
Traub et al. [11] previously described a linear scan variant to deal with holes. Our approach differs in two ways.13First, we perform the intersection of two sparse live intervals, rather than insisting on perfect nesting of one interval within another. Although this introduces super-linear complexity to the algorithm, we do not believe this causes major problems in practice.
|
Secondly, Traub et al.'s algorithm splits live ranges on the fly, with a post-pass clean-up phase to reconcile differences. In contrast, our algorithm marks certain symbolic registers as spilled. A post-pass clean-up phase deals with the spills. If an instruction uses a spilled register, the clean-up phase either introduces a memory operand referring to the spilled memory location, or moves the spilled value into a scratch register. On PowerPC, the original register allocator reserved three registers for use as scratch, so finding a free scratch register was almost always trivial. On IA32, we did not reserve any scratch registers, so the register allocator must create scratch registers upon demand.
Figure 5 details the algorithm for dealing with spilled values. The algorithm makes one pass over the statements. As it progresses, the algorithm keeps track of which symbolic register values are cached in each scratch register. Before each statement, the algorithm vacates any scratch registers which are needed for the next statement. Then, the algorithm processes a statement. It attempts to replace spilled symbolic registers with memory operands representing the spill location. If this is infeasible, the algorithm chooses a physical register as a victim to be vacated, so the victim can be used as a scratch register. The victim will continue to cache the symbolic value until either the physical register is needed for a future statement, or the victim is chosen to cache a different symbolic register. Scratch register mappings are not maintained across basic block boundaries; all victims are vacated at block exits.
As a side effect of vacating and introducing scratch registers, the code updates stack maps required for type-exact GC.
for each statement s do
if s can leave the basic block via a call, jump, fall-through, or exception then
vacate cached value and restore original value for each scratch register before s
vacate cached value and restore original value for any scratch register used by s
for each spilled symbolic register r in s do
if r is currently cached in scratch register p then
replace r with p in statement s
else if s needs a scratch register for r then
choose a scratch register victim p to hold r in s
vacate current value of p
cache value of r in p
replace r with p in statement s
else replace r with a memory operand representing r's spill location
done
done
|
With the IA32 limited register set, spills are common and have a huge impact on performance. Subsequent to the initial functional port, we introduced several heuristics and optimizations to improve performance.
We now evaluate the following heuristics to reduce register pressure. We provide only a high-level overview of each heuristic; consult the open-source code for more details.
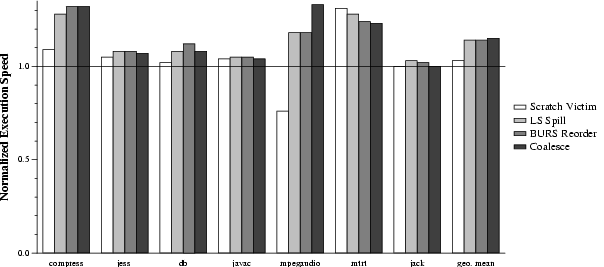 |
Figure 6 shows the marginal performance improvement gained by enabling each of these four optimizations cumulatively, compared to performance with none enabled. Thus, the bar labeled ``Scratch Victim'' enables intelligent scratch victim selection; the next bar ``LS Spill'' further enables the linear scan spill heuristic, etc.
Altogether, the register pressure heuristics improve performance on average by 15%. The results show that the spill heuristics and scratch register selection heuristics are most effective across the board. Anomalously, the scratch victim heuristic hurts mpegaudio; we currently have no explanation for this. Instruction selection re-ordering has a minimal impact, slightly improving compress and db. Coalescing is usually insignificant; except it causes a substantial improvement for mpegaudio. Mtrt degrades as we add more optimizations; however, the floating-point results here should be taken with a grain of salt, since Figure 3 shows that Jikes RVM IA32 floating-point performance is mediocre, even with all optimizations enabled.
