastructure as KLEE. For time reasons, we randomly chose 15 benchmarks (shown in Figure 9) and ran them for 65 minutes (to always exceed the time given to KLEE) with the same command lines used when run with KLEE.
![\includegraphics[width=3.1in]{figures/rnd-cov-graph.eps}](img45.png)
|
Figure 9 shows the coverage for these programs achieved by random, manual, and KLEE tests. Unsurprisingly, given the complexity of COREUTILS programs and the concerted effort of the COREUTILS maintainers, the manual tests get significantly more coverage than random. KLEE handily beats both.
Because gcov introduces some overhead, we also performed a second experiment in which we ran each tool natively without gcov for 65 minutes (using the same random seed as the first run), recorded the number of test cases generated, and then reran using gcov for that number. This run completely eliminates the gcov overhead, and overall it generates 44% more tests than during the initial run.
However, these 44% extra tests increase the average coverage per tool by only 1%, with 11 out of 15 utilities not seeing any improvement -- showing that random gets stuck for most applications. We have seen this pattern repeatedly in previous work: random quickly gets the cases it can, and then revisits them over and over. Intuitively, satisfying even a single 32-bit equality requires correctly guessing one value out of four billion. Correctly getting a sequence of such conditionals is hopeless. Utilities such as csplit (the worst performer), illustrate this dynamic well: their input has structure, and the difficulty of blindly guessing values that satisfy its rules causes most inputs to be rejected.
One unexpected result was that for 11 of these 15 programs, KLEE explores paths to termination (i.e., the checked code calls exit()) only a few times slower than random does! KLEE explored paths to termination in roughly the same time for three programs and, in fact, was actually faster for three others (seq, tee, and nohup). We were surprised by these numbers, because we had assumed a constraint-based tool would run orders of magnitude more slowly than raw testing on a per-path basis, but would have the advantage of exploring more unique paths over time (with all values) because it did not get stuck. While the overhead on four programs matched this expectation (where constraint solver overhead made paths ran 7x to 220x more slowly than native execution), the performance tradeoff for the others is more nuanced. Assume we have a branch deep in the program. Covering both true and false directions using traditional testing requires running the program from start to finish twice: once for the true path and again for the false. In contrast, while KLEE runs each instruction more slowly than native execution, it only needs to run the instruction path before the branch once, since it forks execution at the branch point (a fast operation given its object-level copy-on-write implementation). As path length grows, this ability to avoid redundantly rerunning path prefixes gets increasingly important.
With that said, the reader should view the per-path costs of random and KLEE as very crude estimates. First, the KLEE infrastructure random uses to run tests adds about 13ms of per-test overhead, as compared to around 1ms for simply invoking a program from a script. This code runs each test case in a sandbox directory, makes a clean environment, and creates various system objects with random contents (e.g., files, pipes, tty's). It then runs the tested program with a watchdog to terminate infinite loops. While a dedicated testing tool must do roughly similar actions, presumably it could shave some milliseconds. However, this fixed cost matters only for short program runs, such as when the code exits with an error. In cases where random can actually make progress and explore deeper program paths, the inefficiency of re-running path prefixes starts to dominate. Further, we conservatively compute the path completion rate for KLEE: when its time expires, roughly 30% of the states it has created are still alive, and we give it no credit for the work it did on them.
BUSYBOX is a widely-used implementation of standard UNIX utilities for embedded systems that aims for small executable sizes [1]. Where there is overlap, it aims to replicate COREUTILS functionality, although often providing fewer features. We ran our experiments on a bug-patched version of BUSYBOX 1.10.2. We ran the 75 utilities 9 in the BUSYBOX ``coreutils'' subdirectory (14K lines of code, with another 16K of library code), using the same command lines as when checking COREUTILS, except we did not fail system calls.
As Table 2 shows, KLEE does even better than on COREUTILS: over 90.5% total line coverage, on average covering 93.5% per tool with a median of 97.5%. It got 100% coverage on 31 and over 90% on 55 utilities.
BUSYBOX has a less comprehensive manual test suite than COREUTILS (in fact, many applications don't seem to have any tests). Thus, KLEE beats the developers tests by roughly a factor of two: 90.5% total line coverage versus only 44.8% for the developers' suite. The developers do better on only one benchmark, cp.
 |
KLEE makes no approximations: its constraints have perfect accuracy down to the level of a single bit. If KLEE reaches an assert and its constraint solver states the false branch of the assert cannot execute given the current path constraints, then it has proved that no value exists on the current path that could violate the assertion, modulo bugs in KLEE or non-determinism in the code. 10 Importantly, KLEE will do such proofs for any condition the programmer expresses as C code, from a simple non-null pointer check, to one verifying the correctness of a program's output.
This property can be leveraged to perform deeper checking as follows. Assume we have two procedures f and f' that take a single argument and purport to implement the same interface. We can verify functional equivalence on a per-path basis by simply feeding them the same symbolic argument and asserting they return the same value: assert(f(x) == f'(x)). Each time KLEE follows a path that reaches this assertion, it checks if any value exists on that path that violates it. If it finds none exists, then it has proven functional equivalence on that path. By implication, if one function is correct along the path, then equivalence proves the other one is as well. Conversely, if the functions compute different values along the path and the assert fires, then KLEE will produce a test case demonstrating this difference. These are both powerful results, completely beyond the reach of traditional testing. One way to look at KLEE is that it automatically translates a path through a C program into a form that a theorem prover can reason about. As a result, proving path equivalence just takes a few lines of C code (the assertion above), rather than an enormous manual exercise in theorem proving.
Note that equivalence results only hold on the finite set of paths that KLEE explores. Like traditional testing, it cannot make statements about paths it misses. However, if KLEE is able to exhaust all paths then it has shown total equivalence of the functions. Although not tractable in general, many isolated algorithms can be tested this way, at least up to some input size.
We help make these points concrete using the contrived example in
Figure 11, which crosschecks a trivial modulo
implementation (mod) against one that optimizes for modulo by
powers of two (mod_opt). It first makes the inputs x and y
symbolic and then uses the assert (line 14) to check for differences.
Two code paths reach this assert, depending on whether the test
for power-of-two (line 2) succeeds or fails. (Along the way,
KLEE generates a division-by-zero test case for when ![]() .)
The true path uses the
solver to check that the constraint
.)
The true path uses the
solver to check that the constraint
![]() implies
implies
![]() holds for all values.
This query succeeds. The false path checks the
vacuous tautology that the constraint
holds for all values.
This query succeeds. The false path checks the
vacuous tautology that the constraint
![]() implies that
implies that
![]() also holds.
The KLEE checking run
then terminates, which means that KLEE has proved equivalence
for all non-zero values using only a few lines of code.
also holds.
The KLEE checking run
then terminates, which means that KLEE has proved equivalence
for all non-zero values using only a few lines of code.
This methodology is useful in a broad range of contexts. Most standardized interfaces -- such as libraries, networking servers, or compilers -- have multiple implementations (a partial motivation for and consequence of standardization). In addition, there are other common cases where multiple implementations exist:
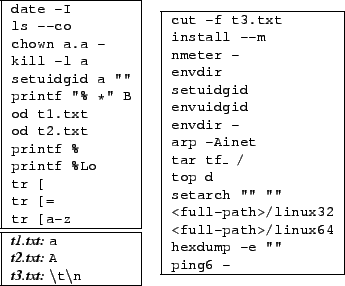
Experimental results. We show that this technique can find deep correctness errors and scale to real programs by crosschecking 67 COREUTILS tools against their allegedly equivalent BUSYBOX implementations. For example, given the same input, the BUSYBOX and COREUTILS versions of wc should output the same number of lines, words and bytes. In fact, both the BUSYBOX and COREUTILS tools intend to conform to IEEE Standard 1003.1 [3] which specifies their behavior.
We built a simple infrastructure to make crosschecking automatic. Given two tools, it renames all their global symbols and then links them together. It then runs both with the same symbolic environment (same symbolic arguments, files, etc.) and compares the data printed to stdout. When it detects a mismatch, it generates a test case that can be run to natively to confirm the difference.
Table 3 shows a subset of the mismatches found by KLEE. The first three lines show hard correctness errors (which were promptly fixed by developers), while the others mostly reveal missing functionality. As an example of a serious correctness bug, the first line gives the inputs that when run on BUSYBOX's comm causes it to behave as if two non-identical files were identical.
| |||||||||||||||||||||||||||||||||||||||||||||
Although the setup is restrictive, in practice we have found that it can quickly generate test cases -- sequences of system call vectors and memory contents -- which cover a large portion of the kernel code and uncover interesting behaviors. Table 4 shows the coverage obtained for the core kernel for runs with and without a disk. When configured with a disk, a majority of the uncovered code can only be triggered when there are a large number of kernel objects. This currently does not happen in our testing environment; we are investigating ways to exercise this code adequately during testing. As a quick comparison, we ran one million random tests through the same driver (similar to § 5.2.4). As Table 4 shows, KLEE's tests achieve significantly more coverage than random testing both for runs with (+17.0%) and without (+28.4%) a disk.
 |
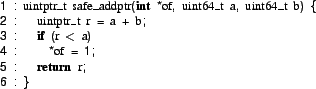
KLEE's constraint-based reasoning allowed it to find a tricky, critical security bug in the 32-bit version of HISTAR. Figure 13 shows the code for the function containing the bug. The function safe_addptr is supposed to set *of to true if the addition overflows. However, because the inputs are 64 bit long, the test used is insufficient (it should be (r < a) || (r < b)) and the function can fail to indicate overflow for large values of b.
The safe_addptr function validates user memory addresses prior to copying data to or from user space. A kernel routine takes a user address and a size and computes if the user is allowed to access the memory in that range; this routine uses the overflow to prevent access when a computation could overflow. This bug in computing overflow therefore allows a malicious process to gain access to memory regions outside its control.
 |
To the best of our knowledge, traditional symbolic execution systems [17,18,32] are static in a strict sense and do not interact with the running environment at all. They either cannot handle programs that make use of the environment or require a complete working model. More recent work in test generation [16,26,36] does allow external interactions, but forces them to use entirely concrete procedure call arguments, which limits the behaviors they can explore: a concrete external call will do exactly what it did, rather than all things it could potentially do. In KLEE, we strive for a functional balance between these two alternatives; we allow both interaction with the outside environment and supply a model to simulate interaction with a symbolic one.
The path explosion problem has instead received more attention [11,24,27,34,22]. Similarly to the search heuristics presented in Section 3, search strategies proposed in the past include Best First Search [16], Generational Search [27], and Hybrid Concolic Testing [34]. Orthogonal to search heuristics, researchers have addressed the path explosion problem by testing paths compositionally [24,8], and by tracking the values read and written by the program [11].
Like KLEE, other symbolic execution systems implement their own optimizations before sending the queries to the underlying constraint solver, such as the simple syntactic transformations presented in [36], and the constraint subsumption optimization discussed in [27].
Similar to symbolic execution systems, model checkers have been used to find bugs in both the design and the implementation of software [30,10,29,12,19,25]. These approaches often require a lot of manual effort to build test harnesses. However, the approaches are somewhat complementary to KLEE: the tests KLEE generates can be used to drive the model checked code, similar to the approach embraced by Java PathFinder [31,37].
Previously, we showed that symbolic execution can find correctness errors by crosschecking various implementations of the same library function [15]; this paper shows that the technique scales to real programs. Subsequent to our initial work, others applied similar ideas to finding correctness errors in applications such as network protocol implementations [13] and PHP scripts [9].
Our long-term goal is to take an arbitrary program and routinely get 90%+ code coverage, crushing it under test cases for all interesting inputs. While there is still a long way to go to reach this goal, our results show that the approach works well across a broad range of real code. Our system KLEE, automatically generated tests that, on average, covered over 90% of the lines (in aggregate over 80%) in roughly 160 complex, system-intensive applications ''out of the box.'' This coverage significantly exceeded that of their corresponding hand-written test suites, including one built over a period of 15 years.
In total, we used KLEE to check 452 applications (with over 430K lines of code), where it found 56 serious bugs, including ten in COREUTILS, arguably the most heavily-tested collection of open-source applications. To the best of our knowledge, this represents an order of magnitude more code and distinct programs than checked by prior symbolic test generation work. Further, because KLEE's constraints have no approximations, its reasoning allow it to prove properties of paths (or find counter-examples without false positives). We used this ability both to prove path equivalence across many real, purportedly identical applications, and to find functional correctness errors in them.
The techniques we describe should work well with other tools and provide similar help in handling a broad class of applications.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons -no_navigation paper.tex
The translation was initiated by Cristian on 2008-10-08

![\includegraphics[width=3.1in]{figures/cov-hist-new.eps}](img29.png)
