We experimented with identical workloads accessing 16 GB virtual disks
from four hosts with equal ![]() values. This is similar to the setup
that led to divergent behavior in Figure 3. Using
our filesystem-based aggregation, PARDA converges as desired, even in
the presence of different latency values observed by hosts.
Table 3 presents results for
this workload without any control, and with PARDA using equal shares
for each host; plots are omitted due to space constraints. With PARDA,
latencies drop, making the overall average close to the target
values. This is similar to the setup
that led to divergent behavior in Figure 3. Using
our filesystem-based aggregation, PARDA converges as desired, even in
the presence of different latency values observed by hosts.
Table 3 presents results for
this workload without any control, and with PARDA using equal shares
for each host; plots are omitted due to space constraints. With PARDA,
latencies drop, making the overall average close to the target
![]() . The aggregate throughput achieved by all hosts is
similar with and without PARDA, exhibiting good work-conserving
behavior. This demonstrates that the algorithm works correctly in the
simple case of equal shares and uniform workloads.
. The aggregate throughput achieved by all hosts is
similar with and without PARDA, exhibiting good work-conserving
behavior. This demonstrates that the algorithm works correctly in the
simple case of equal shares and uniform workloads.
|
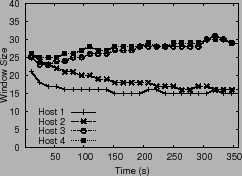
Next, we experimented with a share ratio of ![]() for four hosts,
setting
for four hosts,
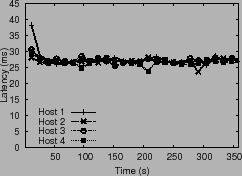
setting ![]() = 25 ms, shown in Figure 8. PARDA
converges on windows sizes for hosts 1 and 2 that are roughly half
those for hosts 3 and 4, demonstrating good fairness. The algorithm
also successfully converges latencies to
= 25 ms, shown in Figure 8. PARDA
converges on windows sizes for hosts 1 and 2 that are roughly half
those for hosts 3 and 4, demonstrating good fairness. The algorithm
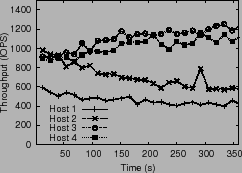
also successfully converges latencies to ![]() . Finally, the
per-host throughput levels achieved while running this uniform
workload also roughly match the specified share ratio. The remaining
differences are due to some hosts obtaining better throughput from the
array, even with the same window size. This reflects the true IO
costs as seen by the array scheduler; since PARDA operates on window
sizes, it maintains high efficiency at the array.
. Finally, the
per-host throughput levels achieved while running this uniform
workload also roughly match the specified share ratio. The remaining
differences are due to some hosts obtaining better throughput from the
array, even with the same window size. This reflects the true IO
costs as seen by the array scheduler; since PARDA operates on window
sizes, it maintains high efficiency at the array.
Ajay Gulati 2009-01-14