
Alexandro Baldassin State University of Campinas, Brazil alebal@ic.unicamp.br Sebastian Burckhardt Microsoft Research, Redmond sburckha@microsoft.com
To investigate if and how software transactional memory (STM) can help a programmer to parallelize applications, we perform a case study on a game application called SpaceWars3D. After experiencing suboptimal performance, we depart from classic STM designs and propose a programming model that uses long-running, abort-free transactions that rely on user specifications to avoid or resolve conflicts. With this model we achieve the combined goal of competitive performance and improved programmability.
With the exponential growth in power dissipation and limitations on the microarchitectural level, the semiconductor industry has shifted its focus towards multicore architectures. Unfortunately, many applications are not designed to exploit true concurrency available on a multicore processor and thus no longer get the benefit of steady performance improvements with the succession of new chip generations. The task of filling in the gap between hardware and software and bringing concurrent programming to the mainstream is being regarded as one of the greatest challenges in computer science in the last 50 years [5], with companies such as Microsoft and Intel investing heavily in academic research in this area.
The most common concurrent programming model today is based on a shared memory architecture wherein a thread is the unit of concurrency. Threads communicate through reads and writes from/to shared memory and, to avoid conflicts, they synchronize using locks. Often, locks are used to construct so-called critical sections, areas of code that can not be entered by more than one thread at a time. An alternative to lock-based synchronization is known as transactional memory [4]. In this model programmers specify transactions, blocks of code that appears to execute atomically and in isolation. The underlying runtime system (implemented in hardware, software or a mix of both) is responsible for detecting conflicts and providing a consistent (serializable or linearizable) execution of the transactions.
Transactional memory is an active research field and the approach seems promising: benchmarks show that transactional memory can improve the performance of some code, such as scientific algorithms or concurrent data type implementations. Nevertheless, how to successfully integrate transactional memory into more mainstream applications remains an open question [10]. We believe that programmers will adopt TM only if it can deliver both a substantially simplified programming experience and competitive performance compared to traditional lock-based designs.
To address this general challenge, we conducted a parallelization case study on a full-featured game application, SpaceWars3D [3]. We first restructured the sequential code into cleanly separated modules dealing with the different aspects of the game (Fig.1). Then we tried to parallelize the tasks performed in each frame (such as rendering the screen, updating positions of game objects, detecting collisions, etc.). We quickly realized that traditional synchronization (locks and critical sections) is cumbersome to use. For more convenient programming, we tried to execute each task as a transaction, provided by an STM. Unfortunately, performance was poor because of (1) frequent conflicts and rollbacks, and (2) the large overhead of transactional execution.
To resolve these problems, we departed from standard STM designs and developed a novel programming model. It replicates the shared data so that each task can access its local replica without synchronization. The replicas are reconciled by propagating updates between frames. The key design decisions are (1) tasks never abort, and (2) data consistency requirements are specified by the programmer using object-oriented techniques.
The user plays an active role in controlling concurrency. First, she may restrict concurrency by enforcing specific task orderings using task barriers. Second, she may enable concurrent modifications of certain objects by specifying how to reconcile conflicts (using priorities or a general merge function).
This final strategy performed well. Although we ask the programmer to think quite a bit about data sharing and data consistency, we feel that there is a substantial value to the exercise as it leads to a more declarative and more concurrent programming style than traditional approaches. Most of the task conflicts found and reported during runtime were either easily eliminated (some even helped us to find bugs in the code), or revealed an important dependency between tasks that we had not detected before.
Our main contributions are (1) that we report on the challenges we encountered when parallelizing a game application, and (2) that we propose a programming model (based on long-running, abort-free transactions with user-specified merge-based consistency) that achieves good programmability and competitive performance.
There are two main works reporting on experiences in using TM to parallelize large applications. Scott et al. [8] employ a mix of barriers and transactions to create a parallel implementation of Delaunay triangulation. Watson et al. [9] investigate how Lee's routing algorithm can be made parallel by using transactions. Where our work differs from theirs is in the application domain (we have a game application) and in how we solved the performance problem imposed by long-running transactions. Blundell et al. [2] devise unrestricted transactions as a mean of allowing transactions to perform I/O. Aydonat and Abdelrahman [1] propose conflict-serializability in order to reduce the abort rate of long-running transactions. Our solution allows both I/O and long-running transactions by completely avoiding aborts. Rhalibi et al. [6] present a framework for modeling games as cyclic-task-dependency graphs and a runtime scheduler. However, their framework does not use replication; rather it is based on the classic lock-based synchronization primitives.
As in our work, Rinard and Diniz [7] use object replication for better concurrency. However, they apply it in a different context (a parallelizing compiler).
Our starting point was a enhanced 3D Windows version of the classic
game Spacewars, as described in a tutorial book [3]
and with source code available on the
web.![[*]](footnote.png) In a nutshell,
the game consists of two starships shooting one another in space. It
is coded in C# and uses the ManagedDirectX API. Developed to teach
game programming, it features many realistic details including 3D
rendered graphics, sound, and a network connection.
In a nutshell,
the game consists of two starships shooting one another in space. It
is coded in C# and uses the ManagedDirectX API. Developed to teach
game programming, it features many realistic details including 3D
rendered graphics, sound, and a network connection.
Because the original game lacked sufficiently heavy computation to challenge our machine, we added moving asteroids to the gameplay. Asteroids may collide with other game objects. By varying the number of asteroids (we used around 1500 in our experiments) we can conveniently adjust the workload.
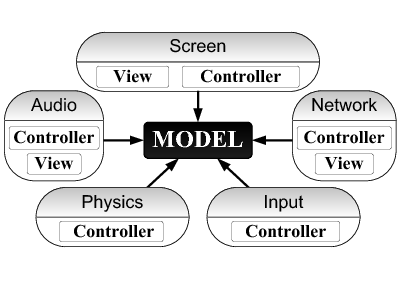
As a first step we rearchitected the code following the Model-View-Controller (MVC) design. MVC has been widely used in many different environments. In our case, its role is to express concurrency between the controllers, and to separate shared data (the model) from controller-local data (the views).
Our MVC architecture is shown in Fig. 1. It has a model at the center, surrounded by several modules. Each module handles one game aspect (sound, graphics, input, physics, network). The model encapsulates the essential game state. In our case, it consists of hierarchically organized game objects (player ships, asteroids, projectiles). The model is passive -- it does not contain any threads, but its objects may be read and updated by the modules.
The modules are the gateways between the model and the external world; they respond to external events (incoming network packets, user input) by updating the model, and they in turn send information about the model to external entities (such as the screen, or to remote players). A module contains exactly one controller and may contain one or more views. Controllers are active (they may contain one or more threads). Views encapsulate data relating to a particular external interface. We now describe the modules in turn:
We now describe the main challenges we encountered in more detail.
The original code is almost completely sequential: all tasks (except the receipt of network packets) are performed by the main thread, inside a game loop that repeats every frame. To improve performance on a multicore, we need to find ways to distribute the work for concurrent execution on multiple processors.
In fact, there is plenty of opportunity for concurrency. We distinguish three kinds. First, as visible in Fig. 1, there is natural concurrency among different controllers. Second, some controllers (such as the physics controller) perform more than one task in each frame, which can also be concurrent. Finally, some (but not all) tasks lend themselves to parallelization; for instance, we can split the collision handler into concurrent subtasks.
All three kinds of concurrency are realized in our final solution (see the experiments in Section 5).
As can be seen from Fig. 1, an easy and safe way to provide synchronization is to use a single lock to protect the entire model, and run the entire task in a critical section. Unfortunately, this scheme would imply that only one task runs at a time, so we would perform no better (and likely worse) than the sequential game.
The standard methodology to address this issue is to use (1) fine-grained locking, and (2) shorter critical sections. We ran into serious problems with this approach, however.
Next, we turned to software transactional memory (STM) which uses optimistic concurrency control: a runtime system monitors the memory accesses performed by a transaction and rolls them back if there are any conflicts. Unfortunately, we found that in our situation, standard STMs do not perform as envisioned, for the following three reasons.
Note that all three of these problems could be addressed by reducing the size of transactions; but then we would face similar programmability issues as with critical sections.
Our solution combines the MVC programming model with a classic trick from the concurrency playbook: replication.
 |
First, each controller tells the runtime system the tasks it needs to perform (Fig. 2). The runtime system then calls these tasks concurrently in each frame, giving each task its own replica of the world to work on. At the end of each frame, any updates made to the task-local replicas are propagated to all other replicas.
To share data between tasks, the user wraps it with templates provided by the runtime library (Fig. 3). The runtime then creates task-local replicas automatically and propagates updates at the end of each frame. We use different template variations to wrap values, objects, and collections, respectively.
 |
Accessing the replicated data from within the tasks is straightforward
(Fig. 4). For shared values, we use simple get()
and set(value) methods to read or modify the task-local
replica. For shared objects and collections, we gain access to the
local replica by calling GetReadonly() or GetForWrite(),
depending on whether we plan to modify the object.
By default, our runtime throws an exception if shared objects are modified by more than one task. To allow truly concurrent modification, our runtime currently supports three kinds of specialized wrappers (Fig. 5).
 |
In addition to wrapper templates, our library supports task barriers (Fig. 6). If the user specifies a task barrier ordering task A before task B, then task B does not start until task A is finished, and all object updates performed by task A are propagated to task B.
The runtime implementation takes care of managing the shared data (Fig. 7). It instantiates a fixed number of replicas of each shared object, equal to the number of tasks. Each task uses its (unique) task number to index into the array and access its own replica. In each frame, we record the set of shared objects each task has modified.
![\begin{figure}\begin{Verbatim}public class SharedValue<T>
{
private T[] valu...
...lue;
Frame.MarkModified(this, my_task_id);
}
...
.\end{Verbatim}
\end{figure}](img6.png) |
At the end of each frame, we process all the objects that were modified by some task. If they were modified by just one task, we simply propagate the updated version to all other copies, either by direct assignment (for shared values) or by calling an assignment method (for shared objects and collections). If an object was modified by more than one task, we pairwise reconcile the updates (using the priority, or using a merge function) before we propagate the final result to all replicas.
To reduce the amount of copying, we perform several optimizations. For one, all reader tasks (tasks that do not update any shared objects) share the same ``master'' replica. Second, we perform a copy-on-write optimization: rather than propagating updates eagerly at the end of the frame, we keep accessing the master read-only copy until the first time a replica is modified, at which time we perform the propagation.
![\begin{figure}\begin{tabular}{\vert l\vert lll\vert}\hline
Experiment & A & B & ...
...2 & 10 \\
Total memory [MB] & 85 & 93 & 125 \\ \hline
\end{tabular}\end{figure}](img7.png) |
|
We measured the performance of the game in three experiments on a 4-core machine, using increasing amounts of replication and concurrency, and observing increasing speedups. We show frames per second, speedup, total memory consumption, and the three most time-consuming tasks in Fig. 8. To visualize the results, we instrumented our prototype to capture and display task schedules. We show typical schedules in Fig. 9.
Experiment A (the sequential baseline) performs all tasks sequentially, using no replication and no synchronization. The corresponding schedule in Fig. 9 thus shows no overlap between tasks.
Experiment B (partial concurrency) is similar to traditional double-buffering techniques. It creates two replicas only. One replica is shared among all reader tasks (tasks that do not modify the model). The other replica is used by updater tasks (tasks that may modify the model), which are scheduled sequentially (one updater at a time). The corresponding schedule in Fig. 9 shows significant overlap between the RefrWnd reader task (which renders the screen) and the UpdateCollisions updater task (which handles collision). The total time spent for each frame is thus shorter.
Experiment C (full concurrency) uses one replica per task, as described in the previous section. Furthermore, it breaks the collision detection task into three roughly equal pieces. The corresponding schedule in Fig. 9 shows that on our 4-core machine, we almost reach maximal concurrency for this application and machine (the total frame length can not be smaller than the largest sequential piece, RefrWnd, which is limited by the graphics card).
The (comparatively modest) overhead incurred by our runtime is visible in the form of slightly longer-running tasks, and as two additional tasks (CopyBack and Reconcile).
We propose a novel programming methodology based on long-running, abort-free transactions with user-specified object-wise consistency. Our experiments on a game application confirm that our programming model can deliver an attractive compromise between programming convenience and multicore performance.
Future work will address how to simplify the programmer experience further (for instance, by supporting events and observer patterns), and to engineer a runtime prototype that scales to larger games with many thousands of game objects.
We thank the many people that contributed insightful comments and interesting discussions, including (but not limited to) Jim Larus, Tom Ball, Patrice Godefroid, and Trishul Chilimbi.

![\includegraphics[scale=.47,viewport=14 14 507 215]{figures/7000A}](img8.png)
![\includegraphics[scale=.47,viewport=14 14 508 235]{figures/7000B}](img9.png)
![\includegraphics[scale=.47,viewport=14 14 333 325]{figures/7000C}](img10.png)