


Next:Optimistic
DAFS Up:Direct
Access File Systems Previous:Direct
Access File Systems
DAFS
DAFS clients use lightweight RPC to communicate file requests to servers.
In direct read or write operations the client provides virtual addresses
of its source or target memory buffers and data transfer is done using
RDMA operations. RDMA operations are always issued by the server. In this
paper we focus on server structure and I/O performance.
Server
Design and Implementation
This section describes our current DAFS server design and implementation
using existing FreeBSD kernel interfaces with minor kernel modifications.
Our prototype DAFS kernel server follows the event-driven state transition
diagram of Figure 1.
Events are shown in boldface letters. The arrow under an event points to
the action taken when the event occurs. The main events triggering state
transitions are recv-done (a client-initiated transfer is done),
send-done
(a server-initiated transfer is done) and bio-done (a block I/O
request from disk is done).
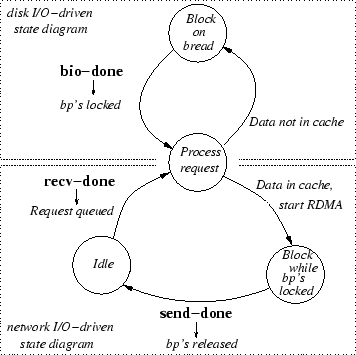 |
Figure 1:Event-Driven DAFS Server. Blocking
is possible with existing interfaces.
Important design characteristics of the DAFS server in the current implementation
are:
-
The server uses the buffer cache interface to do disk I/O (i.e. bread(),
bwrite(),
etc.). This is a zero-copy interface that can be used to lock buffers (pages
and their mappings) for the duration of an RDMA transfer. RDMA transfers
take place directly from or to the buffer cache.
-
RDMA transfers are initiated in the context of RPC handlers but proceed
asynchronously. It is possible that an RDMA completes long after the RPC
that initiated it has exited. Buffers involved in RDMA need to remain locked
for the duration of the transfer. RDMA completion event handlers unlock
those buffers and send an RPC reply if needed.
-
The kernel buffer cache manager is modified to register/deregister buffer
mappings with the NIC on-the-fly, as physical pages are added or removed
from buffers. This ensures that the NIC never takes translation miss faults
and pages are wired only for the duration of the RDMA.
Each of the network and disk events has a corresponding event handler that
executes in the context of a kernel thread.
-
recv-done is raised by the NIC and triggers processing of an incoming
RPC request. For example, in the case of read or write operations the handler
may initiate block I/O with the file system using bread(). After
data is locked in buffers (hereafter referred to as bp's) in the
buffer cache, RDMA is initiated and the bp's remain locked for the
duration of the transfer.
-
send-done is raised by the NIC to notify of completion of a server-initiated
(read or write) RDMA operation. The handler releases locks (using brelse())
on bp's involved in the transfer and sends out an RPC response.
-
bio-done is raised by the disk controller and wakes up a thread
that was blocking on disk I/O previously initiated by bread(). This
event is currently handled by the kernel buffer cache manager in biodone().
The server forks multiple threads to create concurrency in order to deal
with blocking conditions. Kernel threads are created using an internal
rfork()
operation. One of the threads is responsible for listening for new transport
connections while the rest are workers involved in data transfer. All transport
connections are bound to the same completion group. Message arrivals on
any transport connection generate recv-done interrupts which are
routed to a single interrupt handler associated with the completion group.
When the handler is invoked, it queues the incoming RPC request, notes
the transport that was the source of the interrupt, and wakes up a worker
thread to start processing. After parsing the request, a thread locks the
necessary file pages in the buffer cache using bread(), prepares
the RDMA descriptors and issues the RDMA operations. The RPC does not wait
for RDMA completion. A later send-done interrupt (or successfull
poll) on a completed RDMA transfer descriptor starts clean up and release
of resources that the transfer was tying up (i.e. bp locks held
on file buffers for the duration of the transfer), and sends out the RPC
response. Threads blocking on those resources are awakened. Event-driven
design requires that event handlers be quick and not block between events.
Our current server design deviates from this requirement due to the possibility
of blocking under certain conditions:
-
Need to wait on disk I/O initiated by bread(). It is possible to
avoid using the blocking bread() interface by initiating asynchronous
I/O with the disk using getblk() followed by strategy().
We opted against this solution in our early design since disk event delivery
is currently disjoint from network event delivery, complicating event handling.
Integrating network and disk I/O event delivery in the kernel is discussed
in Sections 4.1
and 4.2.
-
Locking a bp twice by the same kernel thread or releasing a bp
from a thread other than the lock owner causes a kernel panic (Section
4.4).
Solutions are to (a) defer any request processing by a thread while past
transfers it issued are still in progress, to ensure that a bp is
always released by the lock owner and a thread never locks the same bp
twice, or (b) modify the buffer cache so that these conditions no longer
cause a kernel panic. To avoid wider kernel changes in the current implementation,
we do (a). (b) is addressed in Section 4.4.
An important concern when designing an RDMA-based server is to minimize
response latency for short transfers and maximize throughput for long transfers.
In the current design, notification of incoming messages is done via interrupts
and notification of server-initiated transfer completions via polling.
Short transfers using RDMA are expected to complete within the context
of their RPC request. In this way, the RPC response immediately follows
RDMA completion, minimizing latency. Throughput is maximized for longer
transfers by pipelining them as their RDMA operations can be concurrently
progressing. The low cost of DAFS RPC, the efficient event notification
and delivery mechanism, and the absence of copies due to RDMA help towards
low response latency. Maximum throughput is achievable even for small block
sizes (as shown in Section 5)
assuming the client is throwing requests at the server at a sufficiently
high rate (i.e. doing prefetching using asynchronous I/O). The DAFS kernel
server presently runs over the Emulex cLAN [8]
and GN 9000 VI/IP [9]
transports and is currently being ported to Mellanox InfiniBand [10].
Next:Optimistic
DAFS Up:DAFS
Previous:DAFS
Kostas Magoutis 2001-12-03