
This section gives an overview of our methodology for evaluating Circus, including the performance metrics of our experiments.
We incorporated the Circus algorithm into a version of the FTP daemon of FreeBSD Release 4.5 (Figure 6). We modified both the FTP client and server to support block reordering using a simple block transfer protocol with sequencing headers.
The current version of the Circus server is a fully functional implementation that required no kernel modifications. For each active file the server constructs a header structure (file header) containing information about the file. This includes a linked list of headers (client headers) for the active clients of each file, and a block FIFO queue of limited length for each active client. The block size is a configurable parameter that serves as logical unit of disk and network transfers. When the socket buffer for a client is ready to send, a server process removes a block descriptor from the queue, and submits a request to transfer the block to the network socket. We used the sendfile() system call--available in FreeBSD and other operating system kernels--for zero-copy transfers from the disk to the network. A background process runs the block selection algorithm to refill the FIFO queues with descriptors of blocks to transmit to each client. The headers and the queues are maintained in shared memory accessible by all server processes.
The modified FTP client reassembles downloaded files and optionally writes them to the local file system on the client. We disabled the writes in our experiments so that multiple clients (up to a few hundred) could run on each test machine.
We define disk throughput as the total disk bandwidth (byte/s) used by the server, and network throughput as the total network bandwidth (byte/s) used to send data over the network to clients (with unicast). We can approximate the miss ratio from the ratio of disk throughput to the network throughput, ignoring locality effects. A low ratio indicates that disk block fetches are contributing to multiple outstanding transfers for a shared file. The reduced disk activity can improve download time and server throughput (the download completion rate).
We assume Poisson arrivals for the download requests because they
closely match real workloads studied in previous work
[3].
For the definition of the system load ![]() during steady-state operation, we take the
delivered network throughput as the aggregate transfer rate
requested by the users;
ideally, each download request should be served at the client's
network link rate. Based on the analysis of Section 2, we consider the
server's network bandwidth to be the limiting resource:
maximum system load
during steady-state operation, we take the
delivered network throughput as the aggregate transfer rate
requested by the users;
ideally, each download request should be served at the client's
network link rate. Based on the analysis of Section 2, we consider the
server's network bandwidth to be the limiting resource:
maximum system load ![]() occurs when the arrival rate
generates network throughput that saturates
the server's network link. Depending on the file sizes,
this load definition leads to
different request arrival rates and different
interarrival gaps. We derive the mean request interarrival
time corresponding to the maximum system load from the ratio of the
average file size over the outgoing server link
capacity. For lower loads, the interarrival gap is
the ratio of the peak load interarrival time to the
load level
occurs when the arrival rate
generates network throughput that saturates
the server's network link. Depending on the file sizes,
this load definition leads to
different request arrival rates and different
interarrival gaps. We derive the mean request interarrival
time corresponding to the maximum system load from the ratio of the
average file size over the outgoing server link
capacity. For lower loads, the interarrival gap is
the ratio of the peak load interarrival time to the
load level ![]() .
.
All experiments use Intel PIII-based systems with 256 MB main memory running FreeBSD 4.5 at 733 MHz or 866 MHz. A group of client workstations run multiple client instances to generate request loads to a server. On the server node, we use Dummynet [25] to specify the per flow transfer rate from the server node to each client (Figure 7). We store the file data in a 18GB Seagate Cheetah 10K RPM disk with sequential transfer rate 26-40MByte/s. The systems are equipped with both 100 Mbit/s and 1 Gbit/s Ethernet interfaces connected via two separate switches. File network transfers take place over the gigabit switch using jumbo Ethernet packets (9000 bytes) to reduce network protocol overhead.
We focus on handling download requests of files with total storage footprint that exceeds the memory of the server. Most of our experiments use files of size 512MB. Our results also apply when files fit in server memory but the aggregate footprint exceeds server memory. Due to reported correlations between the transferred file size and the client link capacity [31], and to reduce experimentation time, we conservatively consider clients with broadband transfer rates. For each different client link capacity that we support, we dedicate a separate client node and configure its connection speeds to the server through Dummynet.
 (a)
(a) |
 (b)
(b) |
 (c)
(c) |
 (d)
(d) |
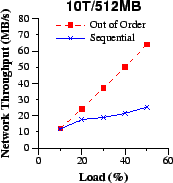
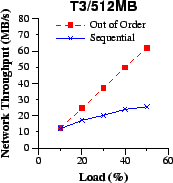
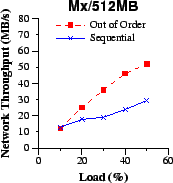
| Figure 8: We compare the network throughput of the unmodified (sequential) and Circus (out-of-order) download server implementations at increasing system loads using 512MB file requests. We consider the client link capacity to be equal to (a) 1.5Mbit/s, (b) 10Mbit/s, (c) 44.7Mbit/s, and (d) a mix of 20% 1.5Mbit/s, 60% 10Mbit/s and 20% 44.7Mbit/s. The out-of-order approach more than doubles the network throughput at higher loads. The higher the network throughput, the better the system throughput as well. | |
|
(a) |
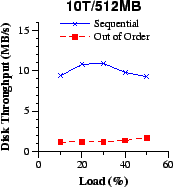 (b)
(b) |
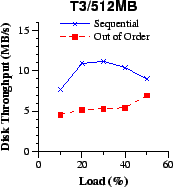 (c)
(c) |
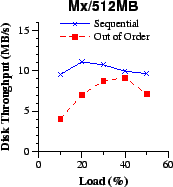 (d)
(d) |
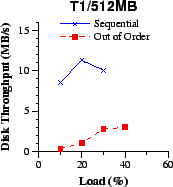
| Figure 9: At low and moderate loads, the disk throughput with out-of-order transfers remains roughly equal to the transfer rate of the most demanding individual client across different client link rates (a-d). With sequential transfers, the disk is highly utilized and becomes a bottleneck as shown in Figure 8 (lower disk throughput is better for a given network throughput). | |
From recent studies in peer-to-peer network systems it has been found
that 20-30% of the users have downstream network links less than
1Mbit/s, about 80-90% have downstream links less than 10Mbit/s, and
the remaining 10-20% have links that exceed 10Mbit/s
[28]. In accordance with the above results and the fact that
broadband user population tends to increase over time, we specified
three groups of clients with 1.544 Mbit/s (T1), 10 Mbit/s (we call it
10T), and 44.736 Mbit/s (T3). We experiment with each of these groups
separately, and also with a mixed workload (Mx) where 20% of the
users are of type T1, 60% are of type 10T, and the remaining 20% are
type T3. In several cases, we focus on 50%-50% mixes of two client
groups. We allow each experiment to
run for between
![]() hour and
hour and
![]() hour, depending on the network link capacity of the
clients. Measurements start after one or more initial download
requests complete. Each experiment is repeated until the half-length
of the 95% confidence interval of the measured network throughput
lies within 5% of the estimated mean value across different
trials.
hour, depending on the network link capacity of the
clients. Measurements start after one or more initial download
requests complete. Each experiment is repeated until the half-length
of the 95% confidence interval of the measured network throughput
lies within 5% of the estimated mean value across different
trials.