
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
HotOS IX Paper
[HotOS IX Program Index]
Why Events Are A Bad Idea
|
|
The message-passing systems described by Lauer and Needham do not correspond precisely to modern event systems in their full generality. First, Lauer and Needham ignore the cooperative scheduling used by events for synchronization. Second, most event systems use shared memory and global data structures, which are described as atypical for Lauer and Needham's message-passing systems. In fact, the only event system that really matches their canonical message-passing system is SEDA [17], whose stages and queues map exactly to processes and message ports.1
Finally, the performance equivalence claimed by Lauer and Needham requires equally good implementations; we don't believe there has been a suitable threads implementation for very high concurrency. We demonstrate one in the next section, and we discuss further enhancements in Section 4.
In arguing that performance should be equivalent, Lauer and Needham implicitly use a graph that we call a blocking graph. This graph describes the flow of control through an application with respect to blocking or yielding points. Each node in this graph represents a blocking or yielding point, and each edge represents the code that is executed between two such points. The Lauer-Needham duality argument essentially says that duals have the same graph.
The duality argument suggests that criticisms of thread performance and usability in recent years have been motivated by problems with specific threading packages, rather than with threads in general. We examine the most common criticisms below.
Performance. Criticism: Many attempts to use threads for high concurrency have not performed well. We don't dispute this criticism; rather, we believe it is an artifact of poor thread implementations, at least with respect to high concurrency. None of the currently available thread packages were designed for both high concurrency and blocking operations, and thus it is not surprising that they perform poorly.
A major source of overhead is the presence of operations that are O(n) in the number of threads. Another common problem with thread packages is their relatively high context switch overhead when compared with events. This overhead is due to both preemption, which requires saving registers and other state during context switches, and additional kernel crossings (in the case of kernel threads).
However, these shortcomings are not intrinsic properties of threads. To illustrate this fact, we repeated the SEDA threaded server benchmark [17] with a modified version of the GNU Pth user-level threading package, which we optimized to remove most of the O(n) operations from the scheduler. The results are shown in Figure 2. Our optimized version of Pth scales quite well up to 100,000 threads, easily matching the performance of the event-based server.

|
Control Flow. Criticism: Threads have restrictive control flow. One argument against threaded programming is that it encourages the programmer to think too linearly about control flow, potentially precluding the use of more efficient control flow patterns. However, complicated control flow patterns are rare in practice. We examined the code structure of the Flash web server and of several applications in Ninja, SEDA, and TinyOS [8,12,16,17]. In all cases, the control flow patterns used by these applications fell into three simple categories: call/return, parallel calls, and pipelines. All of these patterns can be expressed more naturally with threads.
We believe more complex patterns are not used because they are difficult to use well. The accidental non-linearities that often occur in event systems are already hard to understand, leading to subtle races and other errors. Intentionally complicated control flow is equally error prone.
Indeed, it is no coincidence that common event patterns map cleanly onto the call/return mechanism of threads. Robust systems need acknowledgements for error handling, for storage deallocation, and for cleanup; thus, they need a “return” even in the event model.
The only patterns we considered that are less graceful with threads are dynamic fan-in and fan-out; such patterns might occur with multicast or publish/subscribe applications. In these cases, events are probably more natural. However, none of the high-concurrency servers that we studied used these patterns.
Synchronization. Criticism: Thread synchronization mechanisms are too heavyweight. Event systems often claim as an advantage that cooperative multitasking gives them synchronization “for free,” since the runtime system does not need to provide mutexes, handle wait queues, and so on [11]. However, Adya et al. [1] show that this advantage is really due to cooperative multitasking (i.e., no preemption), not events themselves; thus, cooperative thread systems can reap the same benefits. It is important to note that in either regime, cooperative multitasking only provides “free” synchronization on uniprocessors, whereas many high-concurrency servers run on multiprocessors. We discuss compiler techniques for supporting multiprocessors in Section 4.3.
State Management. Criticism: Thread stacks are an ineffective way to manage live state. Threaded systems typically face a tradeoff between risking stack overflow and wasting virtual address space on large stacks. Since event systems typically use few threads and unwind the thread stack after each event handler, they avoid this problem. To solve this problem in threaded servers, we propose a mechanism that will enable dynamic stack growth; we will discuss this solution in Section 4.
Additionally, event systems encourage programmers to minimize live state at blocking points, since they require the programmer to manage this state by hand. In contrast, thread systems provide automatic state management via the call stack, and this mechanism can allow programmers to be wasteful. Section 4 details our solution to this problem.
Scheduling. Criticism: The virtual processor model provided by threads forces the runtime system to be too generic and prevents it from making optimal scheduling decisions. Event systems are capable of scheduling event deliveries at application level. Hence, the application can perform shortest remaining completion time scheduling, favor certain request streams, or perform other optimizations. There has also been some evidence that events allow better code locality by running several of the same kind of event in a row [9]. However, Lauer-Needham duality indicates that we can apply the same scheduling tricks to cooperatively scheduled threads.
The above arguments show that threads can perform at least as well as events for high concurrency and that there are no substantial qualitative advantages to events. The absence of scalable user-level threads has provided the largest push toward the event style, but we have shown that this deficiency is an artifact of the available implementations rather than a fundamental property of the thread abstraction.
Up to this point, we have largely argued that threads and events are equivalent in power and that threads can in fact perform well with high concurrency. In this section, we argue that threads are actually a more appropriate abstraction for high-concurrency servers. This conclusion is based on two observations about modern servers. First, the concurrency in modern servers results from concurrent requests that are largely independent. Second, the code that handles each request is usually sequential. We believe that threads provide a better programming abstraction for servers with these two properties.
Control Flow. For these high-concurrency systems, event-based programming tends to obfuscate the control flow of the application. For instance, many event systems “call” a method in another module by sending an event and expect a “return” from that method via a similar event mechanism. In order to understand the application, the programmer must mentally match these call/return pairs, even when they are in different parts of the code. Furthermore, these call/return pairs often require the programmer to manually save and restore live state. This process, referred to as “stack ripping” by Adya et al. [1], is a major burden for programmers who wish to use event systems. Finally, this obfuscation of the program's control flow can also lead to subtle race conditions and logic errors due to unexpected message arrivals.
Thread systems allow programmers to express control flow and encapsulate state in a more natural manner. Syntactically, thread systems group calls with returns, making it much easier to understand cause/effect relationships, and ensuring a one-to-one relationship. Similarly, the run-time call stack encapsulates all live state for a task, making existing debugging tools quite effective.
Exception Handling and State Lifetime. Cleaning up task state after exceptions and after normal termination is simpler in a threaded system, since the thread stack naturally tracks the live state for that task. In event systems, task state is typically heap allocated. Freeing this state at the correct time can be extremely difficult because branches in the application's control flow (especially in the case of error conditions) can cause deallocation steps to be missed.
Many event systems, such as Ninja and SEDA, use garbage collection to solve this problem. However, previous work has found that Java's general-purpose garbage collection mechanism is inappropriate for high-performance systems [14]. Inktomi's Traffic Server used reference counting to manage state, but maintaining correct counts was difficult, particularly for error handling.2
Existing Systems. The preference for threads is subtly visible even in existing event-driven systems. For example, our own Ninja system [16] ended up using threads for the most complex parts, such as recovery, simply because it was nearly impossible to get correct behavior using events (which we tried first). In addition, applications that didn't need high concurrency were always written with threads, just because it was simpler. Similarly, the FTP server in Harvest uses threads [4].
Just Fix Events? One could argue that instead of switching to thread systems, we should build tools or languages that address the problems with event systems (i.e., reply matching, live state management, and shared state management). However, such tools would effectively duplicate the syntax and run-time behavior of threads. As a case in point, the cooperative task management technique described by Adya et al. [1] allows users of an event system to write thread-like code that gets transformed into continuations around blocking calls. In many cases, fixing the problems with events is tantamount to switching to threads.
Tighter integration between compilers and runtime systems is an extremely powerful concept for systems design. Threaded systems can achieve improved safety and performance with only minor modifications to existing compilers and runtime systems. We describe how this synergy can be used both to overcome limitations in current threads packages and to improve safety, programmer productivity, and performance.
To evaluate the ability of threads to support high concurrency, we designed and implemented a simple (5000 line) user-level cooperative threading package for Linux. Our thread package uses the coro coroutine library [15] for minimalist context switching, and it translates blocking I/O requests to asynchronous requests internally. For asynchronous socket I/O, we use the UNIX poll() system call, whereas asynchronous disk I/O is provided by a thread pool that performs blocking I/O operations. The library also overrides blocking system calls and provides a simple emulation of pthreads, which allows applications written for our library to compile unmodified with standard pthreads.
With this thread package we wrote a 700-line test web server, Knot. Knot accepts static data requests, allows persistent connections, and includes a basic page cache. The code is written in a clear, straightforward threaded style and required very little performance tuning.
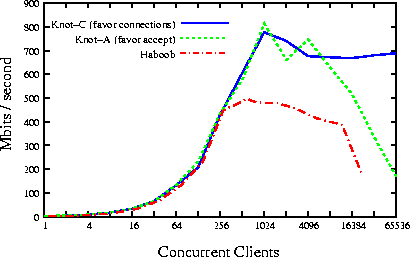
We compared the performance of Knot to that of SEDA's event-driven web server, Haboob, using the test suite used to evaluate SEDA [17]. The /dev/poll patch used for the original Haboob tests has been deprecated, so our tests of Haboob used standard UNIX poll() (as does Knot). The test machine was a 2x2000 MHz Xeon SMP with 1 GB of RAM running Linux 2.4.20. The test uses a small workload, so there is little disk activity. We ran Haboob with the 1.4 JVM from IBM, with the JIT enabled. Figure 3 presents the results.
|
We tested two different scheduling policies for Knot, one that favors processing of active connections over accepting new ones (Knot-C in the figure) and one that does the reverse (Knot-A). The first policy provides a natural throttling mechanism by limiting the number of new connections when the server is saturated with requests. The second policy was designed to create higher internal concurrency, and it more closely matches the policy used by Haboob.
Figure 3 shows that Knot and Haboob have the same general performance pattern. Initially, there is a linear increase in bandwidth as the number of simultaneous connections increases; when the server is saturated, the bandwidth levels out. The performance degradation for both Knot-A and Haboob is due to the poor scalability of poll(). Using the newer sys_epoll system call with Knot avoids this problem and achieves excellent scalability. However, we have used the poll() result for comparison, since sys_epoll is incompatible with Haboob's socket library. This result shows that a well-designed thread package can achieve the same scaling behavior as a well-designed event system.
The steady-state bandwidth achieved by Knot-C is nearly 700 Mbit/s. At this rate, the server is apparently limited by interrupt processing overhead in the kernel. We believe the performance spike around 1024 clients is due to lower interrupt overhead when fewer connections to the server are being created.
Haboob's maximum bandwidth of 500 Mbit/s is significantly lower than Knot's, because Haboob becomes CPU limited at 512 clients. There are several possible reasons for this result. First, Haboob's thread-pool-per-handler model requires context switches whenever events pass from one handler to another. This requirement causes Haboob to context switch 30,000 times per second when fully loaded--more than 6 times as frequently as Knot. Second, the proliferation of small modules in Haboob and SEDA (a natural outgrowth of the event programming model) creates a large number of module crossings and queuing operations. Third, Haboob creates many temporary objects and relies heavily on garbage collection. These challenges seem deeply tied to the event model; the simpler threaded style of Knot avoids these problems and allows for more efficient execution. Finally, event systems require various forms of run-time dispatch, since the next event handler to execute is not known statically. This problem is related to the problem of ambiguous control flow, which affects performance by reducing opportunities for compiler optimizations and by increasing CPU pipeline stalls.
Ousterhout [11] made the most well-known case in favor of events, but his arguments do not conflict with ours. He argues that programming with concurrency is fundamentally difficult, and he concludes that cooperatively scheduled events are preferable (for most purposes) because they allow programmers to avoid concurrent code in most cases. He explicitly supports the use of threads for true concurrency, which is the case in our target space. We also agree that cooperative scheduling helps to simplify concurrency, but we argue that this tool is better used in the context of the simpler programming model of threads.
Adya et al. [1] cover a subset of these issues better than we have. They identify the value of cooperative scheduling for threads, and they define the term “stack ripping” for management of live state. Our work expands on these ideas by exploring thread performance issues and compiler support techniques.
SEDA is a hybrid approach between events and threads, using events between stages and threads within them [17]. This approach is quite similar to the message-passing model discussed by Lauer and Needham [10], though Lauer and Needham advocate a single thread per stage in order to avoid synchronization within a stage. SEDA showed the value of keeping the server in its operating range, which it did by using explicit queues; we agree that the various queues for threads should be visible, as they enable better debugging and scheduling. In addition, the stage boundaries of SEDA provide a form of modularity that simplifies composition in the case of pipelines. When call/return patterns are used, such boundaries require stack ripping and are better implemented with threads using blocking calls.
Many of the techniques we advocate for improving threads were introduced in previous work. Filaments [7] and NT's Fibers are good examples of cooperative user-level threads packages, although neither is targeted at large numbers of blocking threads. Languages such as Erlang [2] and Concurrent ML [13] include direct support for concurrency and lightweight threading. Bruggeman et al. [3] employ dynamically linked stacks to implement one-shot continuations, which can in turn be used to build user-level thread packages. Our contribution is to bring these techniques together in a single package and to make them accessible to a broader community of programmers.
Although event systems have been used to obtain good performance in high concurrency systems, we have shown that similar or even higher performance can be achieved with threads. Moreover, the simpler programming model and wealth of compiler analyses that threaded systems afford gives threads an important advantage over events when writing highly concurrent servers. In the future, we advocate tight integration between the compiler and the thread system, which will result in a programming model that offers a clean and simple interface to the programmer while achieving superior performance.
We would like to thank George Necula, Matt Welsh, Feng Zhou, and Russ Cox for their helpful contributions. We would also like to thank the Berkeley Millennium group for loaning us the hardware for the benchmarks in this paper. This material is based upon work supported under a National Science Foundation Graduate Research Fellowship, and under the NSF Grant for Millennium, EIA-9802069.
This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -no_math -no_navigation -local_icons -address jrvb@cs.berkeley.edu -split 0 -reuse 0 threads-hotos-2003.tex
The translation was initiated by J. Robert von Behren on 2003-06-17
|
This paper was originally published in the
Proceedings of HotOS IX: The 9th Workshop on Hot Topics in Operating Systems,
May 18–21, 2003,
Lihue, Hawaii, USA
Last changed: 26 Aug. 2003 aw |
|