
Larry Huston,![]() Rahul Sukthankar,
Rahul Sukthankar,![]() Rajiv Wickremesinghe,
Rajiv Wickremesinghe,![]() M.Satyanarayanan,
M.Satyanarayanan,![]() Gregory R.Ganger,
Gregory R.Ganger,![]() Erik Riedel,
Erik Riedel,![]() Anastassia Ailamaki
Anastassia Ailamaki![]()
![]() Intel Research Pittsburgh,
Intel Research Pittsburgh,
![]() Carnegie Mellon University,
Carnegie Mellon University,
![]() Duke University,
Duke University,
![]() Seagate Research
Seagate Research
Our goal is to enable interactive search of non-indexed data, where the user wishes to retrieve a small set of important items buried in a large collection. For instance, consider a surveillance scenario where an analyst is monitoring satellite imagery for interesting activity around oil tankers. Current image processing algorithms may be able to automatically discard images that do not contain oil tankers, but they cannot detect ``interesting activity''. Filtering the data allows the analyst to focus attention on the promising candidates by significantly reducing the number of irrelevant items. To make such systems practical, new techniques for scanning large volumes of data are needed. We believe that the solution lies in early discard, the ability to discard irrelevant data items as quickly and efficiently as possible (e.g., at the storage device rather than close to the user). We have developed a storage architecture and programming model called Diamond that embodies early discard. Diamond has been designed to run on an active disk [1,20,25] platform, but does not depend on the availability of active storage devices. It can be realized using diverse storage back ends ranging from emulated active disks on a general-purpose cluster to storage nodes on a wide-area network.
This paper focuses on pure brute-force interactive search (i.e., where all of the data is processed for each query). Studying this extreme case enables us to determine the feasibility of early discard in a worst-case setting. Future Diamond implementations could incorporate performance optimizations such as caching results from previous queries and exploiting indices to reduce the search time.
This paper is organized as follows. Section 2 introduces early discard. Section 3 presents the Diamond architecture. Section 4 describes a proof-of-concept application and an informal user study. Section 5 discusses implementation details. Section 6 presents experimental results. Section 7 summarizes related work. Finally, Section 8 concludes the paper.
The standard approach to efficient interactive search is to create an offline index of the data. Indexing assumes that the mapping between the user's query and the relevant data can be pre-computed, enabling the system to efficiently organize data so that only a small fraction is accessed during a particular search. Unfortunately, indexing complex data remains a challenging problem for several reasons. First, manual indexing is often infeasible for large datasets and automated methods for extracting the semantic content from many data types are still rather primitive (the semantic gap [23]). Second, the richness of the data often requires a high-dimensional representation that is not amenable to efficient indexing (a consequence of the curse of dimensionality [33,6,9]). Third, realistic user queries can be very sophisticated, requiring a great deal of domain knowledge that is often not available to the system for optimization. Fourth, expressing the user's needs in a usable form can be extremely difficult (e.g., ``I need a photo of an energetic puppy playing with a happy toddler''). All of these problems limit the usability of interactive data analysis [15] today.
Figure 1(a) shows the traditional architecture for exhaustive search. Each data item passes through a pipeline from the disk surface, through the disk logic, over an interconnect to the host computer's memory. The search application can reject some of the data before presenting the rest to the user. Two problems with this design are: (1) the system is unable to take full advantage of the parallelism at the storage devices; (2) although the user is only interested in a small fraction of the data, all of it must be shipped from the storage devices to the host machine, and the bulk of the data is then discarded in the final stages of the pipeline. This is undesirable because the irrelevant data will often overload the interconnect or host processor.
![\includegraphics[width=\linewidth]{figs/early1-a}](img7.png) (a) Traditional storage architecture
(a) Traditional storage architecture
![\includegraphics[width=\linewidth]{figs/early1-b}](img8.png) (b) Diamond architecture
(b) Diamond architecture
|
Early discard is the idea of rejecting irrelevant data as early in the pipeline as possible. For instance, by exploiting active storage devices, one could eliminate a large fraction of the data before it was sent over the interconnect, as shown in Figure 1(b). Unfortunately, the storage device cannot determine the set of irrelevant objects a priori -- the knowledge needed to recognize the useful data is only available to the search application (and the user). However, if one could imbue some of the earlier stages of the pipeline with a portion of the intelligence of the application (or the user), exhaustive search would become much more efficient. This is supported by our experiments, as described in Section 6.3.
For most real-world applications, the sophistication of user queries outpaces the development of algorithms that can understand complex, domain-dependent data. For instance, in a homeland security context, state-of-the-art algorithms can reliably discard images that do not contain human faces. However, face recognition software has not advanced to the point where it can reliably recognize photos of particular individuals. Thus, we believe that a large fraction of exhaustive search tasks will be interactive in nature. Unlike a typical web search, an interactive brute-force search through a large dataset could demand hours (rather than seconds) of focused attention from the user. For example, a biochemist might be willing to spend an afternoon in interactive exploration seeking a protein matching a new hypothesis. It is important for such applications to consider the human as the most important stage in the pipeline. Effective management of the user's limited bandwidth becomes crucial as the size and complexity of the data grows. Early discard enables the system to eliminate clearly useless data items early in the pipeline. The scarcest resource, human attention, can be directed at the most promising data items.
Ideally, early discard would reject all of the irrelevant data at the storage device without eliminating any of the desired data. This is impossible in practice for two reasons. First, the amount of computation available at the storage device may be insufficient to perform all of the necessary (potentially expensive) application-specific computations. Second, there is a fundamental trade-off [9] between false-positives (irrelevant data that is not rejected) and false-negatives (good data that is incorrectly discarded). Early discard algorithms can be tuned to favor one at the expense of the other, and different domain applications will make different trade-offs. For instance, an advertising agency searching a large collection of images may wish to quickly find a photo that matches a particular theme and may choose aggressive filtering; conversely, a homeland security analyst might wish to reduce the chance of accidentally losing a relevant object and would use more conservative filters (and accept the price of increased manual scanning). It is important to note that early discard does not, by itself, impact the accuracy of the search application: it simply makes applications that filter data more efficient.
The idea of performing specialized computation close to the data is not a new concept. Database machines [17,7] advocated the use of specialized processors for efficient data processing. Although these ideas had significant technical merit, they failed, at the time, because designing specialized processors that could keep pace with the sustained increase in general-purpose processor speed was commercially impractical.
More recently, the idea of an active disk [1,20,25], where a storage device is coupled with a general-purpose processor, has become popular. The flexibility provided by active disks is well-suited to early discard; an active disk platform could run filtering algorithms for a variety of search domains, and could support applications that dynamically adapt the balance of computation between storage and host as the location of the search bottleneck changes [2]. Over time, due to hardware upgrades, the balance of processing power between the host computer and storage system may shift. In general, a system should expect a heterogeneous composition of computational capabilities among the storage devices as newer devices may have more powerful processors or more memory. The more capable devices could execute more demanding early discard algorithms, and the partitioning of computation between the devices and the host computer should be managed automatically. Analogously, when the interconnect infrastructure or host computer is upgraded, one may expect computation to shift away from the storage devices. To be successful over the long term, the design needs to be self-tuning; manual re-tuning for each hardware change is impractical.
In practice, the best partitioning will depend on the characteristics of the processors, their load, the type and distribution of the data, and the query. For example, if the user were to search a collection of holiday pictures for snowboarding photos, these might be clustered together on a small fraction of devices, creating hotspots in the system.
Diamond provides two mechanisms to support these diverse storage system configurations. The first allows an application to generate specialized early discard code that matches each storage device's capabilities. The second enables the Diamond system to dynamically adapt the evaluation of early discard code, and is the focus of this paper. In particular, we explore two aspects of early discard: (1) adaptive partitioning of computation between the storage devices and the host computer based on run-time measurements; (2) dynamic ordering of search terms to minimize the total computation time.
Diamond exploits several simplifications inherent to the search domain. First, search tasks only require read access to data, allowing Diamond to avoid locking complexities and to ignore some security issues. Second, search tasks typically permit stored objects to be examined in any order. This order-independence offers several benefits: easy parallelization of early discard within and across storage devices, significant flexibility in scheduling data reads, and simplified migration of computation between the active storage devices and host computer. Third, most search tasks do not require maintaining state between objects. This ``stateless'' property supports efficient parallelization of early discard, and simplifies the run-time migration of computation between active storage device and host computer.
Diamond applications aim to reduce the load on the user by eliminating irrelevant data using domain-specific knowledge. Query formulation is domain-specific and is handled by the search application at the front end. Once a search has been formulated, the application translates the query into a set of machine executable tasks (termed a searchlet) for eliminating data, and passes these to the back end. The searchlet contains all of the domain-specific knowledge needed for early discard, and is a proxy of the application (and of the user) that can execute within the back end.
Searchlets are transmitted to the back end through the searchlet API, and distributed to the storage devices. At each storage device, the runtime system iterates through the objects on the disk (in a system-determined order) and evaluates the searchlet. The searchlet consists of a set of filters (see Section 5), each of which can independently discard objects. Objects that pass through all filters in a searchlet are deemed interesting, and made available to the domain application through the searchlet API.
The domain application may perform further processing on the interesting objects to see if they satisfy the user's request. This additional processing can be more general than the processing performed at the searchlet level (which was constrained to the independent evaluation of a single object). For instance, the additional processing may include cross-object correlations and auxiliary databases. Once the domain application determines that a particular object matches the user's criteria, the object is shown to the user. When processing a large data set, it is important to present the user with results as soon as they appear. Based on these partial results, the user can refine the query and restart the search. Query refinement leads to the generation of a new searchlet, which is once again executed by the back end.
The searchlet is an application-specific proxy that Diamond uses to implement early discard. It consists of a set of filters and some configuration state (e.g., filter parameters and dependencies between filters). For example, a searchlet to retrieve portraits of people in dark business suits might contain two filters: a color histogram filter that finds dark regions and an image processing filter that locates human faces.
For each object, the runtime invokes each of the filters in an efficient order, considering both filter cost and selectivity (see Section 5.2). The return value from each filter indicates whether the object should be discarded, in which case the searchlet evaluation is terminated. If an object passes all of the filters in the searchlet, it is sent to the domain application.
Before invoking the first filter, the runtime makes a temporary copy of the object. This copy exists only until the object is discarded or the search terminates, allowing the filters to share state and computation without compromising the stored object.
One filter can pass state to another filter by adding attributes (implemented as name-value pairs) to the temporary object being searched. The second filter recovers this state by reading these attributes. If the second filter requires attributes written by the first filter, then the configuration must specify that the second filter depends on the first filter. The runtime ensures that filters are evaluated in an order that satisfies their dependencies.
The filter functions are sent as object code to Diamond. This choice of object code instead of alternatives, such as domain-specific languages, was driven by several factors. First, many real-world applications (e.g., drug discovery) may contain proprietary algorithms where requiring source code is not an option. Second, we want to encourage developers to leverage existing libraries and applications to simplify the development process. For instance, our image retrieval application (described in Section 4) relies heavily on the OpenCV [8] image processing library.
Executing application-provided object code raises serious security and safety implications that are not specifically addressed by the current implementation. Existing techniques, such as processes, virtual machines, or software fault isolation [31], could be incorporated into future implementations. Additionally, Diamond never allows searchlets to modify the persistent (on-disk) data.
Searchlets can be generated by a domain application in response to a user's query in a number of ways. The most straightforward method is for domain experts to implement a library of filter functions that are made available to the application. The user specifies a query by selecting the desired filters and setting their parameters (typically using a GUI). The application determines filter dependencies and assembles the selected functions and parameters into a searchlet. This works well for domains where the space of useful early discard algorithms is well spanned by a small set of functions (potentially augmented by a rich parameter space). These functions could also be provided (in binary form) by third-parties.
Alternately, the domain application could generate code on-the-fly in response to the user's query. One could envision an application that allows the user to manually generate searchlet code. We believe that the best method for searchlet creation is highly domain-dependent, and the best way for a human to specify a search is an open research question.
The Diamond architecture defines three APIs to isolate components: the searchlet API, the filter API and associative DMA. These are briefly summarized below.
The host system is where the domain application executes. The user interacts with this application to formulate searches and to view results. Diamond attempts to balance computation between the host and storage systems. To facilitate this, storage devices may pass unprocessed objects to the host runtime, due to resource limitations or other constraints. The host runtime evaluates the searchlet, if necessary; if the object is not discarded, it is made available to the domain application. The storage system provides a generic infrastructure for searchlet execution; all of the domain-specific knowledge is completely encapsulated in the searchlet. This enables the same Diamond back-end to serve different domain applications (simultaneously, if necessary).
Diamond is well-suited for deployment on active storage, but such devices are not commercially available today, nor are they likely to become popular without compelling applications. Diamond provides a programming model that abstracts the storage system, enabling the development of applications that will seamlessly integrate with active storage devices as they become available.
Diamond's current design assumes that the storage system can be treated as object storage [30]. This allows the host to be independent of the data layout on the storage device and should allow us to leverage the emerging object storage industry standards.
Given a target protein, a chemist must search through a large database of 3D ligand structures to identify candidates that may associate strongly with the target. Since accurate calculation of the binding free energy of a particular ligand is prohibitively expensive, such programs could benefit from user input to guide the search in two ways. First, the chemist could adjust the granularity of the search (trading accuracy for speed). Second, the chemist could test hypotheses about a particular ligand-protein interaction using interactive molecular dynamics [14]. In Diamond, the former part of the search could be downloaded to the storage device while the latter could be performed on the chemist's graphical workstation. Early discard would reject hopeless ligands from consideration allowing the chemist to focus attention on the more promising candidates. If none of the initial candidates proved successful, the chemist would refine the search to be less selective. This example illustrates some of the characteristics that make an application suitable for early discard. First, that the user is searching for specific instances of data that match a query rather than aggregate statistics about the set of matching data items. Second, that the user's criteria for a successful match is often subjective, potentially ill-defined, and typically influenced by the partial results of the query. Third, that the mapping between the user's needs and the matching objects is too complex for it to be captured by a batch operation. An everyday example of such a domain is image search; the remainder of this section presents SnapFind, a prototype application for this domain built using the Diamond programming model.
SnapFind was motivated by the observation that digital cameras allow users to generate thousands of photos, yet few users have the patience to manually index them. Users typically wish to locate photos by semantic content (e.g., ``show me photos from our whale watching trip in Hawaii''); unfortunately, computer vision algorithms are currently incapable of understanding image content to this degree of sophistication. SnapFind's goal is to enable users to interactively search through large collections of unlabeled photographs by quickly specifying searchlets that roughly correspond to semantic content.
Research in image retrieval has attracted considerable attention in recent years [11,29]. However, prior work in this area has largely focused on whole-image searches. In these systems, images are typically processed off-line and compactly represented as a multi-dimensional vector. In other systems, images are indexed offline into several semantic categories. These enable users to perform interactive queries in a computationally-efficient manner; however, they do not permit queries about local regions within an image since indexing every subregion within an image would be prohibitively expensive. Thus, whole-image searches are well-suited to queries corresponding to general image content (e.g., ``find me an image of a sunset'') but poor at recognizing objects that only occupy a portion of the image (e.g., ``find me images of people wearing jeans''). SnapFind exploits Diamond's ability to exhaustively process a data set using customized filters, enabling users to search for images that contain the desired content only in a small patch. The remainder of this section describes SnapFind and presents an informal validation of early discard.
SnapFind allows users to create complex image queries by combining simple filters that scan images for patches containing particular color distributions, shapes, or visual textures (detailed in a technical report [19]). The user can either select a pre-defined filter from a palette (e.g., ``frontal human faces'' or ``ocean waves'') or create new filters by clicking on sample patches in other images (e.g., creating a ``blue jeans'' color filter by giving half a dozen examples). Indexing is infeasible for two reasons: (1) the user may define new search filters at query time; (2) the content of the patches is typically high-dimensional. When the user submits the query, SnapFind generates a searchlet and initiates a Diamond search. Diamond typically executes a portion of the query at the storage device, enabling early discard to reject many images in the initial stages of the pipeline.
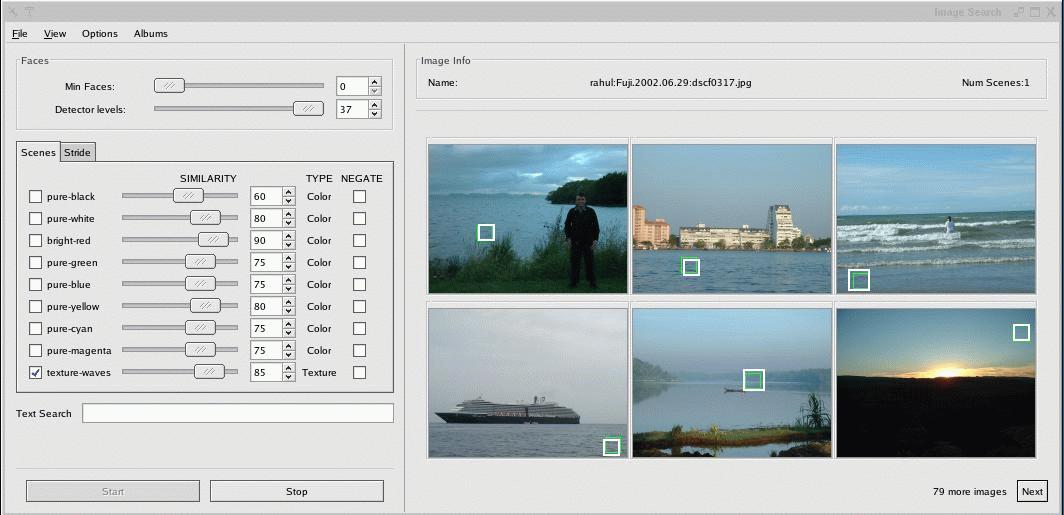
We designed some simple experiments to investigate whether early discard can help exhaustive search. Our chosen task was to retrieve photos from an unlabeled collection based on semantic content. This is a realistic problem for owners of digital cameras and is also one that untrained users can perform manually (given sufficient patience). We explored two cases: (1) purely manual search, where all of the discard happens at the user stage; (2) using SnapFind. Both scenarios used the same graphical interface (see Figure 3), where the user could examine six thumbnails per page, magnify a particular image (if desired) and mark selected images.
|
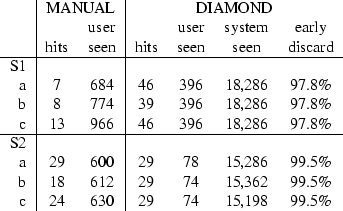
Our data set contained 18,286 photographs (approximately 10,000 personal pictures, 1,000 photos from a corporate website, 5,000 images collected from an ethnographic survey and 2,000 from the Corel image CD-ROMs). These were randomly distributed over twelve emulated active storage devices. Users were given three minutes to tackle each of the following two queries: (S1) find images containing windsurfers or sailboats; (S2) find pictures of people wearing dark business suits or tuxedos.
For the manual scenario, we recorded the number of images selected by the user (correct hits matching the query) along with the number of images that the user viewed in the alloted time. Users could page through the images at their own pace, and Table 1 shows that users scanned the images rapidly, viewing 600-1,000 images in three minutes. Even at this rate of 2-5 images per second, they were only able to process about 5% of the total data.
For the SnapFind scenario, the user constructed early discard
searchlets simply by selecting one or more image processing
filters from a palette of pre-defined filters, configured filter
parameters using the GUI, and combined them using boolean operators.
Images that satisfied the filtering criteria (i.e., those
matching a particular color, visual texture or shape distribution
in a subregion) were shown to the user. Based on partial results,
the user could generate a new searchlet by selecting different
filters or adjusting parameters. As in the manual scenario, the
user then marked those images that matched the query. For S1,
the early discard searchlet was a single ``water texture'' filter
trained on eight 32![]() 32 patches containing water. For S2, the
searchlet was a conjunction of a color histogram filter combined with
a face detector. Table 1 shows these results,
and searchlets are detailed in Table 2.
32 patches containing water. For S2, the
searchlet was a conjunction of a color histogram filter combined with
a face detector. Table 1 shows these results,
and searchlets are detailed in Table 2.
For S1, SnapFind significantly increases the number of relevant images found by the user. Diamond is able to exhaustively search through all of the data, and early discard eliminates almost 98% of the objects at the storage devices. This shows how early discard can help users find a greater number of relevant objects.
For S2, the improvement, as measured by hits alone, is less dramatic, but early discard shows a different benefit. Although Diamond fails to complete the exhaustive search in three minutes (it processes about 85% of the data), the user achieves approximately as many hits as in the manual scenario while viewing 88% fewer images. For applications where the user only needs a few images, early discard is ideal because it significantly decreases the user's effort. By displaying fewer irrelevant items, the user can devote more attention to the promising images.
Our Diamond prototype is currently implemented as user processes running on Red Hat Linux 9.0. The searchlet API and the host runtime are implemented as a library that is linked against the domain application. The host runtime and network communication are threads within this library. We emulate active storage devices using off-the-shelf server hardware with locally-attached disks. The active storage system is implemented as a daemon. When a new search is started, new threads are created for the storage runtime and to handle network and disk I/O. Diamond's object store is implemented as a library that stores objects as files in the native file system. Associative DMA is currently under definition; Diamond uses a wrapper library built on TCP/IP with customized marshalling functions to minimize data copies.
The remainder of this section details Diamond's two primary mechanisms for efficient early discard: run-time partitioning of computation between the host and storage devices, and dynamic ordering of filter evaluation to reject undesirable data items as efficiently as possible.
As discussed in Section 2, bottlenecks in exhaustive search pipelines are not static. Diamond achieves significant performance benefits by dynamically balancing the computational task between the active storage devices and the host processor.
The Diamond storage runtime decides whether to evaluate a searchlet locally or at the host computer. This decision can be different for each object, allowing the system to have fine-grained control over the partitioning. Thus, even for searchlets that consist of a single monolithic filter, Diamond can partition the computation on a per-object basis to achieve the ratio of processing between the storage devices and the host that provides the best performance. The ability to make these fine-grained decisions is enabled by Diamond's assumption that objects can be processed in any order, and that filters are stateless.
If the searchlet consists of multiple filters, Diamond could partition the work so that some filters execute on the storage devices and the remainder execute on the host; the current implementation does not consider such partitionings. Diamond could also detect when there are many objects waiting for user attention and choose to evaluate additional filters to discard more objects.
The current implementation supports two methods for partitioning computation between the host and the storage devices. The effectiveness of these methods in practice is evaluated in Section 6.3.
In this method, the host periodically estimates its available compute resources (processor cycles), determines how to allocate them among the storage devices, and sends a message to each device. The storage device receives this message, estimates its own computational resources, and determines the percentage of objects to process locally. For example, if a storage device estimates that it has 100 MIPS and receives a slice of 50 MIPS from the host, then it should choose to process 2/3 of the objects locally and send the remaining (unprocessed) objects to the host. CPU splitting has a straightforward implementation: whenever the storage runtime reads an object, it probabilistically decides whether to process the object locally.
Queue Back-Pressure (QBP) exploits the observation that the length of queues between components in the search pipeline (see Figure 1) provide valuable information about overloaded resources. The algorithm is implemented as follows.
When objects are sent to the host, they are placed into a work queue that is serviced by the host runtime. If the queue length exceeds a particular threshold, the host refuses to accept new objects. Whenever the storage runtime has an object to process, it examines the length of its transmit queue. If the queue length is less than a threshold, the object is sent to the host without processing. If the queue length is above the threshold, the storage runtime evaluates the searchlet on the object. This algorithm dynamically adapts the computation performed at the storage devices based on the current availability of downstream resources. When the host processor or network is a bottleneck, the storage device performs additional processing on the data, easing the pressure on downstream resources until data resumes its flow. Conversely, if the downstream queues begin to empty, the storage runtime will aggressively push data into the pipeline to prevent the host from becoming idle.
A Diamond searchlet consists of a set of filters, each of which can choose to discard a given object. We assume that the set of objects that pass through a particular searchlet is completely determined by the set of filters in the searchlet (and their parameters). However, the filter order dramatically impacts the efficiency with which Diamond processes a large amount of data.
Diamond attempts to reorder the filters within a searchlet to run the most promising ones early. Note that the best filter ordering depends on the set of filters, the user's query, and the particular data set. For example, consider a user who is searching a large image collection for photos of people in dark suits. The application may determine that a suitable searchlet for this tasks includes two filters (see Table 3): a face detector that matches images containing human faces (filter F1); and a color filter that matches dark regions in the image (filter F3). From the table, it is clear that F1 is more selective than F3, but also much more computationally expensive. Running F1 first would work well if the data set contained a large number of night-time photos (which would successfully pass F3). On the other hand, if the collection contained a large number of baby pictures, running F1 early would be extremely inefficient.
The effectiveness of a filter depends upon its
selectivity (pass rate) and its resource requirements.
The total cost of evaluating filters over an object can be
expressed analytically as follows. Given a filter, Fi ,
let us denote the cost of evaluating the filter as c(Fi) ,
and its pass rate as ![]() . In general, the pass rates
for the different filters may be correlated (e.g.,
if an image contains a patch with water texture, then it is
also more likely to pass through a blue color filter). We denote
the conditional pass rate for a filter Fi that is
processing objects that successfully passed filters Fa , Fb , Fc
by
. In general, the pass rates
for the different filters may be correlated (e.g.,
if an image contains a patch with water texture, then it is
also more likely to pass through a blue color filter). We denote
the conditional pass rate for a filter Fi that is
processing objects that successfully passed filters Fa , Fb , Fc
by ![]() . The average time to process an object
through a series of filters
. The average time to process an object
through a series of filters ![]() is given by the following
formula:
is given by the following
formula:
The primary goal of choosing a filter order is to minimize this cost function. To perform this optimization, the system needs the costs of the different filters and the conditional pass rates. Diamond estimates these values during a searchlet execution by varying the order the filters are evaluated and measuring the pass rates and costs over a number of objects.
Allowing filters to use results generated by other filters enables searchlets to: (1) use generic components to compute well-known properties; (2) reuse the results of other filters. For instance, all of the color filters in SnapFind (see Section 4) rely on a common data structure that is generated by an auxiliary filter. Filter developers can explicitly specify the attributes that each filter requires, and these dependencies are expressed as partial ordering constraints. Figure 4 shows an example of a partial order. The forward arrows indicate an `allows' relationship. For example, ``Reader'' is a prerequisite for ``Histogram'' and ``WaterTexture'', and ``Red'' and ``Black'' are prerequisites for ``ColorTest''. The filter ordering problem is to find a linear extension of the partial order. Figure 5 shows one possible order. Note that finding a path through this directed acyclic graph is not sufficient; all of the filters in the searchlet still need to be evaluated.
![\includegraphics[width=\linewidth]{figs/partial-order}](img16.png)
|
The filter ordering policy is the method that Diamond uses for choosing the sequence for evaluating the filters. We describe three policies below.
|
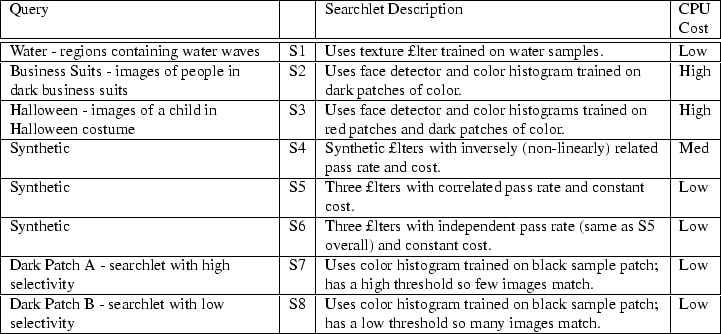
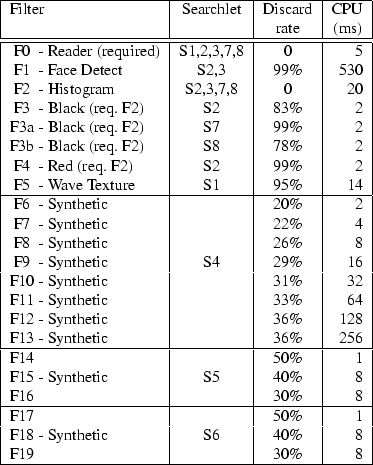
We evaluate Diamond using the set of queries enumerated in Table 2. These consist of real queries from SnapFind searches supplemented by several synthetic queries. The searchlets are described in Table 2, and the filters used by these searchlets are listed in Table 3.
The Water (S1) and Business Suits (S2) queries match the tasks we used in Section 4. The Halloween (S3) query is similar to Business Suits with an additional filter. The three synthetic queries (S4-S6) are used to test filter ordering and the two Dark Patch queries (S7, S8) are used to illustrate bottlenecks for dynamic partitioning.
Table 3 provides a set of measurements summarizing the discard rate and the computational cost of running the various filters. We determined these filter characteristics by evaluating each filter over the objects in our image collection (described in Section 4). The overall discard rate is the fraction of objects dropped divided by the total number of images, and the cost is the average number of CPU milliseconds consumed. Filters F0-F5 are taken from SnapFind. The other filters were synthetically generated with specific characteristics.
|
The searchlets S5 and S6 were designed to examine the effect
of filter correlation. F14, F15 and F16 are correlated:
![]() . F17, F18 and F19
are uncorrelated:
. F17, F18 and F19
are uncorrelated: ![]() .
.
Our first measurements examine how variations in system characteristics (number of storage devices, interconnect bandwidth, processor performance, queries) affect the average time needed to process each object. For each configuration, we measure the completion time for a different static partitioning between the host and storage devices. A particular partition is identified by percentage of objects that are evaluated at the storage devices. Remaining objects are passed to the host for processing.
In these experiments, each storage device has 5,000 objects (1.6 GB). As the number of storage devices increases, so does the total number of objects involved in a search. For each configuration, we report the mean time needed for Diamond to process each object (averaged over three runs). Our data set was chosen to be large enough to avoid startup transients but small enough to enable many different experiments. Using a larger data set would give the same average time per object, but will increase the overall completion time for a search.
The first set of experiments (see Figure 6) shows how variations in the relative processing power of the host and storage devices affect search time for CPU-bound tasks. These experiments use searchlet S3 to find pictures of a child in a Halloween costume.
![\includegraphics[width=\linewidth]{graph/cpu_var}](img25.png)
|
We observe that, as the number of storage devices increases, more computation is moved to the storage devices. This matches our intuition that as the aggregate processing power of the storage devices increases, more of the overall processing should be done at the storage devices.
When there is no processing at the storage devices, this is equivalent to reading all of the data from network storage. On the left-hand side of the lines, we see linear decreases as processing is moved to the storage devices, reducing the load on the bottleneck. When most of the processing moves to the storage device, the bottleneck becomes the storage device and we see increases in average processing time. The best case is the local minimum; this corresponds to the case where the load between the host and the storage devices is balanced. Note that Diamond benefits from active storage even with a small number of storage devices.
Our next measurements (see Figure 7) examine the network-bound case using searchlets S7 and S8. Both searchlets look for a small dark region and are relatively cheap to compute. S7 rejects most of the objects (highly selective) while S8 passes a larger fraction of the objects (non-selective).
![\includegraphics[width=\linewidth]{graph/net_var}](img26.png)
|
These experiments demonstrate that as the network becomes the limiting factor, more computation should be performed at the storage device. We also see that these lines flatten out at the point where reading the data from the disk becomes a bottleneck. The upper two lines show S7 and S8 running on a 100 Mbps network. We see that S8 is always slower, even when all of the computation is performed at the storage device. This is because S8 passes a large percentage of the objects, creating a data transfer bottleneck in all cases.
This section evaluates the effectiveness of the dynamic partitioning algorithms presented in Section 5. As a baseline measurement, we manually find the ideal partitioning based on the results from the previous section. We then compare the time needed to complete the search using this manual partitioning to those for the two dynamically-adjusting schemes: CPU Splitting and Queue Back-Pressure (QBP).
For these tests, we use both a CPU-bound task (searchlet S3) and a network-bound task (searchlet S7). We run each task in a variety of configurations and compare the results as shown in Figure 8.
![\includegraphics[width=\linewidth]{graph/dyn_part}](img27.png)
|
In all of these cases, the QBP technique gives similar performance to the Best Manual technique. CPU Splitting does not perform as well in most of the cases for two reasons. First, in the network-bound task (searchlet S7), the best results are obtained by processing all objects at the storage devices. CPU Splitting always tries to process a fraction of the objects on the host, even when sending data to the host is the bottleneck. QBP detects the network bottleneck and processes the objects locally. Second, relative CPU speeds are a poor estimate of the time needed to evaluate the filters. Most of these searchlets involve striding over large data structures (images) so the computation tends to be bound by memory access, not CPU. As a result, increasing the CPU clock rate does not give a proportional decrease in time. It is possible that more sophisticated modeling would make CPU Splitting more effective. However, given that the simple QBP technique works so well, there is probably little benefit to pursuing that idea.
This section compares the different policies described in Section 5.2.2, and illustrates the significance of filter ordering. We use searchlets S1-S6, which are composed of the filters detailed in Table 3. This experiment eliminates network and host effects by executing entirely on a single storage device and compares different local optimizations. Total time is normalized to the Offline Best policy; this is the best possible static ordering (computed using an oracle), and provides a bound on the minimum time needed to process a particular searchlet. Random picks a random legal linear order at regular intervals. This is the simplest solution that avoids adversarial worst cases without extra state, and would be a good solution if filter ordering did not matter.
![\includegraphics[width=\linewidth]{graph/filterorder}](img28.png)
|
Figure 9 shows that completion time varies significantly with different filter ordering policies. The poor performance of Random demonstrates that filter ordering is significant. There is a unique legal order for S1, and all methods pick it correctly. Independent finds the optimal ordering when filters are independent, as in S6, but can generate expensive orderings when they are not, as in S5. Hill Climbing sometimes performs poorly because it can get trapped in local minima. Best Filter First is a dynamic techniques that works as well as Independent (it has a slightly longer convergence time) with independent filters, and has good performance with dependent filters. The dynamic techniques spend time exploring the search space, so they always pay a penalty over the Offline Best policy. This is more pronounced with more filters, as in S4.
The next experiment examines Diamond performance when dynamic partitioning and filter ordering are run concurrently. For our baseline measurement, we manually find the best partitioning and the best filter ordering for each configuration. We then compare the time needed to execute searchlet S3 against two test cases that use dynamic adaptation. The first uses dynamic partitioning (QBP) and the filter ordering (BFF); the second uses dynamic partitioning (QBP) and randomized filter orders. Figure 10 shows the results of these experiments. As expected, the combination of dynamic partitioning and dynamic filter ordering gives us results that are close to the best manual partitioning. Random filter ordering performs less well because of the longer time needed to process each object.
![\includegraphics[width=\linewidth]{graph/together}](img29.png)
|
To better understand the impact of Diamond on real-world problems, we consider a typical scenario: how much data could a user search in an afternoon? The results from Figure 10 show that Diamond can process 40,000 objects (8 storage devices with 5,000 objects each) in 247 seconds. Thus, given four hours, the user should be able to search through 2.3 million objects (approximately 0.75 TB) using the same searchlets. In the case of searchlet S3, this would imply that the user should see about 115 objects. However, since the number of objects seen by the user is sensitive to search parameters and the distribution of data on the storage device, it could vary greatly from this estimate.
Although raw performance should scale as disks are added, the limitations imposed by the user and the domain application are less clear. For instance, in the drug discovery application described in Section 4, the user's think-time may be the limiting factor even when Diamond discards most of the data. Conversely, in other domains, the average computational cost of a searchlet could be so high that Diamond would be unable to process all of the data in the alloted time. These questions are highly domain-dependent and lie beyond the scope of this paper.
As we discussed in the introduction, the current implementation is focused on pure brute-force search, but other complimentary techniques can be used to improve performance. One technique would be to use pre-computed indices to reduce the number of objects searched. For example, filter F1 from Table 3 could be used to build an index of pictures containing faces. Using this index would reduce the search space by 99% for any searchlets that use filter F2.
Another complimentary technique is to take advantage of cached results. In certain domains, a user may frequently refine a searchlet based on partial results in a manner that leaves most of its filters and their parameters unchanged. For instance, in SnapFind, the user may modify a search by adding a filter to the existing set of filters in the searchlet. When re-executing a filter with the same parameters, Diamond could gain significant computational benefits by retrieving cached results. However, caching may provide very little benefit for other applications. For instance, a Diamond application that employs relevance feedback [16] typically adjusts filter arguments at each iteration based on user-provided feedback. Since the filter arguments are different with each search, the use of cached information becomes more difficult. We plan to evaluate the benefits of caching as we gain more experience with other Diamond applications.
Recent work on interactive data analysis [15] outlines a number of new technologies that will be required to make database systems as interactive as spreadsheets -- requiring advances in databases, data mining and human-computer interaction. Diamond and early discard are complementary to these approaches, providing a basic systems primitive that furthers the promise of interactive data analysis.
In more traditional database research, advanced indexing techniques exist for a wide variety of specific data types including multimedia data [10]. Work on data cubes [13] takes advantage of the fact that many decision support queries are well-known to pre-process a database and then perform queries directly from the more compact representation. The developers of new indexing technology must constantly keep up with new data types, and with new user access and query patterns. A thorough survey of indexing and the outline of this tension appear in a recent dissertation [27], which also details theoretical and practical bounds on the (often high) cost of indexing.
Work on approximate query processing, recently surveyed in [5], complements these efforts by observing that users can often be satisfied with approximate answers when they are simply using query results to iterate through a search problem, exactly as we motive in our interactive search tasks.
In addition, in high-dimensionality data (such as feature vectors extracted from images to support indexing), sequential scanning is often competitive with even the most advanced indexing methods because of the curse of dimensionality [33,6,9]. Efficient algorithms for approximate nearest neighbor in certain high-dimensional spaces, such as locality-sensitive hashing [12], are available. However, these require the similarity metric be known in advance (so that the data can be appropriately pre-indexed using the proximity-preserving hashing functions) and that the similarity metric satisfy certain properties. Diamond addresses searches where neither of these constraints is satisfied.
In systems research, our work builds on the insight of active disks [1,20,25] where the movement of search primitives to extended-function storage devices was analyzed in some detail, including for image processing applications. Additional research has explored methods to improve application performance using active storage [21,22,26,32]. The work of Abacus [2], Coign [18], River [3] and Eddies [4] provide a more dynamic view in heterogeneous systems with multiple applications or components operating at the same time. Coign focuses on communication links between application components. Abacus automatically moves computation between hosts or storage devices in a cluster based on performance and system load. River handles adaptive dataflow control generically in the presence of failures and heterogeneous hardware resources. Eddies [4] adaptively reshapes dataflow graphs to maximize performance by monitoring the rates at which data is produced and consumed at nodes. The importance of filter ordering has also been the object of research in database query optimization [28]. The addition of early discard and filter ordering bring a new set of semantic optimizations to all of these systems, while retaining the basic model of observation and adaptation while queries are running.
Recent efforts to standardize object-based storage devices (OSD) [30] provide the basic primitives on which we build our semantic filter processing. In order to most efficiently process searchlets, active storage devices must contain whole objects, and must understand the low-level storage layout. We can also make use of the attributes that can be associated with objects to store intermediate filter state and to save filter results for possible re-use in future queries. Offloading space management to storage devices provides the basis for understanding data in the more sophisticated ways necessary for early discard filters to operate.
To validate our architecture, we have implemented a prototype version of Diamond and an application, SnapFind, that interactively searches collections of digital images. Using this system, we have demonstrated that searching large collections of images is feasible and that the system can dynamically adapt to use the available resources such as network and host processor efficiently.
In the future, we plan to work with domain experts to create new interactive search applications such as ligand screening or satellite imagery analysis. Using these applications, we plan to validate our approach to interactive search of large real-world datasets.
Thanks to: Derek Hoiem and Padmanabham (Babu) Pillai for their valuable help with the Diamond system; Genevieve Bell and David Westfall for contributing data for the SnapFind user study; Ben Janesko and David Yaron for useful discussions on applying Diamond to computational chemistry problems; our shepherd, Christos Karamanolis for all his help; and the anonymous reviewers for feedback on an earlier draft of the paper.
![\includegraphics[width=\linewidth]{overview_pic}](img9.png)
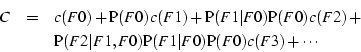
![\includegraphics[width=\linewidth]{figs/total-order}](img17.png)